

Automation in Data Labeling Platforms: A Comprehensive Guide


Data labeling is an essential process in training machine learning models, and it involves manually annotating large datasets to provide accurate and consistent labels for use in the training process.
However, the manual process of data labeling can be time-consuming, error-prone, and expensive.
That's where automation comes into play. In this comprehensive guide, we'll explore the role of automation in data labeling platforms, including how it can improve the accuracy and speed of data labeling, reduce costs, and enable greater scalability.
We'll also delve into the different types of automation techniques used in data labeling and highlight the benefits and challenges associated with each.
By the end of this guide, you'll have a better understanding of the crucial role that automation plays in data labeling and how it can help you to achieve more accurate and efficient machine learning models.
The Role of Data Labeling
Data labeling is a critical process in machine learning, where the quality and accuracy of labeled data determine the effectiveness of the model. The process of data labeling involves manually annotating datasets to provide accurate and consistent labels for use in the training process.
However, the manual process of data labeling can be time-consuming, erroneous, and expensive. Automation plays a vital role in data labeling platforms, and it offers numerous benefits, including:
Automation plays a critical role in data labeling and can help achieve more accurate and efficient machine-learning models in several ways.
- Improved Accuracy
One of the most significant benefits of automation in data labeling is improved accuracy. When data labeling is done manually, there is always a risk of human error. However, automation eliminates the risk of human error by providing consistent and accurate labeling based on predefined rules and algorithms. This helps to ensure that the labeled data is of high quality, which can lead to more accurate and efficient machine learning models.
2. Increased Speed
Another benefit of automation in data labeling is increased speed. Data labeling can be a time-consuming process, especially when dealing with large datasets. However, automation can quickly process and label large amounts of data, reducing the time required for labeling. This can help to speed up the development of machine learning models, allowing them to be deployed faster and more efficiently.
3. Reduced Costs
Automation can also help reduce the cost of data labeling. Manual data labeling can be expensive, as it requires a significant amount of time and resources. However, automation can significantly reduce the need for human resources, thereby reducing labor costs.
4. Greater Scalability
Automation enables greater scalability in data labeling, allowing data labeling platforms to handle larger datasets and increasing the speed and accuracy of the labeling process. This scalability is essential as the demand for labeled data increases with the growth of machine learning and artificial intelligence.
5. Improved Consistency
Automation also provides improved consistency in data labeling. When data is labeled manually, there is a risk of inconsistency between different labelers. However, automation ensures that labels are generated based on predefined rules and algorithms, which provides a consistent and accurate labeling process. This consistency can help to improve the quality of the labeled data, which can lead to more accurate and efficient machine learning models.
In conclusion, automation plays a crucial role in data labeling, helping to improve the accuracy and speed of data labeling, reduce costs, and enable greater scalability. With automation, data labeling can be completed faster and more accurately, leading to more accurate and efficient machine learning models.
By reducing the risk of human error, automation ensures that the labeled data is of high quality, which is essential for developing accurate and efficient machine-learning models.
Different Types of Automation Techniques
There are different types of automation techniques used in data labeling platforms, including:
Rule-based Automation
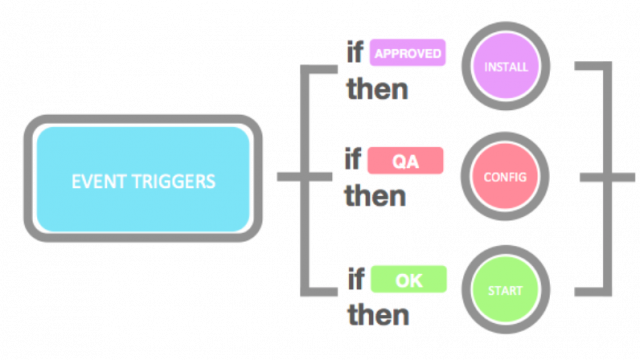
Rule-based automation involves using predefined rules to label data automatically. This method is ideal for simple labeling tasks that require basic labeling rules.
Semi-Automated Labeling
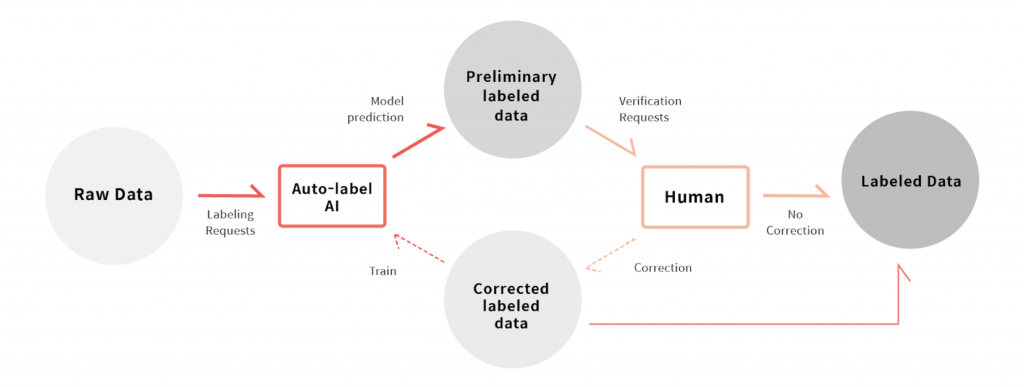
Semi-automated labeling involves combining human labeling with automation. This method is ideal for complex labeling tasks that require human judgment and input.
Active Learning
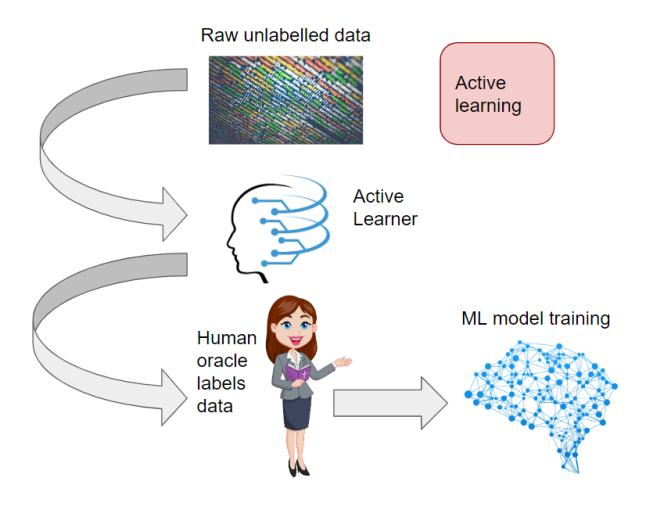
Active learning involves using algorithms that learn from labeled data to improve the accuracy of subsequent labeling. This method reduces the need for human input and improves the accuracy of the labeling process.
Despite the benefits of automation, there are still some challenges associated with its use in data labeling platforms, including the risk of bias and the need for human oversight. Bias can occur when automation is used to label data based on predefined rules, which may not consider all possible outcomes. Human oversight is necessary to ensure that the automated labeling is accurate and consistent.
Conclusion
In conclusion, automation has a significant role to play in data labeling platforms, as it helps to improve the accuracy and speed of data labeling, reduce costs, and enable greater scalability.
With automation, data labeling can be completed faster and more accurately, making it an essential tool for machine learning and artificial intelligence. However, it is important to note that automation is not a replacement for human input and oversight.
Human oversight is still necessary to ensure that the labeling process is unbiased and accurate and to monitor the quality of the output. Despite the challenges associated with automation in data labeling, it offers numerous benefits and is becoming increasingly important in the data labeling process. With the continued growth of machine learning and artificial intelligence, automation will continue to play an essential role in data labeling platforms.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
