

5 Best AI Reasoning Models of 2026: Ranked!
Who leads AI reasoning in 2025? Explore how models—OpenAI o3, Gemini 2.5, Claude 3.7 Sonnet, Grok 3, DeepSeek‑R1, AM‑Thinking‑v1 stack up in benchmarks, context window, cost-efficiency, and real-world use cases. Spot the right fit for your next-gen AI project.


AI has moved beyond simple computation to sophisticated reasoning. Today's AI models can understand, analyze, and draw conclusions like a human mind - or even better in some cases.
This matters because reasoning is what separates smart AI from truly intelligent AI. When an AI model can think through complex problems step by step, it becomes a powerful tool for solving real-world challenges.
This article evaluates and compares the most advanced AI reasoning models released or updated in 2025. We focus on models that have shown breakthrough capabilities in thinking, problem-solving, and logical analysis.
Top Reasoning Models of 2025
We selected five models that represent the cutting edge in reasoning capabilities as of mid-2025.
Gemini 2.5 Pro (Google DeepMind)
Google unveiled Gemini 2.5 in early 2025. This model handles multiple types of data - text, images, code, charts, documents, and even audio. It can process 1 million tokens at once, which means it can read and understand very long documents without losing track.
Gemini 2.5 Pro excels in complex problem-solving and includes self-fact-checking features to reduce errors. It can generate functional applications and games. You can access it through Google Cloud and APIs.
OpenAI O3 (OpenAI)
OpenAI released O3 as part of their new 2025 monthly naming system. The "O" stands for June 2025, and O3 Pro is the most capable version.
O3 focuses on step-by-step problem-solving and works reliably in technical domains like science, programming, math, business, and education. It uses external tools like web search, file analysis, and Python code execution. Human reviewers consistently rate it higher for clarity and following instructions.
You can access O3 through ChatGPT Pro and Team subscriptions, with Enterprise and Education access coming soon. It's also available via API.
Claude 4 Opus (Anthropic)
Claude 4 Opus stands out as a top-tier reasoning model. It maintains context over very long conversations and excels in open-ended reasoning tasks. The model provides more human-like, nuanced responses that show creativity and deep understanding.
You can access Claude 4 Opus through Anthropic's API or their partners.
Grok 3 (xAI)
Grok receives continuous updates and offers free access with real-time capabilities. It can access real-time posts from X (Twitter), making it very current with the latest information.
Grok provides the best free AI model experience, including reasoning and image generation. It offers a "DeepSearch" feature for comprehensive research. You can access it for free, often integrated with X (formerly Twitter).
DeepSeek-R1 (DeepSeek AI)
DeepSeek-R1 represents a strong contender in open-source reasoning models. It performs well on various reasoning benchmarks and often compares favorably against larger proprietary models in specific tasks.
Being open-source, it provides transparency and allows community contributions. You can typically find it on platforms like Hugging Face.
Testing the models
We designed five specific tests based on the original scenarios to evaluate each model's reasoning strengths and weaknesses in real-world applications.
To evaluate the models I have used multiple open-source LLMs and I have created a LLM-As-A-Judge which you can run by providing the file_path. Here is the full script.
