

Insights And Best Practices For Building and Deploying Computer Vision Models


Building and deploying computer vision (CV) models require a deep understanding of both the theoretical aspects of computer vision and the practical challenges of developing robust and efficient systems.
Computer Vision Engineers play a critical role in this process, leveraging their expertise to design, train, and deploy CV models that can analyze and understand visual data.
These engineers encounter numerous lessons and insights that shape their approach to building and deploying CV models.

Figure: Diving into Computer Vision
This blog explores some of the critical lessons learned from experienced Computer Vision Engineers, offering valuable insights into the best practices, common pitfalls, and emerging trends in the field.
By understanding these lessons, aspiring CV engineers can navigate the complex landscape of CV model development and deployment, improving their chances of success in this rapidly evolving domain.
Factors Affecting the Computer Vision Models
Building robust and accurate computer vision models relies on understanding the various factors that can impact their performance.
Computer vision has rapidly advanced in recent years, enabling applications ranging from autonomous vehicles to medical imaging.
However, achieving optimal results requires careful consideration of several key factors that affect the performance and reliability of these models. The major affecting parameters for computer vision models include:
- Data pre-processing and augmentation
- Developing Efficient Computer Vision Models
- Optimizing hyperparameters
- Managing data quality and quantity
- Deployment of Computer Vision Models
- Deployment of Computer Vision Models
- Model conversion, deployment setup, testing, and maintenance
- Continuous Learning and Improvement
In the below section, we have discussed all the major affecting parameters for computer vision models in detail.
- Data pre-processing and augmentation
Data preprocessing and augmentation are vital steps in achieving high performance in computer vision tasks.
Data preparation is crucial in the computer vision pipeline, significantly impacting the model's performance. While tasks like resizing images, normalizing pixel values, and converting image formats are fundamental, there are other important considerations based on the problem being addressed.
In the below section, we have discussed various factors considered during data processing.

Figure: Data Pre-processing
i) Data Cleaning
Thoroughly examine the dataset to identify issues such as duplicate images, mislabeled samples, and low-quality images. Tools like fastdup can assist in identifying and managing incorrect labels, outliers, and corrupted images.
Mislabeled data can cause a loss of models generalization ability.
ii) Handling Varying Aspect Ratios
Resizing images to a fixed size can distort the aspect ratio and affect the model's ability to recognize objects. Techniques such as padding images or random cropping during data augmentation can be employed to maintain the original aspect ratio while providing input of consistent dimensions.
iii) Domain-Specific Preprocessing
