Training Small-Scale Vs Large-Scale Language Models: The Difference Explore the contrasts between training small and large-scale language models, from data requirements and computational power to model complexity and performance nuances in NLP applications
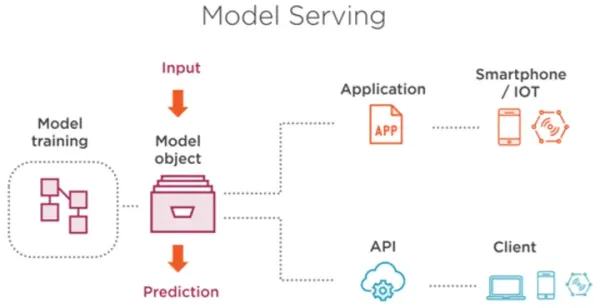
technology Comparing Top 9 Model Serving Platforms: Pros and Cons Comparing the top 9 model serving platforms to help you choose the best fit for efficient ML deployment based on scalability, performance, and more.
labellerr Faster Data Annotation With Labellerr's Auto-Label Feature Table of Contents 1. Introduction 2. Why is it needed? 3. Advantages of using AutoLabel 4. How to use Autolabel in Labellerr? 5. Conclusion 6. Frequently Asked Questions Introduction In data annotation, time, efficiency and productivity are important. To address these challenges Labellerr comes up with its latest feature: the
Object Detection Tools Self-Supervised Object Detection from Egocentric Videos Table of Contents 1. Introduction 2. Why Self-Supervised Learning? 3. Key Concepts of DEVI Model 4. Model Architecture 5. Results and Evaluation 6. Conclusion 7. FAQs Introduction Our world is experienced primarily through our own eyes. This first-person perspective, known as egocentric vision, presents a unique challenge for computer vision
Segementation Model Segmentation Simplified: A Deep Dive into Meta's SAM 2 I’m an avid user of the Segment Anything Model (SAM) who’s been fascinated by its capabilities since its launch. Over the past few months, I’ve integrated SAM into various projects, ranging from basic image segmentation to more complex multiple object tracking tasks. Recently, the developers behind SAM
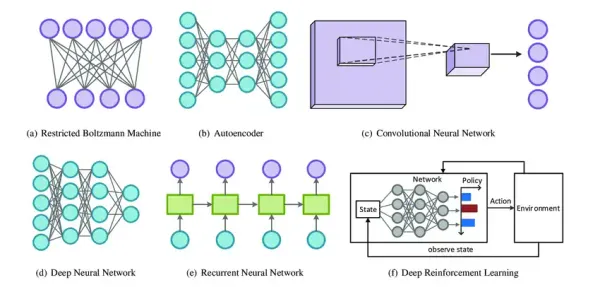
All about deep learning models that you should know Explore deep learning essentials, from neural network models like CNNs, RNNs, and GANs to applications in vision, language processing, and robotics. Learn how methods like transfer learning and dropout prevent overfitting for improved AI model accuracy.
LLama3.1 Meta's Llama 3.1- Is It A Gamechanger For Gen AI? Table of Contents 1. Introduction 2. Llama 3.1 Model Variants 3. Technical Details of Llama 3.1 4. Performance Evaluation 5. Key Usages of Llama 3.1 6. Llama 3.1 Pricing Comparisons 7. Llama 3.1 vs Other Models: Industry Use Case Comparison 8. Does Llama 3.1
RLHF DPO vs PPO: How To Align LLM Direct Preference Optimization (DPO) and Proximal Policy Optimization (PPO) are two approaches to align Large Language Models with human preferences. DPO focuses on human feedback to optimize models directly, while PPO uses reinforcement learning for iterative improvements.