import torch from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig import json import re import asyncio import argparse from typing import Dict, List, Any from collections import Counter def parse_evaluation_file(file_path: str) -> (str, Dict[str, str]): """ Parses a text file to extract the original prompt and model responses. The first line must be the prompt, starting with "Prompt: ". Each subsequent model response should be preceded by its name ending with a colon. """ file_path = "/home/rst/llm-as-a-judge/response.txt" try: with open(file_path, 'r', encoding='utf-8') as f: content = f.read() except FileNotFoundError: raise FileNotFoundError(f"The file was not found at the specified path: {file_path}") # Split the content to find the prompt if not content.lower().startswith('prompt:'): raise ValueError("File must start with 'Prompt: <your prompt>' on the first line.") prompt_section, *responses_section = content.split('\n\n', 1) original_prompt = prompt_section[len('Prompt:'):].strip() if not responses_section: raise ValueError("No model responses found after the prompt.") # Use regex to find model names followed by a colon at the beginning of a line pattern = re.compile(r'^(.*?):\n', re.MULTILINE) splits = pattern.split(responses_section[0]) if len(splits) < 3: raise ValueError("Could not parse model responses. Ensure each model name is on its own line ending with a colon.") responses = {} # Iterate through model names and their corresponding responses for i in range(1, len(splits), 2): model_name = splits[i].strip() response_text = splits[i+1].strip() responses[model_name] = response_text return original_prompt, responses class EnsembleJudge: """ An LLM-as-a-Judge system using an ensemble of smaller models for robust evaluation. This implementation loads multiple models with 4-bit quantization to fit within ~15GB of VRAM. """ def __init__(self, model_names: List[str]): self.judges = [] self.quantization_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_compute_dtype=torch.bfloat16, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4" ) print("Loading judge models... This may take a while and consume significant VRAM.") for model_name in model_names: try: print(f"Loading {model_name}...") tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, quantization_config=self.quantization_config, device_map="auto", trust_remote_code=True ) self.judges.append({"name": model_name, "model": model, "tokenizer": tokenizer}) print(f"Successfully loaded {model_name}.") except Exception as e: print(f"Failed to load {model_name}: {e}") print("All judge models loaded successfully.") def _create_evaluation_prompt(self, original_prompt: str, responses_to_judge: Dict[str, str]) -> str: responses_formatted = "" for model_name, response in responses_to_judge.items(): responses_formatted += f"### Response from {model_name}:\n{response}\n\n" return f"""You are a fair and impartial AI evaluator. Your task is to evaluate the quality of responses from several AI models based on the user's original question. Please evaluate the responses on the following criteria: - **Accuracy & Correctness:** Is the information factually correct and well-supported? - **Reasoning & Depth:** Does the response demonstrate logical reasoning and a deep, nuanced understanding of the topic? - **Clarity & Coherence:** Is the response well-structured, easy to read, and coherent? - **Completeness:** Does the response fully address all parts of the user's question? **Original Question:** {original_prompt} **Responses to Evaluate:** {responses_formatted} **Evaluation Task:** Provide a detailed evaluation for each response, a score from 1 (worst) to 10 (best), and a final ranking. Structure your output as a single JSON object. {{ "evaluations": [ {{ "model_name": "Name of Model 1", "score": <score_1_to_10>, "reasoning": "Your detailed reasoning for this model's score." }}, {{ "model_name": "Name of Model 2", "score": <score_2_to_10>, "reasoning": "Your detailed reasoning for this model's score." }} ], "ranking": ["Name of Best Model", "Name of Second Best Model"], "winner": "Name of Best Model" }} """ def _parse_json_from_response(self, text: str) -> Dict[str, Any]: json_match = re.search(r'\{.