For specific tasks, domain-specific preprocessing can lead to improved model performance. In medical imaging, for example, techniques like skull stripping and intensity normalization are commonly used to remove irrelevant background information and normalize tissue intensities across different scans.
iv) Data Augmentation
Data augmentation is crucial for enhancing the size and diversity of the dataset, leading to improved model generalization.
Data augmentation strategies for computer vision models can include basic augmentations such as rotation, flipping, and brightness/contrast adjustments. These techniques are computationally efficient and often provide substantial improvements in model performance.
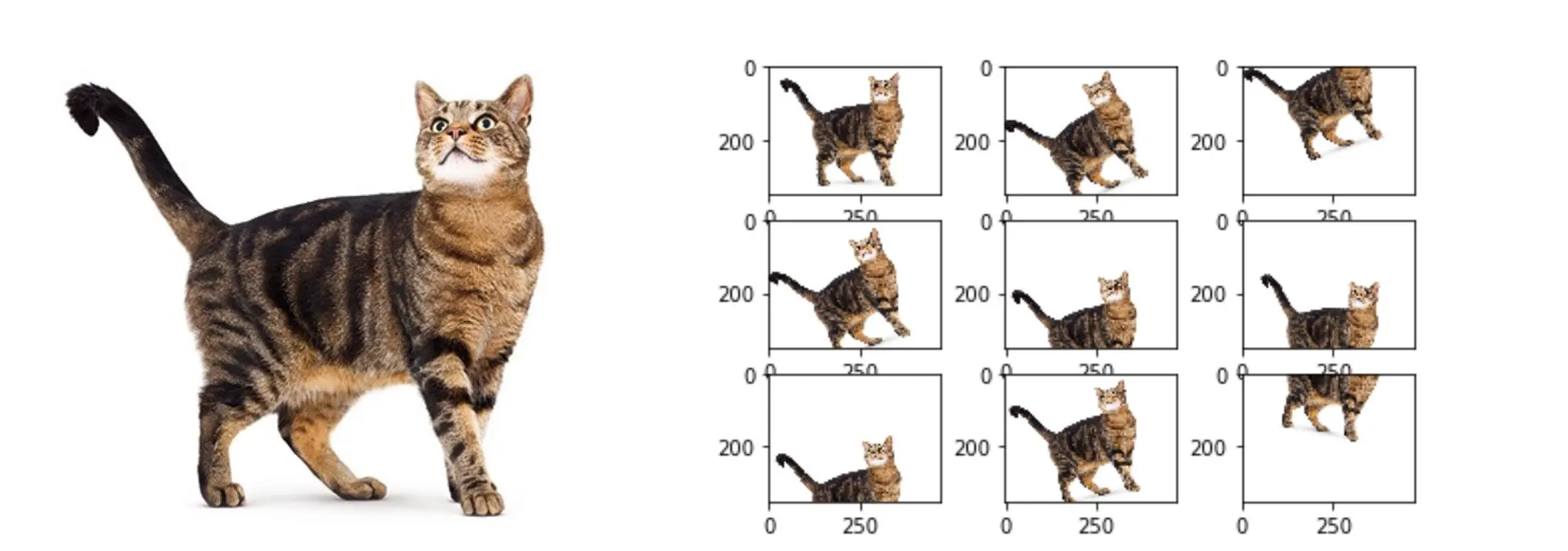
Figure: Data Augmentation
Advanced augmentation methods like MixUp and CutMix can be employed in more complex tasks or datasets with limited diversity. These techniques combine multiple images or labels to encourage the model to learn more robust features.
While advanced augmentation techniques can enhance model performance, it is important to prioritize acquiring a diverse dataset whenever possible.
v) Annotation and labeling
Accurate annotations and labels are crucial for supervised learning. Utilize annotation tools like Labellerr to create bounding boxes, masks, or critical points. These user-friendly tools support various annotation formats for export.
Figure: Data Annotation and Bounding Box
2. Developing Efficient Computer Vision Models
Building an accurate and efficient computer vision (CV) model involves several important considerations. One key consideration is selecting the appropriate model architecture for the specific task.
i) Selecting the Right Architecture
There are various popular architectures available, such as Convolutional Neural Networks (CNNs), region-based convolutional networks (R-CNN), and You Only Look Once (YOLO).
YOLO is often preferred for real-time object detection tasks due to its speed and efficiency.
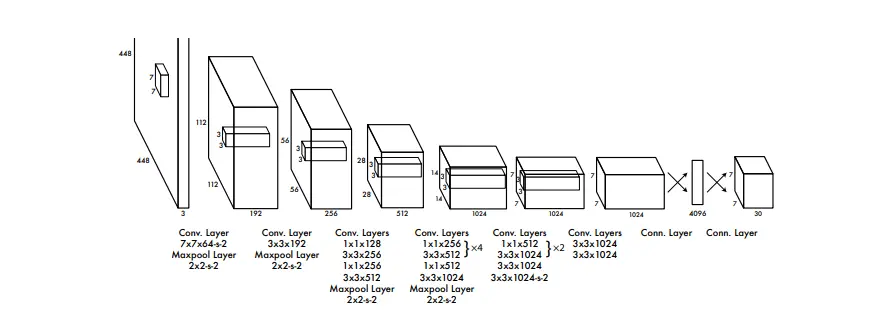
Figure: Architecture For YOLO
It strikes a balance between detection accuracy and computational resources. However, YOLO may not be optimal when dealing with small objects or achieving high precision is crucial.
In such cases, models like Faster R-CNN or RetinaNet may be more suitable, even though they have slower processing times. The right architecture is essential for achieving CV model performance trade-offs.
ii) Key Takeaways
In starting a new object detection project, begin with utilizing a pre-trained model as a baseline and fine-tune it using the target dataset.
Specifically, consider using YOLOv5 or YOLOv7 due to their advantageous combination of speed and accuracy. I recommend leveraging Ultralytics's repository, which offers a quick setup process and a user-friendly interface.
Fine-tuning the pre-trained model facilitates faster convergence and improved performance, particularly when the new dataset shares similarities with the dataset used for pre-training.
This approach allows for knowledge transfer from the pre-trained model, leading to more efficient training and better results in object detection tasks.
3. Optimizing hyper-parameters
Achieving optimal model performance relies on effectively optimizing hyper-parameters. However, extensive hyper-parameter searches may not always be feasible due to limited infrastructure.