FVLM F-VLM: Open-Vocabulary Object Detection Upon Frozen Vision And Language Models Table of Contents 1. Introduction 2. Traditional Object Detection Challenges 3. Understanding Vision Language Models (VLMs) 4. Architecture of F-VLM 5. Advantages of F-VLM 6. Performance and Results 7. Applications of F-VLM 8. Conclusion 9. FAQs Introduction In the rapidly evolving field of computer vision, object detection remains a fundamental
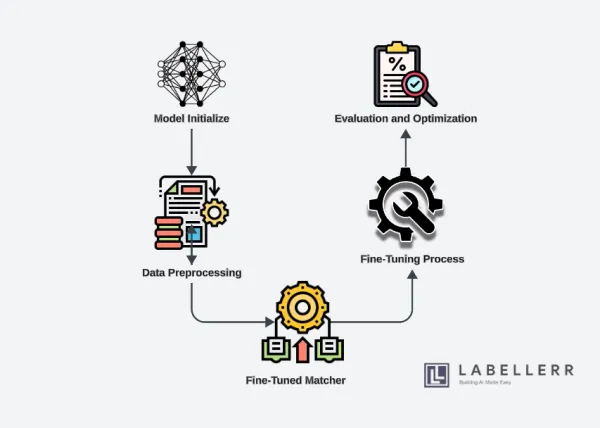
segment anything Leveraging Matching Anything by Segmenting Anything (MASA) For Object Tracking Table of Contents 1. Overview of Multiple Object Tracking (MOT) 2. Importance of MOT in Various Applications 3. What is SAM? 4. Benefits of using MASA 5. How MASA works? 6. Finetuning Process Leveraging MASA's Capability 7. Applications of the Fine-Tuned Model 8. Conclusion 9. FAQs Overview of
RT-DETR RT-DETR: The Real-Time End-to-End Object Detector with Transformers Table of Contents 1. Introduction 2. Traditional Object Detection Methods: Evolution and Impact 3. Limitations of Previous Models 4. RT-DETR:Real-Time End-to-End Object Detector with Transformers 5. Architecture of RT-DETR 6. Experimental Results 7. Applications of RT-DETR 8. Conclusion 9. Frequently Asked Questions Introduction Object detection is a fundamental computer
Multimodal AI Evaluating & Finetuning Text-To-Audio Multimodal Models Table of Contents 1. Introduction 2. Why Are We Fine-Tuning Text-to-Audio Models? 3. Steps For Fine-Tuning a TTA Model 4. Model Architecture of TTA Model 5. Case Study:Fine-Tuning TTA Multimodal Systems for Audiobook Generation 6. Challenges in Text-to-Audio Multimodal Systems 7. Conclusion 8. FAQ Introduction Text-to-Audio Multimodal (TTA) systems
segment anything How RobustSAM Helps With Blurry/Degraded Image Segmentation Table of Contents 1. Introduction 2. Introduction to RobustSAM 3. Architecture of RobustSAM 4. Results and Performance of RobustSAM 5. Applications Of RobustSAM 6. Conclusion 7. FAQ Introduction In the field of computer vision, image segmentation stands as a crucial task. It involves partitioning an image into multiple segments or
technology 11 Tools to Run a Computer Vision Project Explore essential tools for computer vision, from OpenCV and TensorFlow to Keras and PyTorch, each offering specialized capabilities for image processing, object detection, and model deployment, enhancing project efficiency and accuracy.
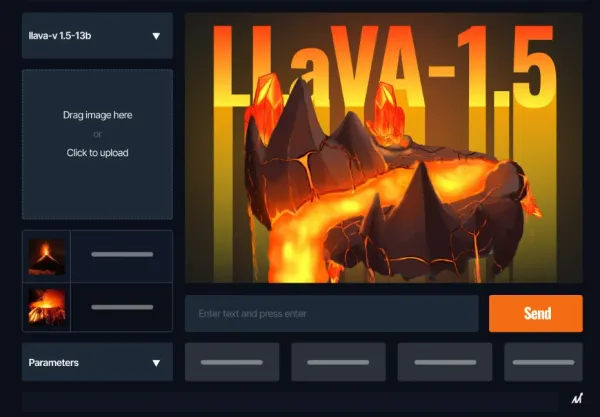
Unlocking Multimodal AI: LLaVA and LLaVA-1.5's Evolution in Language and Vision Fusion LLaVA merges language and vision for advanced AI comprehension, challenging GPT-4V with chat capabilities and Science QA. Discover LLaVA-1.5's enhanced multimodal performance with a refined vision-language connector.