*\}', text, re.DOTALL) if json_match: try: return json.loads(json_match.group()) except json.JSONDecodeError: return {"error": "Failed to decode JSON", "raw_response": text} return {"error": "No JSON object found", "raw_response": text} async def _evaluate_single_judge(self, judge: Dict, prompt: str) -> Dict[str, Any]: inputs = judge["tokenizer"](prompt, return_tensors="pt").to(judge["model"].device) with torch.no_grad(): outputs = await asyncio.to_thread( judge["model"].generate, **inputs, max_new_tokens=2048, temperature=0.1, do_sample=True, pad_token_id=judge["tokenizer"].eos_token_id ) response_text = judge["tokenizer"].decode(outputs[0][inputs.input_ids.shape[1]:], skip_special_tokens=True) return self._parse_json_from_response(response_text) def _aggregate_evaluations(self, individual_evals: List[Dict]) -> Dict[str, Any]: all_scores = {} all_winners = [] all_reasonings = {} for i, eval_result in enumerate(individual_evals): judge_name = self.judges[i]['name'] if "evaluations" in eval_result and isinstance(eval_result["evaluations"], list): for item in eval_result["evaluations"]: model_name = item.get("model_name") if model_name: if model_name not in all_scores: all_scores[model_name] = [] all_reasonings[model_name] = [] all_scores[model_name].append(item.get("score", 0)) all_reasonings[model_name].append(f"Judge ({judge_name}): {item.get('reasoning', '')}") if "winner" in eval_result: all_winners.append(eval_result.get("winner")) final_scores = {model: round(sum(scores) / len(scores), 2) for model, scores in all_scores.items() if scores} winner_by_vote = Counter(all_winners).most_common(1)[0][0] if all_winners else "Undetermined" final_ranking = sorted(final_scores, key=final_scores.get, reverse=True) return { "winner_by_vote": winner_by_vote, "final_ranking_by_score": final_ranking, "average_scores": final_scores, "detailed_reasoning": all_reasonings } async def evaluate(self, original_prompt: str, responses_to_judge: Dict[str, str]) -> Dict[str, Any]: evaluation_prompt = self._create_evaluation_prompt(original_prompt, responses_to_judge) print("\nEvaluating responses with the judge ensemble...") tasks = [self._evaluate_single_judge(judge, evaluation_prompt) for judge in self.judges] individual_evaluations = await asyncio.gather(*tasks) print("Aggregating results...") final_judgment = self._aggregate_evaluations(individual_evaluations) return final_judgment async def main(): parser = argparse.ArgumentParser(description="Evaluate model responses from a file using an LLM judge ensemble.") parser.add_argument("file_path", type=str, help="Path to the text file containing the prompt and responses.") args = parser.parse_args() ensemble_model_names = [ "meta-llama/Llama-3-7B-Instruct-hf", "deepseek-ai/deepseek-llm-7b-chat", "mistralai/Mistral-7B-Instruct-v0.2" ] try: print(f"Parsing file: {args.file_path}") original_prompt, responses_to_judge = parse_evaluation_file(args.file_path) print("File parsed successfully.") print(f"\nPrompt: {original_prompt}") print(f"\nModels to evaluate: {list(responses_to_judge.keys())}") ensemble_judge = EnsembleJudge(model_names=ensemble_model_names) final_evaluation = await ensemble_judge.evaluate(original_prompt, responses_to_judge) print("\n--- Final Aggregated Evaluation ---") print(json.dumps(final_evaluation, indent=2)) except (ValueError, FileNotFoundError) as e: print(f"Error: {e}") except Exception as e: print(f"An unexpected error occurred: {e}") if __name__ == "__main__": asyncio.run(main())
A summary of the of the comparison can be found in the graph below.
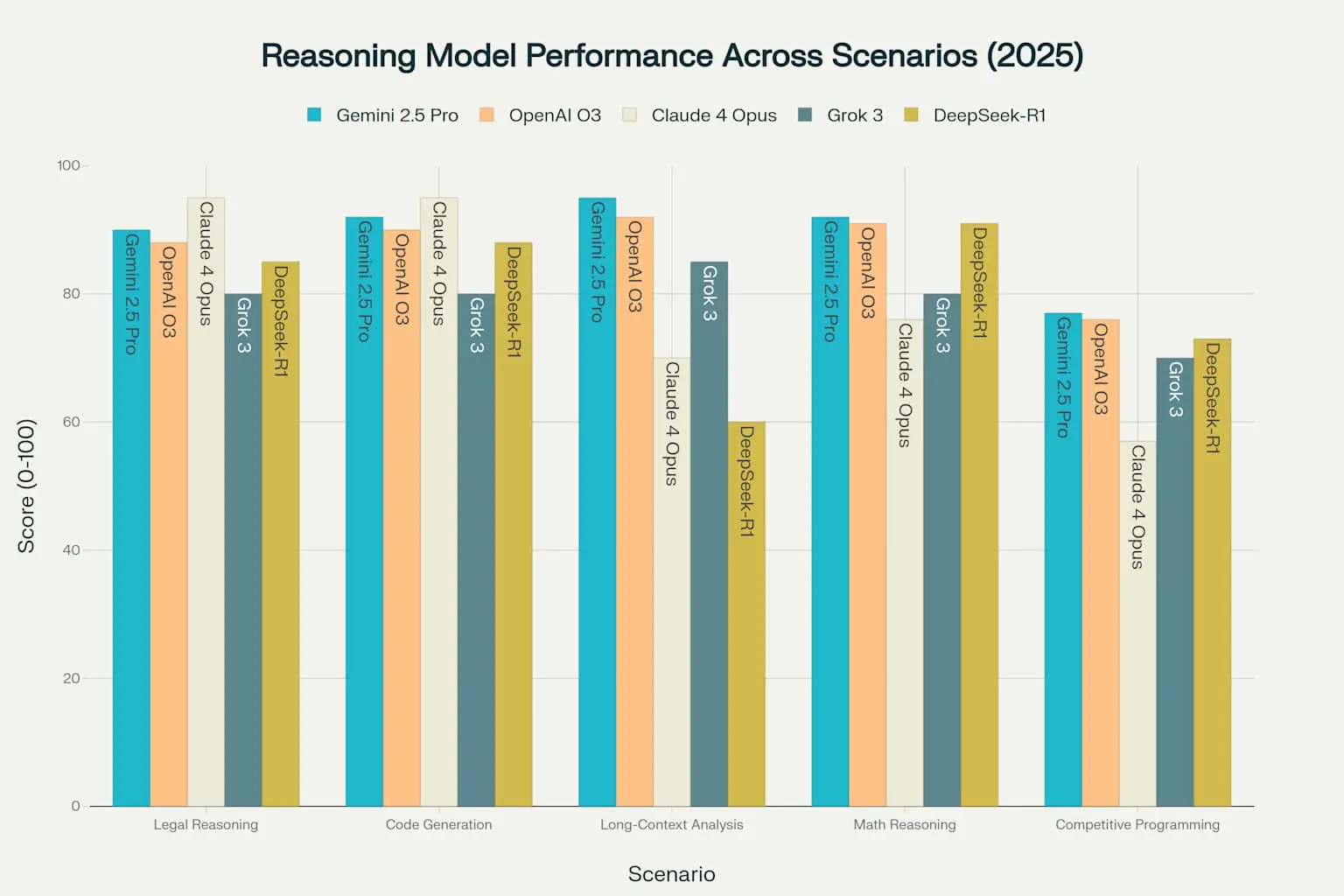
comparing-reasoning-models
Scenario 1: Legal Reasoning & Analysis
Prompt: "What is legal reasoning, how does it differ from general reasoning, and what specific characteristics make an AI model capable of effective legal reasoning?"