In such situations, a practical and hands-on approach, combining experience, intuition, and experimentation, can still lead to effective hyper-parameter optimization.
Several hyper-parameters, including learning rate, batch size, number of layers, and architecture-specific parameters, require optimization when working with visual models. Here are some practical tips to optimize these hyper-parameters without relying on exhaustive searches:
i) Learning rate
Start with a typical value and monitor the learning curve during training. Adjust the learning rate if the model converges slowly or exhibits erratic behavior. Utilize learning rate schedulers to enhance convergence, such as reducing the learning rate on a plateau.
Further, a general trend I have observed is that when the learning curve achieved has a large number of oscillations, try reducing the learning rate.
ii) Batch size
Choose a batch size that maximizes GPU memory utilization without causing out-of-memory errors. Larger batch sizes can aid generalization but may increase training time.
If memory limitations arise, consider using gradient accumulation to simulate larger batch sizes. We prefer using the batch size in the power of 2, i.e. 2^x.
iii) Architecture-specific parameters
Begin with a well-established architecture and fine-tune it on your dataset. Adjust the number of layers or other architecture-specific parameters if over-fitting or under-fitting occurs. Remember that adding more layers increases model complexity and computational requirements.
iv) Regularization techniques
Experiment with weight decay, dropout, and data augmentation to improve model generalization. These techniques help prevent over-fitting and enhance performance on the validation set.
Techniques like cutout and Weight Decay (L2 Regularization) can also be used.
4. Managing data quality and quantity
Ensuring reliable CV models necessitates effectively managing data quality and quantity. A systematic approach to curating, maintaining, and expanding datasets proves invaluable and includes the following processes and tools:
i) Fine-tuning
Fine-tuning and Transfer Learning have become integral techniques in my CV model workflow. Utilizing pre-trained models can save time and enhance performance, especially when working with limited data.
ii) Layer freezing and learning rate scheduling
During fine-tuning, it is recommended to freeze the initial layers of the pre-trained model and only update later layers to adapt to the specific task.
Depending on the similarity between the pre-trained model's task and the target task, one may also employ differential learning rates, assigning smaller rates to earlier and higher rates to later layers. This allows for fine-grained control over layer updates.
iii) Choosing a robust backbone
Having a pre-trained model as a backbone, for instance, ResNet, EfficientNet, and MobileNet architectures are the most reliable and adaptable backbones for various CV tasks. These architectures balance accuracy and computational efficiency, making them suitable for various applications.
iv) Selecting the best computer vision model
As there is a varied category of CV tasks, each task works best utilizing a different model. Below we discuss some of these tasks in detail-
1. Facial recognition and analysis
Facial recognition models have evolved in accuracy and efficiency, finding applications in security systems and smartphone unlocking. While CNNs are common for smaller-scale facial recognition, scaling to a more significant number of faces requires more advanced approaches.
Instead of using a standard classification CNN, employing deep metric learning techniques like triplet loss allows models to learn more distinct feature representations of faces. These embeddings are often combined with vector databases (e.g., ElasticSearch, Pinecone) for efficient indexing and retrieval.
2. Object detection
Object detection models find utility in retail, manufacturing, and transportation industries for product detection, defect identification, and vehicle tracking tasks.
Real-time object detection advancements like SSD and YOLO enable deployment in time-sensitive applications like robotics and autonomous vehicles.
