

How AI and ML solutions can optimize your data pipelines

For a company to strengthen its position in today's cutthroat marketplace, data is the most important step up the ladder. Data is everywhere, so it's crucial to gather it and capture it in the right way so that it can be analyzed further and used to generate practical insights for business choices.
Large amounts of data are typically migrated and created using an ETL (Extract, Transform, Load) tool. But in the modern world, where there is excess data, real-time analysis of data is essential to make quick judgments and take the appropriate action. Therefore, rather than manually generating ETL code and cleaning the data, businesses are turning to the knowledge of data engineers to direct data planning and pipeline optimization with the help of AI and ML.
Let’s get deep into understanding data pipelines and how to optimize the data pipelines with AI and ML solutions.
Table of Contents
- A Data Pipeline: What is it?
- How do AI and ML Pipelines Improve Efficiency and Productivity?
- How to Make Your Data Pipeline Optimal?
- Conclusion
A data pipeline: What is it?
Data is moved from an origin to a destination through a series of operations known as a data pipeline. Filtering, cleansing, collecting, enriching, and even analyzing data-in-motion are all possible steps in a pipeline.
Data pipeline transport and combine data to make it appropriate for business intelligence and analytics from an ever-increasing variety of diverse sources and formats. Data pipelines also provide team members with the precise data they require without demanding access to private production systems.
The configuration of data pipelines to allow for the collection, transit, and delivery of data is described in data pipeline architectures. Both batch processing and stream processing can be used to transport data. In batch processing, groups of data are transferred once or on a scheduled basis from sources to targets. The tried-and-true traditional method of transporting data is batch processing, but it does not enable real-time insights and analysis.
How do AI and ML pipelines improve efficiency and productivity?
Provides Analytics and Real-Time Data Processing
For organizations to swiftly uncover and act on insights, modern data pipelines must load, transform, and analyze data in close to real-time. Data needs to be immediately consumed from resources including libraries, IoT devices, messaging services, and log files to start. The best method for providing a stream of real-time data for databases is log-based Change Data Capture (CDC).
Since batch-based processing requires hours or even days to extract and transport data, real-time, or continuous, processing of data is preferable to batch-based processing. A valuable social media trend could emerge, peak, and dissipate before a company can detect it. Likewise, a security vulnerability could be discovered too late, allowing malevolent actors to carry out their schemes.
Decision makers have access to more recent data thanks to real-time data pipelines. And companies in the fleet logistics and distribution industries cannot afford any delays in the processing of data. To avoid accidents and breakdowns, they must be able to detect reckless driving or dangerous driving circumstances in real-time.
Offers Cloud-Based Scalable Architecture
The ability to autonomously scale computational and storage resources up or down is a feature of modern data pipelines. Modern data pipelines equipped with AI and ML technology include an architecture where computational resources are split among distinct clusters, in contrast to classic pipelines which are not intended to support several workloads concurrently. Clusters can expand forever in size and number while still having access to the collective dataset. Since more resources may be supplied right away to handle spikes in data volume, data processing times are now easier to estimate.
Data pipelines built on the cloud are flexible and adaptable. They enable companies to benefit from diverse trends. For instance, a business that anticipates a jump in summer sales can readily add more processing capability as needed and need not prepare for this possibility weeks in advance. It is more difficult for firms to react rapidly to trends without elastic data pipelines.
Defeasible Architecture
Failure of the data pipeline, while the data is being transmitted, is a very real scenario. Today's data pipelines provide a high level of availability and dependability to minimize the effects on mission-critical procedures.
In the case of a node failure, program failure, and the inability of specific additional services, advanced data pipelines are constructed with a distributed system using AI and ML technologies that offer fast fail over and notify customers. And if a node eventually goes down, the cluster's other nodes take over right away without the need for any big actions.
Exactly-Once Processing (E1P)
Data pipeline problems frequently involve loss of data and data duplication. Advanced check-pointing capabilities provided by modern data pipelines guarantee that no events are missed or handled more than once. Events handled and the length of time they spend moving through multiple data pipelines are tracked by checkpointing.