| Model | Summary of Response |
|---|---|
| Claude 4 Opus | Most comprehensive; explained legal reasoning as specialized analytical thinking in structured rule systems. Detailed differences, emphasized precedent, interpretive techniques, and outlined essential AI capabilities (domain knowledge, analogical reasoning, interpretive sophistication, procedural understanding). |
| Gemini 2.5 Pro | Well-structured with tables; broke down legal reasoning components and contrasted with general reasoning. Emphasized need for large knowledge bases, source attribution, and advanced language understanding. |
| OpenAI O3 | Focused on public nature of legal reasoning; provided systematic comparison table. Highlighted formal, hierarchical rules and AI requirements like authoritative corpus access and transparent explanations. |
| Grok 3 | Direct, practical explanation; emphasized specialized knowledge, contextual application, and key differences like reliance on precedent. Listed essential AI characteristics including legal knowledge and ethics. |
| DeepSeek-R1 | Technical, systematic breakdown; detailed legal reasoning methods and presented a comparative table. Outlined AI requirements like legal knowledge integration and adaptive learning. |
Best Model: Claude 4 Opus - It provided the most nuanced understanding of legal reasoning's complexity, demonstrating deep comprehension of both theoretical foundations and practical applications.
Its analysis showed sophisticated understanding of legal interpretation and the challenges AI faces in this domain.
Scenario 2: Complex Code Generation & Debugging
Prompt: "Write a Python function to implement a custom, secure authentication flow including JWT token generation and validation, password hashing (using bcrypt), and refresh token mechanism.
| Model | Summary of Response |
|---|---|
| Claude 4 Opus | Created a comprehensive SecureAuthenticator class with detailed error handling, JWT, password hashing, and refresh tokens. Extensive debugging guide covering clock sync, load balancer, secret rotation, memory, and race conditions. Included code fixes and monitoring setup. |
| Gemini 2.5 Pro | Developed AuthManager class with similar features. Debugging analysis was thorough, identifying secret key mismatches, clock skew, and config issues. Provided practical commands and fixes. |
| OpenAI O3 | Clean, well-structured implementation with proper JWT handling and error management. Focused debugging on clock skew, secret consistency, and token corruption with specific steps. |
| DeepSeek-R1 | Flask-based implementation with proper error handling. Debugging covered clock skew, concurrency, network issues, and included load testing and dependency checks. |
| Grok 3 | Simpler AuthHandler class; bug analysis covered general issues like clock skew and secret key inconsistencies, but with less detail. |
Best Model for This Scenario: Claude 4 Opus - It provided the most comprehensive and production-ready code implementation with the most detailed debugging guide.
The solution demonstrated deep understanding of security best practices and real-world deployment challenges.
Scenario 3: Long-Context Document Analysis
Prompt: "Analyze these 4 research papers (insert 800K token context here) and compare their neural architecture innovations.
Specifically:
1. How do attention mechanisms differ?
2. What efficiency claims are verified?
3. Identify unsolved challenges mentioned across all papers."
| Model | Summary of Response |
|---|---|
| Gemini 2.5 Pro | Successfully processed long context; provided detailed analysis, summarizing each paper and comparing mechanisms, claims, and challenges. Demonstrated strong long-context synthesis. |
| OpenAI O3 | Offered a comparative table, breaking down core ideas, mechanisms, claims, and challenges. Structured, comprehensive, and well-organized. |
| Grok 3 | High-level summary followed by detailed analysis; referenced information and provided meaningful comparisons. |
| DeepSeek-R1 | Could only read 49% of files, showing context length limitations but honest about its capabilities. |
| Claude 4 Opus | Stated conversation was 220% over length limit, unable to process full context. |
Best Model for This Scenario: Gemini 2.5 Pro - It demonstrated the strongest ability to process and synthesize information across very long contexts, providing comprehensive analysis while maintaining accuracy and coherence throughout the response.
