

How to manage data pipeline to train AI model

When you are dealing with data, it is essential to create a data pipeline. Otherwise, training your data becomes arduous.
Data cannot create the right output for any model until and unless processed in the right manner.
By creating a data pipeline, you are saving your AI model from sinking because most of the models fail due to wrong execution and processing of data.
You can simply, train your AI model with a data pipeline by managing it in the right way. You must be thinking about what can be the right way. Read out the complete blog to know about it.
Table of Contents
- What is a Data Pipeline?
- The Architecture of the Data Pipeline
- Which is the Way to Manage the Data Pipeline?
What is a data pipeline?
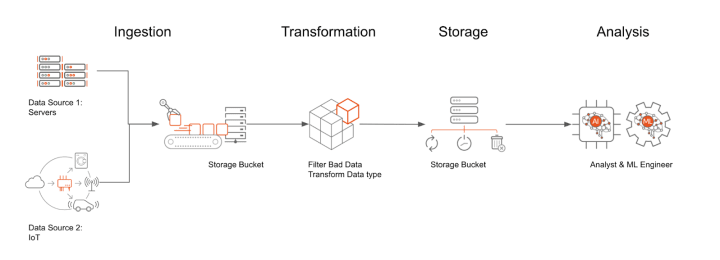
A succession of data processing operations is called a data pipeline. The data is ingested at the start of the pipeline if it is not already put into the data platform.
The next set of steps each produces an output that serves as the input for the following one. This keeps happening till the pipeline is finished. Independent actions might occasionally be carried out in parallel.
Three essential components make up a data pipeline: a source, a processing structure (or stages), and a destination. The final destination may be referred to as a sink in some data pipelines.
Data pipelines, for instance, allow data to move from an application into a database system, from a data lake into analytics databases, or into a system for processing payments.
Data pipelines can alternatively utilize the same input and sink, in which case their only purpose is to modify the underlying data collection. A data pipeline connects points A and B (or B, C, and D) whenever there is data processing between them.
Organizations are exchanging data among more and more systems as they strive to create systems with small datasets that accomplish extremely specialized tasks (these kinds of applications are known as "microservices").
As a result, the effectiveness of data pipelines becomes a crucial factor in their management and design.
One or more data pipelines may receive data from one or more source systems or applications, and all those pipelines may themselves be dependent on some other pipelines or systems for their outputs.
Data pipeline in computer vision
In computer vision, the path that the data takes is referred to as a data pipeline. Data is collected, stored, trained, and then used to deploy models.
A connected technical setup is ideal, with data storage related to multiple data preparation along with some MLops technologies, which are then linked via an API to the deployed product and the machine learning model.
The architecture of the data pipeline
A data pipeline is made up of various components. Pipelines may manage both organized and unstructured data thanks to these components working together.
Email addresses, contact information, and other information that may be accessed in a certain manner are all examples of structured data.
Images, comments on social media, phone searches, and a wide variety of other data types are all examples of unstructured data. Unstructured data is challenging to track in a rigid format.
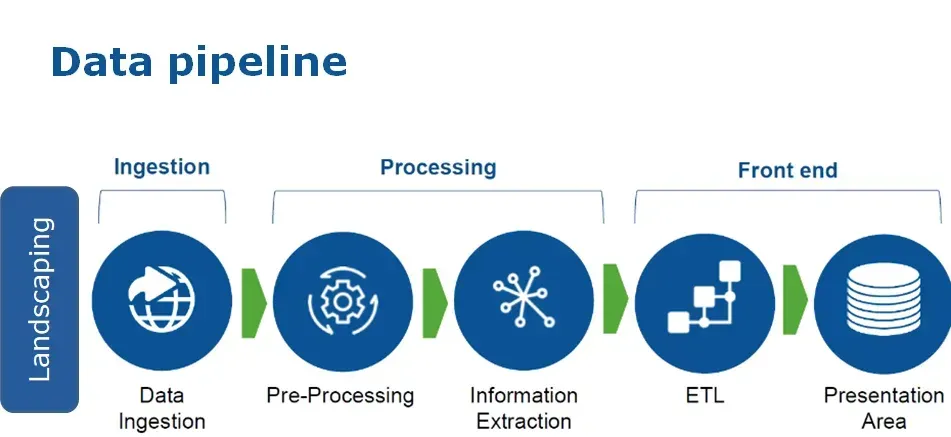
Every data pipeline needs the following elements to prepare massive data sets for any kind of analysis:
Source
Any location where the pipeline retrieves data is referred to as a source. An IoT gadget, email, or CRMs may be examples of this.
Destination
The destination, which is usually a data pool or data warehouse, is the last stop on the pipeline. The data is kept at this endpoint until it is needed for analysis. An alternative form of endpoint, such as a tool for data visualization, can be used to access data from the pipeline. These endpoints provide quick analysis as well.
Dataflow
The term "dataflow" describes how data is transferred from one location to another while changing along the way. ETL, or extract, transform, load, is one of the most used methods for handling data flow.
Processing
Processing includes all phases, including data extraction, transformation, and transport to the end location. Dataflow is decided upon by the processing component.
The processing component chooses the optimum extraction procedure, for instance, out of the various ones that might be used to ingest data. The two most popular techniques for extraction are batch processing and stream processing.
Workflow
Workflow explains the pipeline's task sequencing and how each job is connected to the others. When a pipeline operates is also determined by these elements. Usually, tasks that are upstream are finished before those that are downstream.
Monitoring
Because it is always being watched, a data pipeline continuously produces high-quality data. Any kind of data loss or error will be discovered through monitoring and dealt with swiftly.
Data pipelines are also watched for speed and efficiency because they aren't very helpful if they can't transport data to their destination promptly.
The pipeline's throughput, latency, and dependability all affect how quickly data passes through it. As the amount of data increases, each of these elements is impacted, making ongoing monitoring essential.
Which is the way to manage the data pipeline?
Data movement from source to destination is automated by a data pipeline technology. The kinds of data sources you currently have and those you could use in your research in the future can be handled by data pipeline tools efficiently.
The entire process is automated in an effective, dependable, and secure way using a Data Pipeline tool. A destination, frequently a Data Cove or Data Warehouse, is consistently and easily migrated from a variety of data sources using data pipeline software. The basic idea of data pipelines is to manage and automate the process.
When are in the stage of establishing an AI model with the help of trained data, then there is a need to acquire high-quality data. At that point, Labellerr comes to your rescue.
We are a data training platform that helps in automating annotation processes along with the involvement of skilled ML data scientists. If you are looking for a training data platform that automates processes, then you can reach out to us!
Automate your data pipeline management with Labellerr and ensure high-quality data for your AI models. Our data training platform automates annotation processes. Contact us today to streamline your data ingestion and annotation workflow.
To know more amazing information, keep visiting us!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