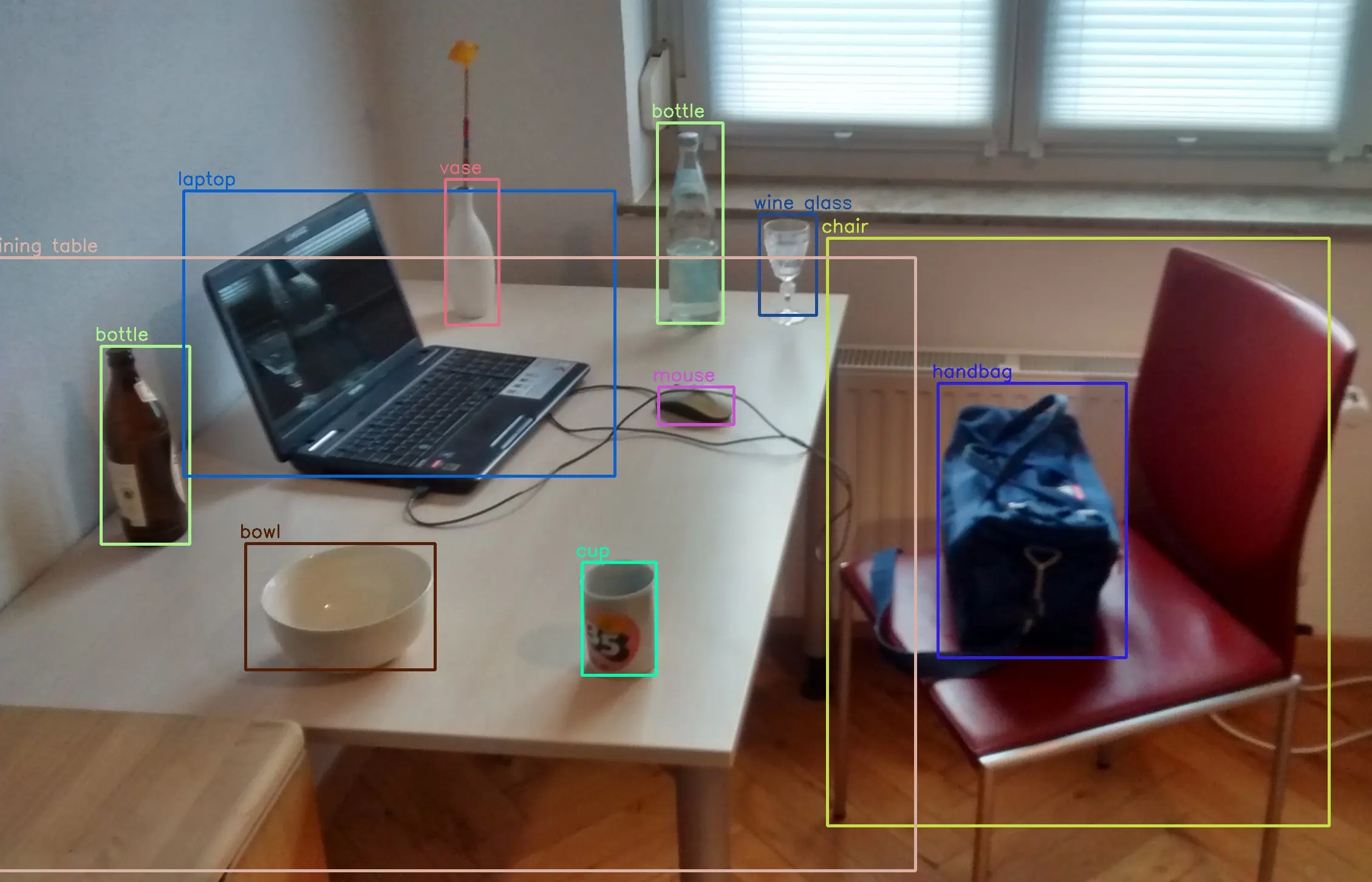
Figure: Object Detection
Further, re-framing the problem as a classification or segmentation task can be advantageous in some scenarios.
For example, cropping regions of interest and processing them separately can improve results and computational efficiency when dealing with high-resolution images or complex scenes.
For example, Consider a quality control process in a manufacturing assembly line where high-resolution images capture fabricated vehicle parts eg. gates, bonut, steering-wheel, etc.
Employing an object detection model on the entire image may be computationally expensive and less accurate due to the small component size. In such cases, segmenting the regions of interest first can lead to better results and computational efficiency.
3. Image Classification
Generally, when I face a problem with Image classification, I begin by using a MobineNetV2 architecture with the top layer as false. This is so because the deeper layers are used for feature extraction from images, and the later layer tends to classify.
Thus I suggest adding custom head layers trained on the dataset provided.
For more information, refer to the ML Beginner's Guide to Build Car Damage Detection AI Model.
5. Deployment of Computer Vision Models
The deployment options for computer vision models include cloud, on-premise, and edge. Each option has its advantages and disadvantages, and the deployment choice depends on the project's specific requirements. Let's take a closer look at each option.
i) Cloud Deployment
Cloud deployment has revolutionized how computer vision models are deployed, providing advantages such as flexibility, scalability, and simplified maintenance.
The preferred stack for cloud deployment typically includes TensorFlow or PyTorch for model development, Docker for containerization, and sometimes Kubernetes for orchestration. Built-in cloud services are utilized for infrastructure management, automatic scaling, and monitoring.