Florence2 Florence-2: Vision Model for Diverse AI Applications Table of Contents 1. Introduction 2. Overview of Florence-2 3. Key Features of Florence-2: Unifying Vision and Language 4. Architecture and Design 5. Performance and Evaluation 6. Applications and Use Cases 7. Integration of Florence-2 in Labellerr 8. Conclusion 9. FAQ Introduction Introducing Florence-2, a groundbreaking vision model that will
SegGPT SegGPT: Contextual Segmentation To Generate Labeled Images At Scale Table of Contents 1. Introduction 2. What is SegGPT? 3. SegGPT Model Architecture 4. Inference and Performance 5. Applications of SegGPT 6. AI-Assisted Labeling with SegGPT 7. Leveraging SegGPT in Labellerr 8. Conclusion 9. FAQ Introduction In the field of computer vision, one of the most challenging and essential tasks
Multimodal AI Evaluation and Fine-Tuning for Image Captioning Models - A Case Study Table of Contents 1. Evaluation Metrics 2. Fine-Tuning Strategies for Image Captioning Models 3. Challenges in Image Captioning 4. Case Study 5. Conclusion 6. FAQ Image captioning models are sophisticated AI systems designed to generate descriptive text for images automatically. These models play a crucial role in various applications, such
MythosAI How Labellerr Transformed This Maritime Startup's Training Data Pipeline: A Case Study Table of Contents 1. Introduction 2. About Customer 3. Data Volume and Accuracy Challenge 4. How Labellerr Stepped In 5. Results and Impact 6. Conclusion 7. FAQ Introduction In today's fast-paced AI-driven landscape, the demand for accurate and efficient image annotation is more critical than ever. In this
Multimodal AI Evaluating and Finetuning Text To Image Model - Case Study Table of Contents 1. Introduction 2. Why Evaluate and Fine-Tune These Models 3. How Fine-Tuning is Done for Text-to-Image Models 4. Challenges Faced in Evaluating and Fine-Tuning Text-to-Image Models 5. Case Study: Improving Text-to-Image Models for a Content Creation Client 6. Conclusion 7. FAQ Introduction Text-to-image models are advanced AI
data annotation Importance Of Data-Centric Approach For Vision AI Table of Contents 1. Introduction 2. From Model-Centric to Data-Centric AI: Data is King 3. Core Principles of Data-Centric AI: 4. Benefits of Data-Centric AI: Building Better, More Reliable AI Systems 5. Challenges of Data-Centric AI 6. Conclusion 7. FAQ Introduction In the rapidly evolving field of artificial intelligence, the
Vision-language models AIDE (Automatic Data Engine): Leveraging LLMs To Auto Label Table of Contents 1. Introduction 2. Introduction To AIDE 3. Components of AIDE 4. Experimental Results of AIDE 5. Conclusion 6. FAQ Introduction The field of autonomous vehicles (AVs) is rapidly evolving, with the promise of revolutionizing transportation by enhancing safety, efficiency, and convenience. Central to the successful deployment of
NLP Evaluating and Fine-Tuning Multimodal Video Captioning Models - A Case Study Video captioning models represent a significant advancement in the intersection of computer vision and natural language processing. These models automatically generate textual descriptions for video content, enhancing accessibility, searchability, and user engagement. As video content continues to proliferate across various platforms, the ability to accurately describe and index this content
Scale AI Scale AI vs Labellerr vs Cloudfactory Table of Contents 1. Scale AI vs Labellerr 2. Scale AI vs CloudFactory 3. Labellerr vs CloudFactory 4. Conclusion 5. FAQ In the realm of artificial intelligence (AI), data is very important. However raw data lacks the understanding needed for machine learning models to function. This is where data annotation
Scale AI Scale AI vs Labellerr vs Appen Compare Scale AI, Labellerr, and Appen for data annotation: Scale AI excels at complex, large-scale projects, Labellerr offers balanced automation and affordability, and Appen provides a human-powered approach for varied project sizes with global reach.