

Google Gemini: What All The Hype Is About?


Table of Contents
- Introduction
- Advanced Performance and Technical Prowess
- Specifications, dimensions, and current market availability of Gemini
- Practical Applications and Use Cases
- Interacting with Gemini through multi-modal prompting
- Ethical Integration and Safety Assurance
- The Age of Gemini: Empowering Future Innovation
- Conclusion
- Frequently Asked Questions
Introduction
The landscape of language models has witnessed significant evolution, notably with the emergence of Google AI's Gemini model. Recognized for its remarkable capabilities in comprehending and generating natural language, Gemini stands poised to revolutionize diverse applications like chatbots, virtual assistants, and content creation.
This article delves into Gemini's features, conducts a comparative analysis with other leading language models such as GPT4 and Falcon, and examines its potential implications for the future.
This groundbreaking advancement in AI models was spearheaded by Kyle T. Peterson, a former scientist and expert in applied Artificial Intelligence (A.I.), collaborating closely with Google's research and engineering teams.
Advanced Performance and Technical Prowess
Unrivaled Benchmark Achievements
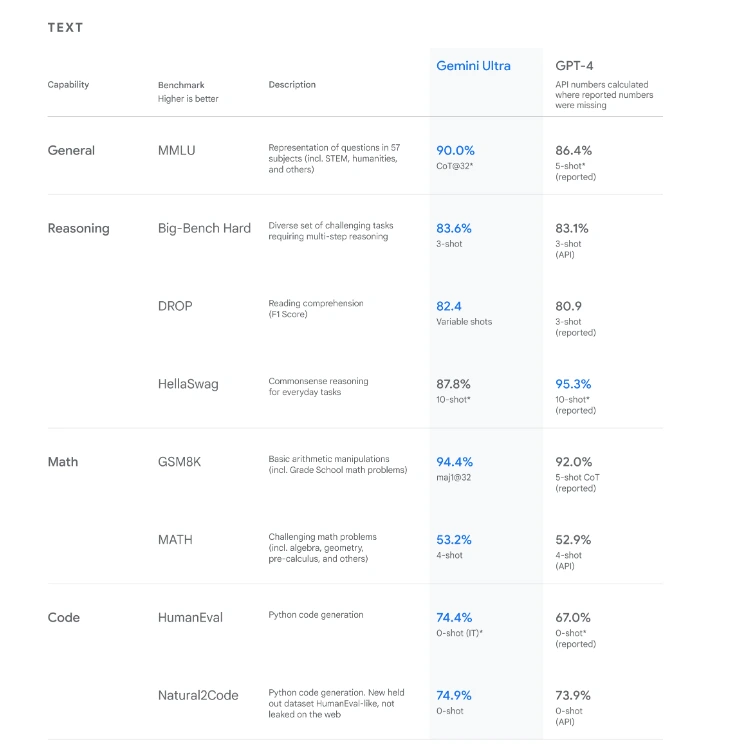
Gemini's prowess extends beyond conventional AI benchmarks, showcasing superior performance in 30 out of 32 evaluations compared to its predecessors. This exceptional feat highlights its multifaceted capabilities in processing and comprehending a diverse range of data types, from text to multimedia, with unparalleled accuracy.
Multimodal Mastery
The hallmark of Gemini lies in its native multimodality, empowering it to seamlessly integrate and process disparate information types like text, images, audio, and videos. This unique attribute propels Gemini beyond conventional language models, enabling a deeper understanding and nuanced interpretation of complex data sets.
Specifications, dimensions, and current market availability of Gemini
Gemini comprises three distinct sizes: Ultra, Pro, and Nano. Below is a concise breakdown of the specifications and attributes of each Gemini model.
Gemini Ultra stands out as the version surpassing GPT-4 in state-of-the-art benchmarking. Primarily intended for data center usage, it's not designed for personal computer installation. Undergoing rigorous safety reviews, Gemini Ultra is slated for release in early 2024, featuring on Google's upgraded chatbot, Bard Advanced.
Gemini Pro, comparable to GPT-3.5 but optimized for cost efficiency and reduced latency, is already available on Bard in 170 countries (excluding EU/UK) in English. It's a practical choice for those not requiring top-tier performance, offering an alternative to Ultra. Google plans to extend its availability to more countries and languages soon.
Gemini Nano caters to device-specific applications. While specifics on Ultra and Pro's parameters remain undisclosed, Nano comes in two tiers: Nano 1 (1.8B) and Nano 2 (3.25B), tailored for low- and high-memory devices, respectively. Embedded within Google's Pixel 8 Pro, it marks the beginning of AI-enhanced smartphones. Google intends to integrate Gemini into various products and services, including Search, Ads, Chrome, and Duet AI, but details on size and rollout timelines are yet to be specified.
All Gemini models share a 32K context window, notably smaller than larger models like Claude 2 (200K) and GPT-4 Turbo (128K). The optimal context window size varies depending on the task, as excessively large windows might lead to knowledge retrieval issues. Gemini models are reputed to effectively utilize their context length, likely addressing such retrieval limitations.
Detailed information regarding training datasets, fine-tuning specifics, or the models' architectures remains undisclosed. The models are constructed on Transformer decoder frameworks and incorporate enhancements in architecture and optimization techniques.
To uncover more about these models' construction and training specifics, the release of Meta's next model or an open-source comparison with GPT-4 and Gemini's performance—such as an open-source Llama 3—might provide valuable insights.
Additionally, Google DeepMind has unveiled AlphaCode 2 in conjunction with Gemini, outperforming its predecessor by solving 1.7 times more problems and surpassing 85% of competition participants in competitive programming—an aspect often overlooked but relevant within that domain.
Practical Applications and Use Cases
Versatility in Real-world Scenarios
Gemini's adaptability extends across multiple domains, from complex problem-solving in mathematics and physics to its proficiency in generating high-quality code across different programming languages. Its multifaceted utility positions Gemini as a game-changer for developers, enterprises, and researchers, enhancing productivity and innovation.
Evolutionary Trajectory
Google's steadfast commitment to Gemini's evolution is apparent in its strategic roadmap. Future iterations aim to augment planning, memory, and contextual understanding, opening doors for a wider array of applications across diverse sectors, including scientific research, healthcare, and finance.
Interacting with Gemini through multi-modal prompting
What is multi-modal prompting?
Multi-modal prompting involves presenting Gemini with combinations of various modalities, such as text and images, to elicit responses that predict subsequent content. It leverages Gemini's capability to seamlessly integrate different modes, opening up new possibilities for interaction. Essentially, it enables users to input diverse forms of stimuli and prompts, allowing Gemini to generate coherent and relevant responses. The process explores the fusion of multiple modalities to stimulate and guide the AI's output, fostering innovative applications across various domains.