Figure: Cloud Deployment
Common challenges and how to avoid them:
- Underestimating resource usage: Properly estimating required resources (CPU, GPU, memory, etc.) is crucial when deploying to the cloud to prevent performance issues. Monitoring the application and utilizing auto-scaling features provided by cloud platforms help adjust resources as needed.
- Cost management: Keeping track of cloud expenses is crucial to avoid unexpected costs. Implementing cost monitoring and alerts, utilizing spot instances when possible, and optimizing resource allocation help minimize expenses.
- Embracing managed services: Utilizing the managed services provided by cloud platforms can save time and effort by handling tasks like model deployment, scaling, monitoring, and updating. This allows more focus on improving the model and application instead of managing infrastructure.
ii) On-premise deployment
On-premise solutions offer increased control over data security and reduced latency but may require more resources for setup and maintenance.
It is ideal for organizations with strict security policies or those dealing with sensitive data (e.g., medical imaging or records) that cannot be stored or processed in the cloud.
On-premise deployment is recommended if there are prerequisites regarding data security.
iii) Edge deployment
Deploying models on edge devices like smartphones or IoT devices enables low-latency processing and reduced data transmission costs. Edge deployment is particularly useful in scenarios that require real-time processing, such as autonomous vehicles or robotics.
However, edge deployment may have computational resources and model size limitations, requiring optimization techniques to fit within these constraints.
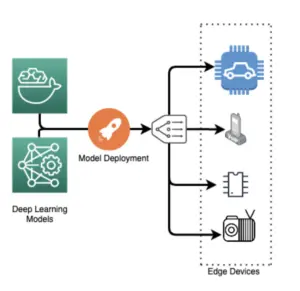
Figure: Edge Deployment Model
Several frameworks and platforms support efficient and optimized deployment when deploying machine learning models at the edge. Here are some popular frameworks used for edge deployment of machine learning models:
- PyTorch Mobile: PyTorch Mobile is a framework that enables the deployment of PyTorch models on mobile and embedded devices. It allows developers to convert PyTorch models into a mobile-optimized format and provides a runtime for efficient on-device inference.
- ONNX Runtime: The Open Neural Network Exchange (ONNX) Runtime is an open-source framework that provides high-performance inferencing across multiple platforms, including edge devices. ONNX Runtime supports various deep learning frameworks, including TensorFlow and PyTorch, and enables the deployment of models in ONNX format.
- Edge TPU: Edge TPU (Tensor Processing Unit) is a hardware accelerator designed by Google for edge computing and machine learning inference. It works with TensorFlow Lite and allows fast and energy-efficient model execution on edge devices. Edge TPU is commonly used in applications such as image and object recognition, voice processing, and natural language understanding.
- NVIDIA Jetson: NVIDIA Jetson is a family of embedded computing platforms designed for AI and machine learning applications at the edge. Jetson platforms, such as Jetson Nano, Jetson Xavier NX, and Jetson AGX Xavier, provide high-performance GPUs and dedicated AI accelerators for running deep learning models efficiently.
- Intel OpenVINO: Intel OpenVINO (Open Visual Inference and Neural Network Optimization) is a toolkit that enables the deployment of trained models on Intel hardware, including CPUs, integrated GPUs, and dedicated neural network accelerators.
These frameworks provide the tools, libraries, and optimizations to deploy machine learning models at the edge efficiently.
They offer hardware acceleration, model conversion utilities, and runtime environments tailored for edge devices, enabling real-time and low-latency inferencing on resource-constrained devices.
The choice of framework depends on factors such as the target hardware platform, model requirements, compatibility with existing infrastructure, and developer preferences.
6. Ensuring scalability, security, and performance
i) Scalability
When deploying computer vision models, it is crucial to ensure that the deployment solution can handle increasing workloads and user demands. Successful scalability in CV model deployment involves key factors such as load balancing and auto-scaling.
1. Load balancing
Distributing the workload across multiple servers or instances helps prevent bottlenecks and maintains system responsiveness. Implementing a load balancer to distribute incoming requests to multiple instances of the deployed model significantly improved performance during peak usage times in a computer vision project.
