

Boost Your Pre-Training Models with Flan-UL2

Pre-training models are one of the most crucial developments in the field of machine learning, which has made impressive strides over time. Pre-training models entail training a model on a big dataset and then honing it for a particular task using a smaller dataset.
These pre-training models, however, frequently experience the issue of domain-specificity, meaning that they work best with data and configurations that are similar to those they were pre-trained on.
Researchers have created Flan-UL2, a unified framework for pre-training models that is universally effective across datasets and setups, to solve this issue. With minimal fine-tuning, Flan-UL2 is intended to offer a reliable and scalable method for pre-training models that can excel on a variety of tasks and datasets.
We will delve into the specifics of Flan-UL2 in this blog, including its benefits, features, and operational aspects. We will also go over the tests and findings that show how successful Flan-UL2 is in comparison to other pre-training models.
So let's explore Flan-UL2 and discover how it can transform the pre-training model industry.
What is Flan-UL2?
Flan-UL2 is an encoder-decoder model based on the T5 architecture that was improved utilizing "Flan" prompt tweaking and dataset gathering. It is a unified framework for pre-training models that is consistently effective across datasets and configurations.
A beefed-up T5 model that has been trained using Flan is known as Flan-UL2. It is a sizable language model that excels at tasks requiring the interpretation of natural language.
What is the difference between Flan-UL2 and UL2?
The UL2 model, which is a unified framework for pre-training models that are consistently effective across datasets and configurations, is used by Flan-UL2, which has the same configuration. When comparing Flan-UL2 to UL2, the "Flan" prompt tweaking and dataset collecting were used to fine-tune the former, but not the latter.
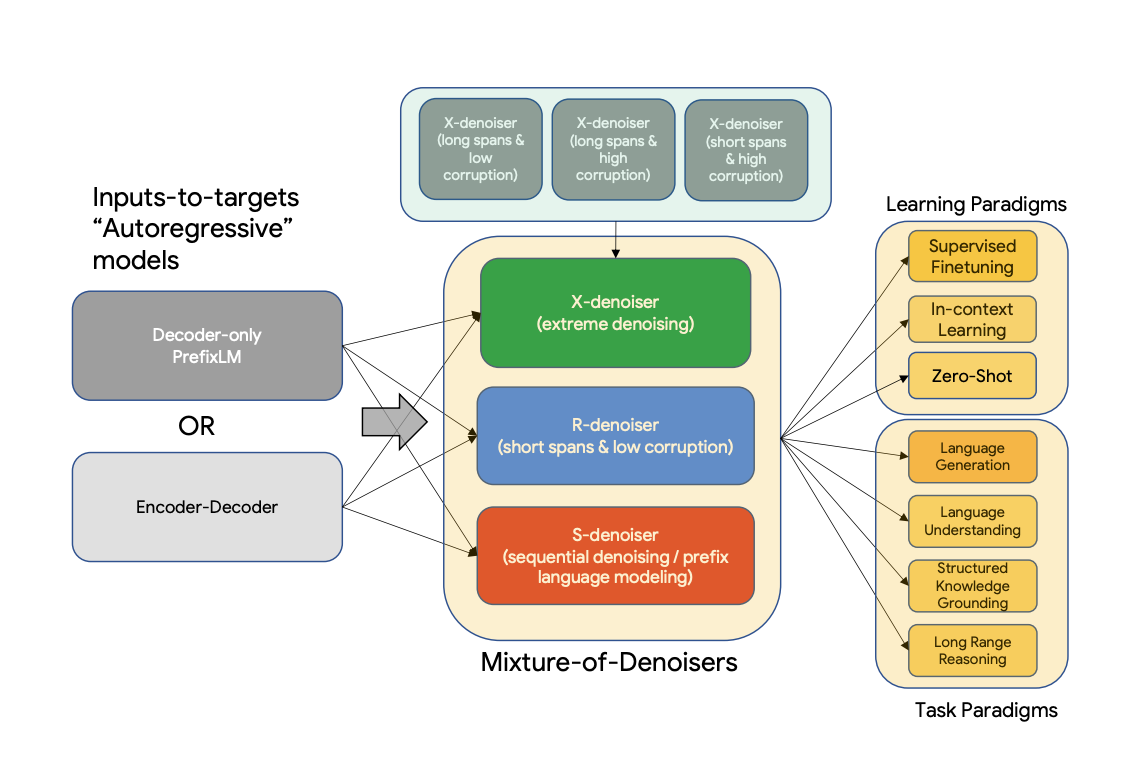
Furthermore, UL2 employs Mixture-of-Denoisers (MoD), a pre-training aim that mixes various pre-training paradigms, whereas Flan-UL2 is an encoder-decoder model based on the T5 architecture.