In case of a failure, checkpointing works in conjunction with the data repeat feature that is provided by many sources. Persistent messaging data pipelines can replay and checkpoints data for providers without data replay functionality to make sure it has only been handled once.
Self-Service Administration
The construction of modern data pipelines makes use of tools that are interconnected. Teams can utilize a variety of technologies, including data integration platforms, data warehouses, data lakes, and programming languages, to quickly create and manage data pipelines in an automated, self-service way.
The integration of a sizable number of external technologies for data input, transport, and analysis typically takes a lot of time and effort in traditional data pipelines. Regular maintenance takes time, causes bottlenecks, and adds new layers of complexity. In addition, traditional data pipelines frequently struggle to manage unstructured, semi-structured, and structured data.
Modern data pipelines democratize data access. Businesses may benefit from data with much less effort and in-house staff because handling all forms of data is simpler and much more automated than before.
Process large amounts of data in different formats
Modern data pipelines must be able to process massive volumes of semi-structured data (such JSON, HTML, and XML files) and unstructured data, which account for 80% of the data gathered by businesses (including log files, sensor data, weather data, and more).
Apps, sensors, databases, log files, and other sources of data may all need to be moved and unified via a big data pipeline. It is frequently necessary to standardize, clean, enrich, filter, and aggregate data in almost real-time.
How to make your data pipeline optimal?
While transporting enormous amounts of data presents many obstacles, minimizing data loss and downtime during ETL runs is the major objective of data optimization. Here are some successful ways to optimize the data pipeline:
Parallelize the flow of data
Instead of processing all the data sequentially, simultaneous or concurrent data flow might save a lot of time. If there is no dependence on the data flow, this is feasible. 15 structured data tables, for instance, must be imported from one resource to another. However, since the data tables are independent of one another, we can run multiple batches of tables concurrently rather than one by one. Therefore, five tables can be run simultaneously by each batch. As a result, the pipeline's runtime is cut in half compared to a serial run.
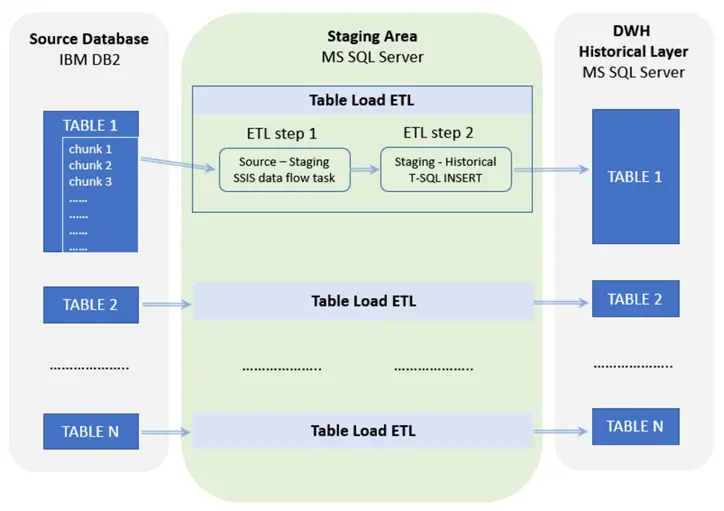
Use data quality inspections
Every step of data processing has the potential to compromise data quality, so database administrators must work hard to maintain good data quality. A schema-based test is one way to perform these tests, which allows you to examine the existence of null or blank data and the column data type for each data table. The desired result can be created if the data verification matches; otherwise, the data is refused. Another option is to add indexing to the table in order to prevent duplicate records.
Develop Generic Pipelines
The same core data is frequently required by numerous organizations both inside and outside of your team to conduct their studies. The very same part of the code may be reused if a certain pipeline or section of code is repeated. We can use the current code as needed when a new pipeline must be developed. This eliminates the need to design new pipelines from scratch by allowing us to recycle pipeline elements.