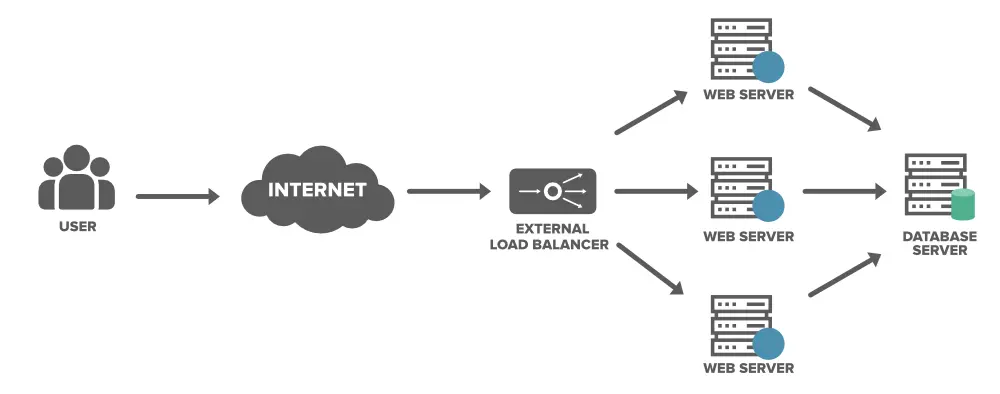
Figure: Load balancing
2. Auto-scaling
Cloud providers often offer auto-scaling features that automatically adjust resources based on demand. Configuring auto-scaling rules ensures optimal performance and cost efficiency.
Setting up auto-scaling based on predefined metrics helped maintain smooth performance during periods of fluctuating demand without manual intervention in a cloud deployment.
ii) Security
Safeguarding sensitive data and complying with industry regulations is a top priority when deploying computer vision models. A default stack and checklist have been developed to ensure the security of deployed systems, which includes:
- Encryption: Implementing encryption at rest and in transit protects sensitive data. AES-256 is a preferred solution for encryption at rest, while HTTPS/TLS is typically relied upon for data in transit.
- Access controls: Setting up role-based access controls (RBAC) restricts access to the system based on user roles and permissions, ensuring that only authorized personnel can access, modify, or manage the deployed models and associated data.
- Federated learning (when applicable): Implementing federated learning in situations where data privacy is a concern allows models to learn from decentralized data without transferring it to a central server, protecting user privacy.
- Secure model storage: Storing trained models securely using a private container registry or encrypted storage prevents unauthorized access or tampering.
iii) Performance
Optimizing model performance ensures that computer vision models deliver efficient and accurate results. Key aspects include reducing latency, increasing throughput, and minimizing resource usage.
In addition to the learnings shared above, here are some performance-related learnings gathered over the years:
iv) Hardware acceleration
Utilizing hardware-specific optimizations maximizes performance. TensorRT can be used to optimize TensorFlow models for deployment on NVIDIA GPUs, while OpenVINO can be employed for Intel hardware. Dedicated AI accelerators like Google's Edge TPU or Apple's Neural Engine can also be considered for edge deployments.
v) Batch processing
Increasing throughput by processing multiple inputs simultaneously, leveraging the parallel processing capabilities of modern GPUs. Finding a balance between larger batch sizes and memory requirements is important for optimal performance.
vi) Profiling and monitoring
Continuously profiling and monitoring the model's performance helps identify bottlenecks and optimize the system. Profiling tools like TensorFlow Profiler provide insights into the model's execution and areas for improvement.
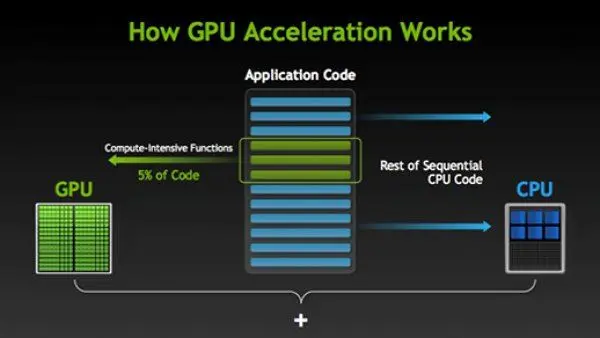
Figure: Hardware accelerations using GPU
7. Model conversion, deployment setup, testing, and maintenance
i) Model conversion
Converting trained models into a suitable format for the chosen deployment platform is essential for ensuring compatibility and efficiency. Formats like TensorFlow Lite, ONNX, and Core ML are commonly used depending on the target hardware and deployment scenario.
Here's a brief overview of when each format is preferred:
- TensorFlow Lite: This format is preferred for deploying models on edge devices like Android smartphones or IoT devices. TensorFlow Lite is optimized for resource-constrained environments and is compatible with a wide range of hardware, including GPUs, CPUs, and TPUs.