These are the variations between the Flan-UL2 and other Flan models:
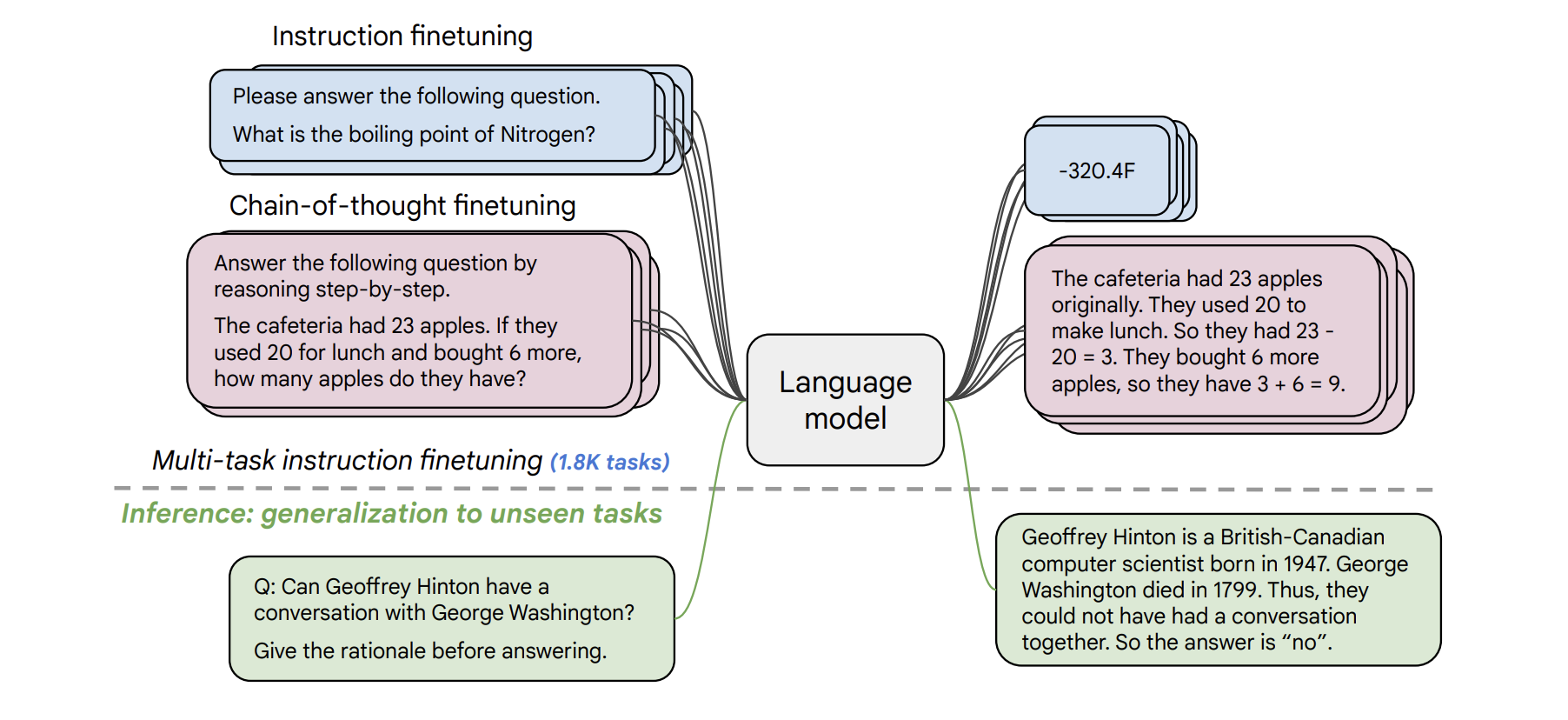
Fine-Tuning: Flan-UL2 was fine-tuned using tasks that required following instructions, whereas other Flan models were fine-tuned using other techniques.
Performance: On all four setups, Flan-UL2 outperforms Flan-T5 XXL, with a respectable performance lift of +3.2% relative improvement. FLAN-UL2 performs significantly better than FLAN-T5 on the majority of NLU benchmarks.
Receptive field: Flan-UL2 is more useful for few-shot learning since it has a receptive field of 2048.