The values should be parameterized rather than hard coded in order to construct a pipeline general. By altering only the values, one may easily run the process thanks to the use of parameters. For instance, connection values and database connection information can differ between teams. In some circumstances, giving these values as arguments will be helpful. By altering the connection parameters as well as executing the operation, the team may now utilize this pipeline with ease.
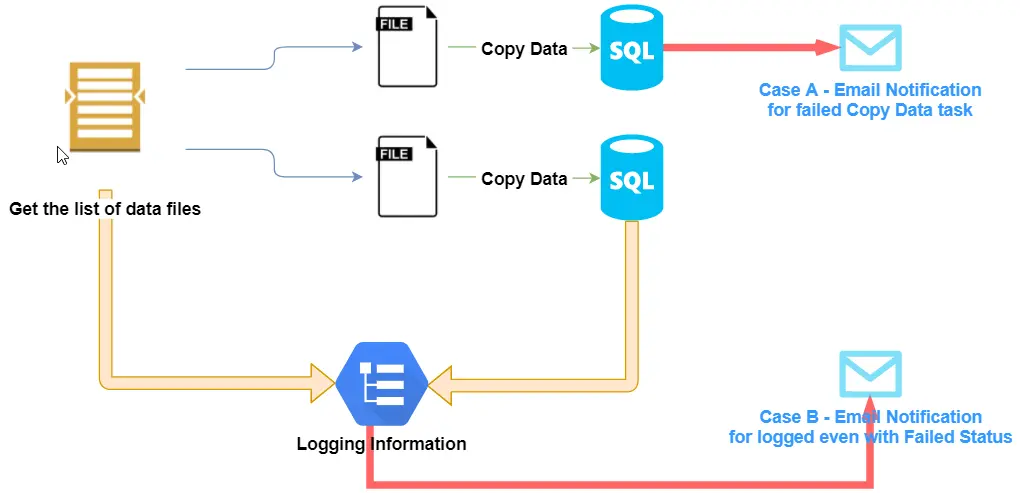
Create email notification
It is tedious to manually monitor job performance while thoroughly scrutinizing the log file. The answer to this issue is to send an email notification that will tell the recipient of the job's status while it is running and will also do so in the event that it fails. This reduces response time and accurately resumes work from the point of failure in a short amount of time.
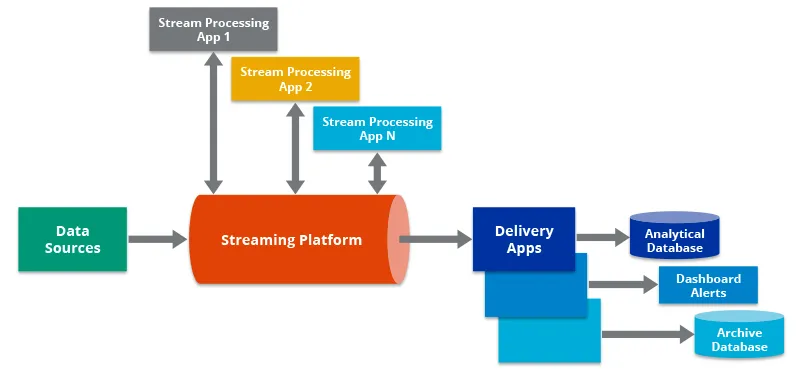
Instead of using batches, use streaming
Data is typically gathered by businesses throughout the day. Regular batch ingestions may therefore miss some occurrences. Serious repercussions could include ineffective fraud detection or abnormalities. Set up continuous streaming ingestion using AI and ML techniques instead to lessen pipeline delay and give the company the tools to exploit recent data.
Conclusion
Although the aforementioned advice is general, it can be tailored to any data optimization problem. There are numerous additional techniques with the help of AI and ML to streamline your pipeline, such as streamlining conversions and data filtering prior to pipeline processing to lessen the load.
Final point: Data engineers must be sure that the organization can use and manage the pipeline even if extensive data processing is crucial when creating data pipelines. By following these guidelines for data engineering, you can make sure that the data pipelines are usable, valid, scalable, and production-ready for data consumers like data scientists to utilize for analysis.
If you find this information enlightening, then keep visiting us!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