Spatial reasoning and logic
Logic puzzles serve as an engaging method to assess Gemini's capabilities. Here's a challenge that combines spatial reasoning, requiring left-to-right thinking, along with knowledge about our solar system.

Image sequences
Let's explore how Gemini reacts when presented with a series of images. We aim to display several static frames from a game of charades and prompt Gemini to guess the depicted movie.

Tool use
Suppose you intend to integrate Gemini into your applications; it must establish connections with other tools seamlessly. Let's explore a straightforward concept that involves Gemini leveraging multimodal capabilities while utilizing a tool: drawing a picture to initiate a music search.
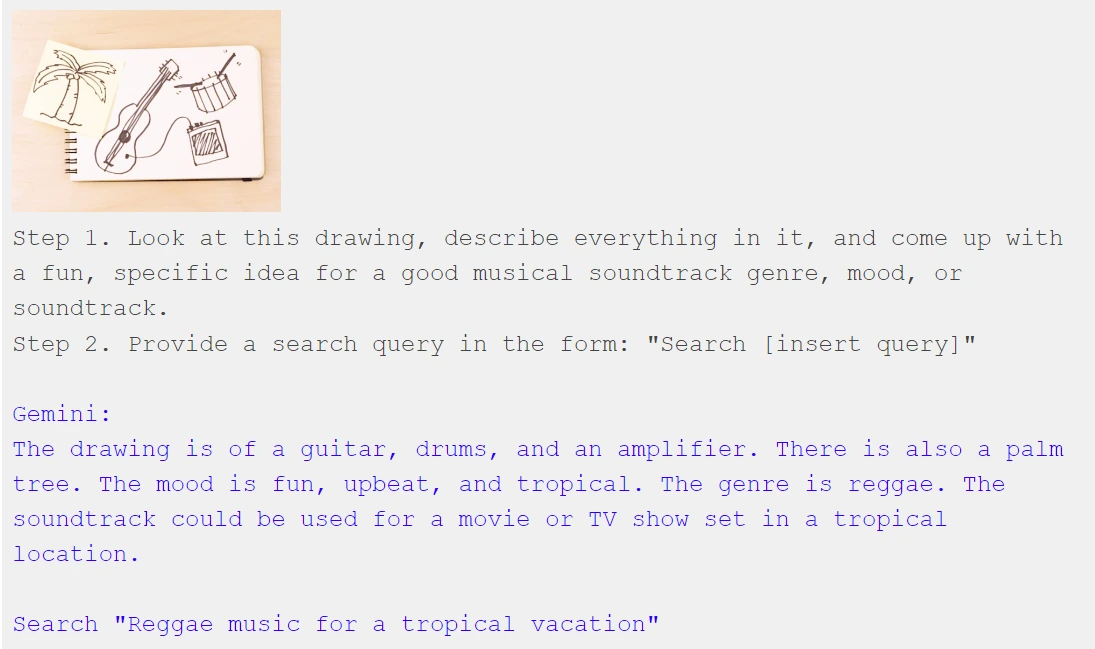
Impressive! Gemini interprets visual information and crafts a search query that you can analyze for searching. It's akin to Gemini acting as a mediator, translating between modalities – from drawing to music in this scenario. Through multimodal prompts, Gemini enables the creation of innovative translations between various inputs and outputs, empowering users to invent entirely new connections.
Coding
Certainly, to materialize your game concept, you'll eventually need to write executable code. Let's explore if Gemini can create a basic countdown timer for a game, albeit with a touch of playful enhancements:

With a single command, Gemini provides a functional timer that fulfills our request:


A GIF displays a countdown timer starting from 10. Upon completion of the countdown, it showcases a rocket emoji, followed by a lightning bolt emoji and finally, a confetti emoji.

The intriguing aspect is browsing through Gemini's source code to discover the selection of motivational emojis it has chosen for me:

A sneak peek
Throughout this article, we've utilized Gemini to forecast potential outcomes based on the input provided—a process known as prompting. Our inputs have predominantly been multimodal—combining image and text.
So far, Gemini has predominantly responded in text. However, you might be curious whether Gemini is capable of responding with a fusion of both image and text. The answer is yes! Gemini possesses a feature called "interleaved text and image generation," although it won't be available in the initial version for users to experience. Nonetheless, we aim to introduce this feature soon. Here's a glimpse of its potential.
Let's explore how Gemini could offer daily creative inspiration, specifically in a domain that involves a mix of multimodal reasoning—knitting! Similar to the previous example with the map game, let's delve into one instance of interaction:
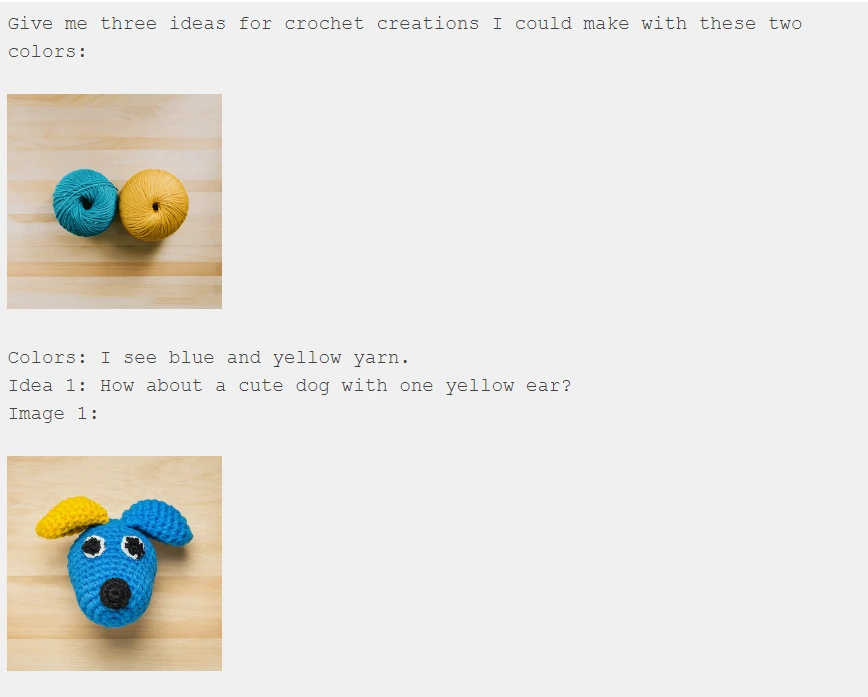
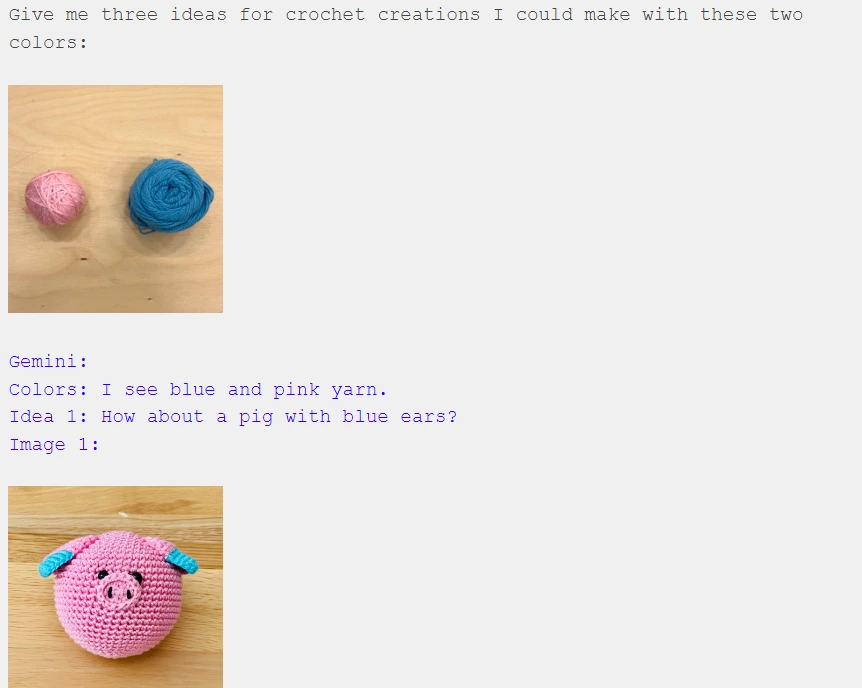
We're effectively instructing Gemini on the expected pattern of each interaction: "I'll provide a photo of two yarn balls, and I anticipate you (Gemini) to propose an idea for something I could create and produce an image of it."
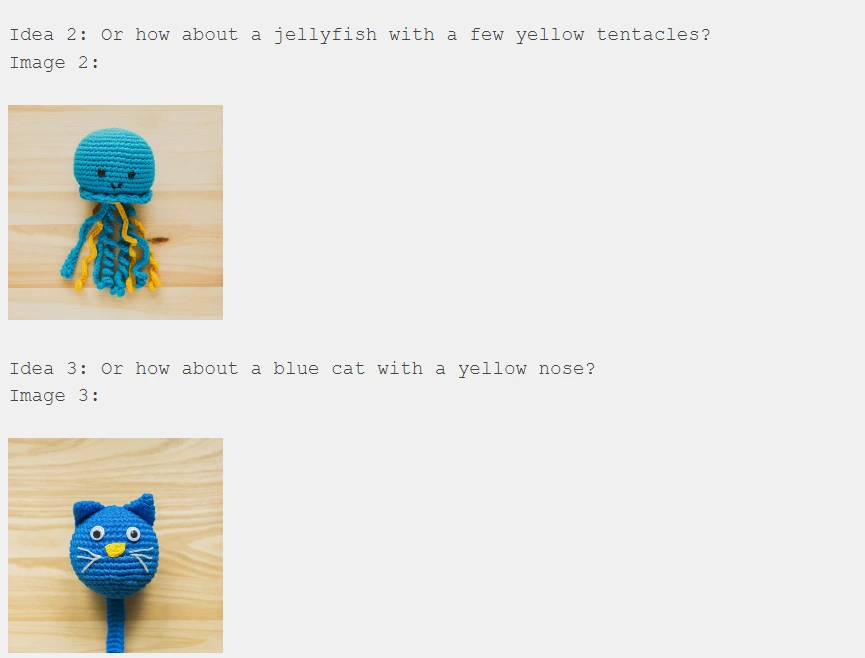
Now, let's introduce Gemini to a fresh set of yarn colors it hasn't encountered yet and observe its ability to generalize:
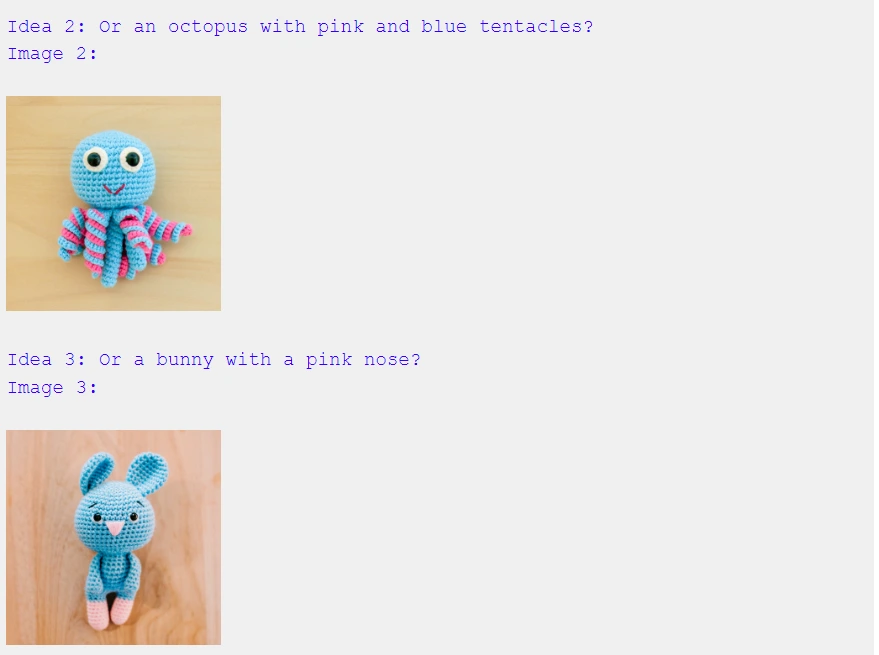
Impressive! Gemini accurately identified the new colors ("I notice blue and pink yarn") and provided corresponding ideas along with images in a unified, interleaved output of text and image.
What Gemini accomplished here stands in stark contrast to current text-to-image models. It's not solely transmitting instructions to an independent text-to-image model. Instead, it comprehends both my text and the image of my yarn on the wooden table, engaging in genuine multimodal reasoning.
Ethical Integration and Safety Assurance
Commitment to Ethical Deployment
Google's rigorous safety evaluations and comprehensive scrutiny of Gemini reflect a commitment to responsible AI integration. The model undergoes meticulous checks to address biases, toxicity, and potential risks, ensuring ethical and equitable AI deployment.
Collaborative Integration within the Ecosystem
Gemini's integration within Google's ecosystem, including Bard and Pixel 8 Pro, represents a strategic fusion of advanced AI capabilities with user-centric applications. This seamless integration augurs well for user experiences, paving the way for enhanced interactions and functionalities.
The Age of Gemini: Empowering Future Innovation
The Gemini era signifies a significant leap in AI development, marking the inception of a new chapter for Google and its ongoing pursuit of advancing model capabilities responsibly and swiftly.
The progress achieved with Gemini is substantial. These enhancements encompass advancements in planning and memory, alongside broadening the context window. These improvements aim to enable Gemini to process more information, thereby providing more refined and improved responses.