Mode switch tokens: In order to achieve good performance, the original UL2 model and other Flan models have to have mode switch tokens. Before using Flan instruction tuning, Flan-UL2 was trained for an extra 100k steps to forget mode tokens; as a result, this Flan-UL2 checkpoint no longer needs mode tokens.
License: While various Flan models could have different licenses, Flan-UL2 is open-source and distributed under the Apache license.
Overall, Flan-UL2 is a specialized language model with a receptive field of 2048 that was refined with instruction-based tasks. On some benchmarks, it performs better than other Flan models and doesn't need mode switch tokens. Additionally open source and distributed under the Apache license.
What is the Pre-training Procedure for UL2?
UL2 is a general framework for pre-training models that work with all datasets and configurations. Mixture-of-Denoisers (MoD), a pre-training target used by UL2, brings together many pre-training paradigms. In UL2, the idea of mode switching is introduced, whereby downstream fine-tuning is carried out in many modes, each of which is associated with a distinct pre-training target.
The Colossal Clean Crawled Corpus is a dataset that goes by the name "C4". It is an extension created using the Common Crawl base set, a nonprofit, which comprises more than 750GB of text data, and is used to pre-train the model.
The model is trained on a total of 1 trillion tokens on C4 with a batch size of 1024, with the sequence length set to 512/512 for inputs and targets. UL2 can be thought of as a T5-like model that was trained with a different purpose and a little different scaling.
How Flan-UL2 can be utilized in AI Models?
AI models can use Flan-UL2 to perform tasks involving natural language interpretation. It is a sizable language model that performs well on the majority of NLU benchmarks. An encoder-decoder model called Flan-UL2 is based on the T5 architecture, a prominent architecture for applications involving natural language processing.
It is a common framework for pre-training models that work with all datasets and configurations. Hugging Face & Amazon Web Services (AWS) SageMaker can be used to deploy Flan-UL2 in business/enterprise environments. Flan-UL2 has improved and performed better than other large language models on all four configurations, with a performance lift of +3.2% relative improvement.
How does FLAN-UL2 improve upon the original UL2 model?
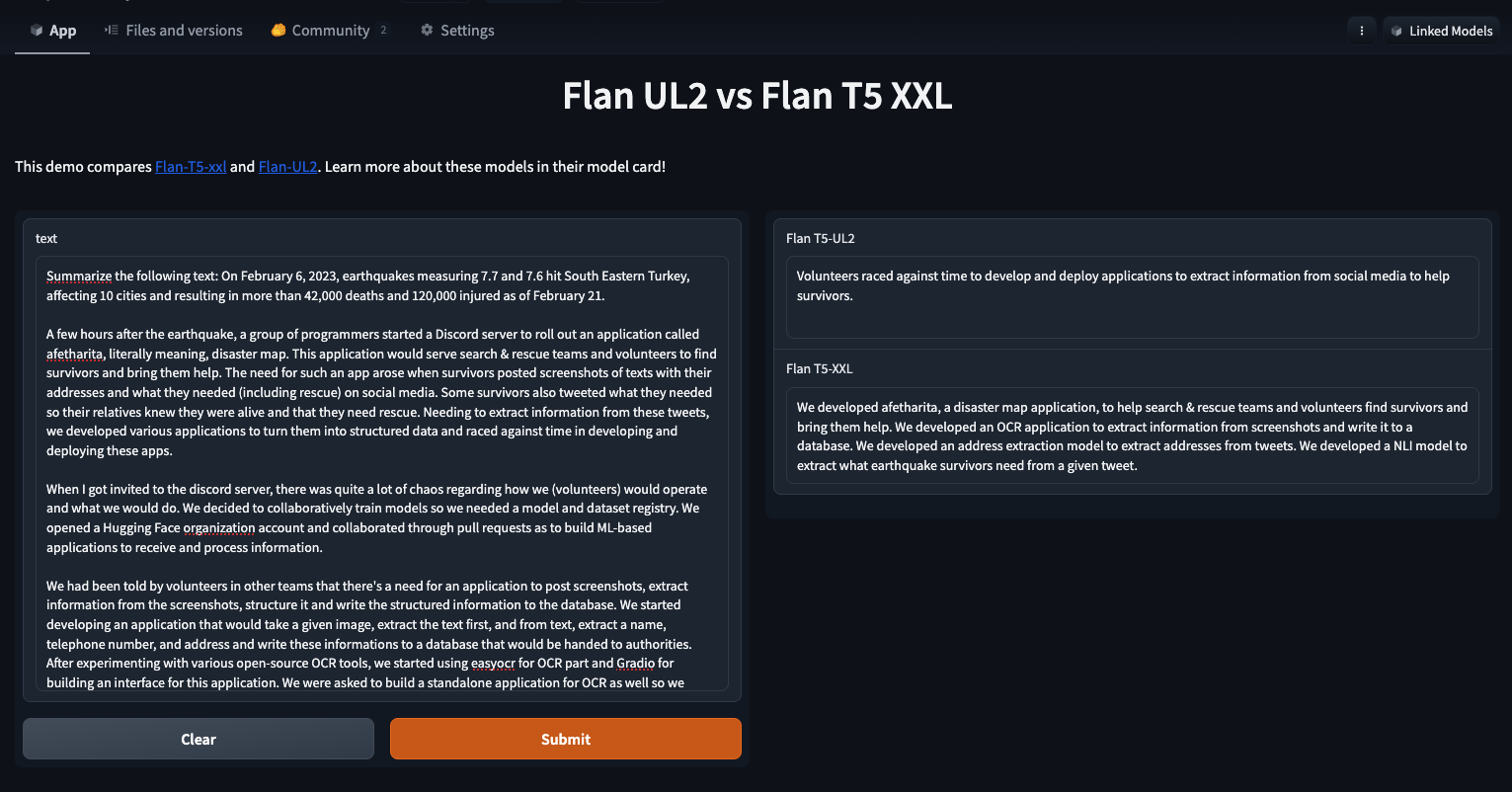
The usability of the original UL2 model is improved by FLAN-UL2 over the original.
The UL2 checkpoints were used to train the Flan-UL2 model, which was subsequently given an additional training session using Flan Prompting. In order to reduce the reliance on mode tokens, the original training corpus is employed with a bigger batch size.