- ONNX: The Open Neural Network Exchange (ONNX) format is often chosen when working with different deep learning frameworks like PyTorch or TensorFlow. ONNX provides a seamless way to transfer models between frameworks and is supported by various runtime libraries like ONNX Runtime, ensuring efficient execution across multiple platforms.
- Core ML: The Core ML format is preferred for deploying models on Apple devices like iPhones, iPads, or Macs. Core ML is specifically designed for Apple hardware and leverages the power of the Apple Neural Engine.
ii) Deployment setup
Configuring the deployment environment is crucial for smooth operation. Tools such as Docker for containerization, FastAPI for creating REST APIs, and built-in cloud tools for monitoring and CI/CD are preferred for deployment setup.
Over the years, various tools and technologies have been explored to streamline the process, and the following stack is currently preferred:
- Docker: Docker is relied upon for containerization, enabling the packaging of the model and its dependencies into a portable, self-contained unit. This simplifies deployment, reduces potential conflicts, and ensures consistent performance across different platforms.
- FastAPI: FastAPI creates a lightweight, high-performance REST API for serving models. It is easy to work with, supports asynchronous programming, and provides built-in validation and documentation features.
- Built-in cloud tools: Built-in cloud tools are utilized for monitoring and CI/CD tasks. Depending on the specific requirements of the computer vision project, specialized tools like Seldon or BentoML may be considered for model serving and management. However, the mentioned stack has proven to be robust and flexible.
iii) Model Testing
Thorough testing in the deployment environment is essential to ensure your model performs as expected under various conditions, including varying loads and data inputs.
Over time, a systematic approach to computer vision testing and model management in production has been developed, commonly called Test Suits.
i) What Are Test Suites?
Comprehensive test suites are created to cover different aspects of the deployment, including functionality, performance, and stress tests.
These test suites verify the model's behavior with diverse data inputs, validate response times, and assess its ability to handle high-load scenarios.
Tools like pytest are used for writing and managing test cases and are integrated into the Continuous Integration (CI) pipeline for automatic execution.
Some lessons learned from past experiences include:
- Insufficient testing coverage: It is important to cover all relevant test scenarios, including edge cases, to detect potential issues before they impact users.
- Ignoring performance metrics: Tracking and analyzing key performance metrics help identify bottlenecks and optimize the deployment. Monitoring various aspects is necessary to identify issues.
- Deploying changes without a rollback strategy: A rollback strategy allows for quick reversion to the previous version in case of unexpected issues. Canary deployments are employed to introduce updates or changes to models gradually.
iv) Maintainance of Deployed Models
Regularly monitoring model performance, updating it with new data, and addressing emerging issues or bugs are crucial. Establishing a monitoring and logging system helps track model performance metrics such as accuracy, latency, and resource utilization.
Additionally, implementing a robust alerting mechanism notifies relevant stakeholders in case of performance degradation or unexpected issues. Here are some commonly used tools:
- TensorBoard: Specifically designed for TensorFlow, TensorBoard provides visualization and monitoring capabilities for models during training and deployment. It helps analyze model performance, visualize network architecture, and track custom metrics related to computer vision tasks.
- ELK Stack (Elasticsearch, Logstash, Kibana): The ELK Stack is a widely used log management and analytics solution for collecting, storing, and analyzing logs from computer vision models and deployment environments. Kibana, the visualization component, allows the creation of custom dashboards for monitoring and troubleshooting.
- Built-in cloud tools: For example, AWS CloudWatch, a monitoring service provided by Amazon, enables the collection, visualization, and analysis of metrics and logs from applications and infrastructure.
8. Continuous Learning and Improvement
Continuous learning and improvement are essential even after deploying your computer vision model, as it marks the beginning of a new phase in many ways.
To stay current and enhance your models, the following practices should be considered:
i) Monitoring for model drift
Continuously monitor your model's performance and retrain it with fresh data to account for changes in the underlying data distribution. Techniques like online learning allow the model to learn incrementally from new data without starting from scratch. Ensemble learning, which combines multiple models, can also increase resilience against drift.