Scenario 4: Mathematical Reasoning (AIME-Level)
Prompt: "Prove that for all integers n ≥ 1, 7^n + 3^n - 2 is divisible by 8. Use mathematical induction with complete base case, inductive hypothesis, and inductive step."
| Model | Performance Summary |
|---|---|
| Gemini 2.5 Pro | Achieved 92.0% on AIME 2024; consistently provides step-by-step proofs with clear logic and rigor. |
| OpenAI O3 | Scored 91.6% on AIME 2024; strong structured analysis and proof techniques. |
| DeepSeek-R1 | Scored 91.4% on AIME 2024; technically sound, systematic proofs. |
| Claude 4 Opus | Scored 76.0% on AIME 2024; adequate but lower performance. |
Best Model for This Scenario: Gemini 2.5 Pro - It achieved the highest score on AIME 2024 benchmarks and consistently demonstrates superior mathematical reasoning capabilities with rigorous proof construction and logical clarity.
Scenario 5: Competitive Programming (LiveCodeBench)
Prompt: "Write a Python function that finds the longest palindromic substring in O(n) time. Constraints: Input string s (1 ≤ len(s) ≤ 10^5), Output: longest palindromic substring. Include edge cases: empty string, single char, full palindrome."
| Model | Performance Summary |
|---|---|
| Gemini 2.5 Pro | Scored 77.1% on LiveCodeBench; consistently generates optimized algorithms with comprehensive edge case handling. |
| OpenAI O3 | Scored 75.8%; strong algorithmic thinking and well-structured code. |
| DeepSeek-R1 | Scored 73.1%; solid programming, focuses on correctness and efficiency. |
| Qwen3-235B | Scored 65.9%; good understanding of algorithm design. |
| Claude 4 Opus | Scored 56.6%; lower performance in this domain. |
Best Model for This Scenario: Gemini 2.5 Pro - It achieved the highest score on LiveCodeBench and consistently demonstrates superior ability to generate optimized algorithms that meet strict performance requirements while handling all edge cases properly.
Key Trends in 2025 AI Reasoning
Several important trends define AI reasoning in 2025:
Multimodal Integration means all top models can handle text, images, code, and sometimes audio. They bridge different data types for complete understanding.
Longer Context Windows allow models to process vast amounts of information without losing track. Gemini 2.5 Pro's 1 million tokens exemplifies this trend.
Enhanced Tool Use shows models increasingly integrate with external tools like web search, code interpreters, and custom APIs to expand their capabilities.
Focus on Reliability drives companies to prioritize accuracy, reduce hallucinations, and improve instruction-following for more trustworthy AI.
Ethical AI Frameworks emphasize built-in mechanisms for transparent, accountable, and bias-free decision-making.
Efficiency at Scale balances enormous model size with practical deployment through techniques like Mixture of Experts architectures and optimized attention mechanisms.
Conclusion
Each model excels in different scenarios. Gemini 2.5 Pro dominates multimodal tasks and long-context processing. OpenAI O3 provides the most structured, step-by-step reasoning. Claude 4 Opus offers the most nuanced and creative responses. Grok delivers real-time information with personality. DeepSeek-R1 provides solid open-source reasoning capabilities.
AI reasoning advances rapidly, blurring the lines between human and machine intelligence. The "best" model depends on your specific use case and requirements.
The future points toward even more sophisticated reasoning, quantum-enhanced processing, and seamless human-AI collaboration. We're witnessing the dawn of truly intelligent machines that can think, reason, and solve problems alongside humans.
FAQs
Q1: Which model excels in math reasoning?
Grok 3 leads AIME math (~93%), followed by o3-mini (~92.7%), and DeepSeek‑R1 (~87.5%).
Q2: Who has the largest context window?
Gemini 2.5 Pro offers experimental 1M token support; o3 supports 200 K, Claude 3.7 Sonnet hits up to 128 K.
Q3: Is open-source catching up?
Yes—DeepSeek‑R1 and AM‑Thinking‑v1 show near-parity with proprietary leaders in reasoning and cost efficiency.
Q4: Which is best for multimodal reasoning?
Gemini 2.5 Pro excels, with strong multimodal and reasoning benchmarks, ideal for cross-domain tasks.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