Mode tokens are no longer required for inference or fine-tuning at the new Flan-UL2 checkpoint. Flan-UL2 20B outperformed Flan-T5-XXL in terms of upgrades and performance when compared to other models in the Flan series. On all four scenarios, Flan-UL2 20B outperforms Flan-T5 XXL, with a performance lift of +3.2% relative improvement.
Applications of FLAN-UL2
The vast majority of tasks and configurations can be successfully completed by Flan-UL2, including language generation (with automated and human evaluation), language comprehension, text classification, question answering, commonsense reasoning, long text reasoning, structured knowledge grounding, and data retrieval.
The Flan-UL2 model, which is based on the UL2 model, has been scaled up to a moderate scale configuration of roughly 20B parameters and ran trials over an extremely varied suite of more than 50 NLP tasks.
Labellerr’s easy-to-use data annotation tool helps you create perfect datasets for any task. Try it now
Conclusion
To sum up, Flan-UL2 is an integrated framework for pre-training models with the goal of enhancing their applicability and efficacy across various datasets and configurations. The framework accomplishes this by incorporating a number of cutting-edge pre-training approaches, such as multi-task learning and meta-learning, and by utilizing a variety of data sources.
Additionally, Flan-UL2 offers a flexible and modular design that is simple to adapt to the requirements of various applications. Overall, Flan-UL2 is a significant step towards building more adaptable and versatile machine learning models that work well in a number of settings.
Enhance AI Training with Labellerr Solutions
FAQs
- What is Flan-UL2?
Flan-UL2 is an encoder-decoder model based on the T5 architecture that was improved utilizing "Flan" prompt tweaking and dataset gathering. It is a unified framework for pre-training models that is consistently effective across datasets and configurations.
2. How do the Flan-UL2 models compare to other models?
Flan-UL2 outperforms Flan-T5 XXL, with a respectable performance boost of +3.2% relative improvement. The CoT configuration appears to have produced the majority of the benefits, whereas performance under direct prompting (MMLU and BBH) appears to be, at best, modest.
3. What is the Flan-UL2's receptive field?
Flan-UL2 is more useful for few-shot in-context learning because of its 2048 receptive field.
4. Is Flan-UL2 open-source?
Flan-UL2 is indeed an open source and distributed under the Apache license.
5. What are the key features of Flan-UL2?
Some of the key features of Flan-UL2 include being completely open source, having the best OS model on MMLU/Big-Bench-Hard, and being released on an Apache license.
6. What distinguishes the Flan-UL2 from other Flan models?
With instruction-based tasks, Flan-UL2 was improved, outperformed other Flan models on some benchmarks, and doesn't need mode switch tokens. Additionally, it is open source and has a receptive field of 2048.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