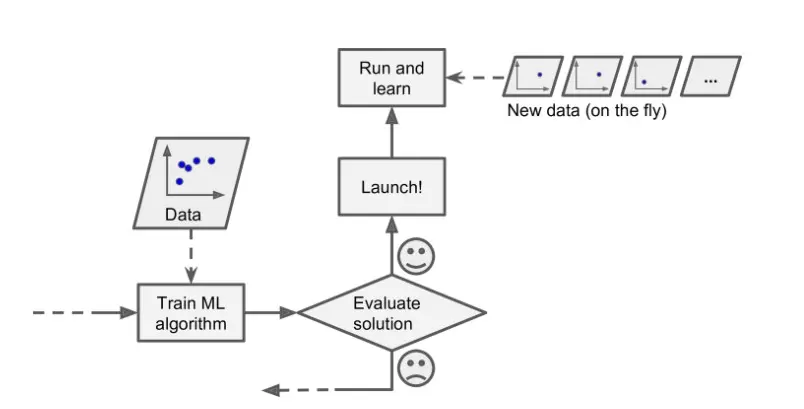
Figure: Online Learning
ii) Testing and validation
Conduct rigorous testing using various validation techniques such as cross-validation and holdout sets to ensure the reliability and robustness of your models. Employ model explainability tools like SHAP and LIME to gain insights into predictions and identify biases or vulnerabilities.
iii) Keeping up with the latest research
Stay informed about the latest advancements in computer vision research and incorporate relevant findings into your models. Regularly participate in conferences, read research papers, and engage with the computer vision community to stay updated on new techniques and best practices. Here are some valuable resources I recommend:
- Labeller Blogs: Provides valuable resources covering both theoretical and practical concepts.
- Medium articles: A comprehensive information collection on various Machine Learning related topics.
- TowardsAI: Blogs and learning resources for beginner to advanced research in Machine Learning.
- towardsdatascience.com: Offers comprehensive how-to guides. theaisummer.com
- Kaggle: A competitive site for Machine Learning enthusiasts.
Conclusion
In conclusion, building and deploying computer vision models require a deep understanding of various factors that can impact their performance. By addressing these factors, developers can improve their models' accuracy, efficiency, and generalization capabilities.
Data pre-processing and augmentation play a crucial role in achieving high performance in computer vision tasks. Techniques like handling varying aspect ratios, domain-specific preprocessing, and data augmentation help improve model generalization and robustness.
It is important to prioritize acquiring a diverse dataset whenever possible to represent real-world conditions better.
Choosing the right model architecture is another important consideration. Different architectures like CNNs, R-CNN, and YOLO have their strengths and weaknesses, and the choice depends on the specific task requirements.
YOLO is often preferred for real-time object detection due to its speed and efficiency, while other models like Faster R-CNN or RetinaNet may be more suitable for tasks requiring high precision or dealing with small objects.
Optimizing hyperparameters is crucial for achieving optimal model performance. While extensive hyperparameter searches may not always be feasible, a practical and hands-on approach combined with experience and experimentation can lead to effective optimization.
Parameters like learning rate, batch size, number of layers, and regularization techniques should be carefully tuned.
Managing data quality and quantity is essential for reliable computer vision models. Thorough data preprocessing, accurate annotation and labeling, and data augmentation techniques help improve the dataset's quality and diversity.
Fine-tuning and transfer learning using pre-trained models can also enhance performance, especially with limited data.
Deployment of computer vision models can be done in the cloud, on-premise, or at the edge, depending on specific requirements. Each option has its advantages and disadvantages, and the choice should consider factors like flexibility, scalability, data security, latency, and computational resources.
Ensuring scalability, security, and performance in deployed computer vision systems is crucial. Load balancing, auto-scaling, encryption, access controls, and secure model storage are key considerations for scalability and security.
Optimizing model performance through hardware acceleration, batch processing, profiling, and monitoring helps reduce latency, increase throughput, and minimize resource usage.
By understanding and implementing these insights and best practices, aspiring computer vision engineers can navigate the complex landscape of CV model development and deployment, increasing their chances of success in this rapidly evolving field.
Frequently Asked Questions (FAQ)
- What are Computer Vision Models?
A computer vision model refers to a software application trained to identify and detect objects within images. Through a training process, the model gains the ability to recognize specific objects by analyzing a collection of images containing those objects.
2. How to deploy a computer vision model?
Deploying a computer vision model can be achieved through various methods. One common approach involves deploying and serving the model using API endpoints, where the model is accessed through REST or RPC APIs.
These APIs provide a standardized way for different systems to communicate and interact with the deployed model. Another option is deploying the machine learning model directly at the edge, bringing the model closer to the data source or device where it will be utilized.
3. What are the 3 major steps in the deployment Process?
The deployment process typically encompasses three primary stages: development, testing, and monitoring. These stages involve the activities of creating and refining the software, evaluating its functionality through testing, and continuously monitoring its performance once it is deployed.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