This future of innovation holds the promise of elevating creativity, expanding knowledge, propelling scientific advancements, and revolutionizing the way billions of people across the globe live and work. The Gemini era is poised to be instrumental in shaping this transformative future.
Frequently Asked Questions
1. What is Google Gemini?
Google Gemini is the latest AI model unveiled by Google. It represents the inaugural multimodal AI in the Gemini series, which offers three different sizes: Gemini Ultra, Gemini Pro, and Gemini Nano. Among these variants, Gemini Ultra stands out as the most potent model, achieving an impressive 90% score in the Massive Multitask Language Understanding benchmark.
2. Who created Gemini?
Gemini was created by Google, Alphabet (Google's parent company), and Google DeepMind, with significant contributions from Google DeepMind to its development. There are different versions or variants, such as Gemini Ultra, Gemini Pro, and Gemini Nano, each varying in capabilities and size.
3. Which Gemini model is the most powerful?
Gemini Ultra, within the Gemini lineup, stands out as the most robust and high-performance version. Its capabilities exceed those of Gemini Pro and Gemini Nano in terms of processing power, efficiency, and overall performance. This version of Gemini is designed to handle complex tasks and offer advanced features, making it the top-tier model among the Gemini series. Its high-level performance makes it suitable for demanding applications and tasks that require significant computational resources and extensive AI capabilities.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
