

Transforming Computer Vision: The Rise of Vision Transformers And Its Impact

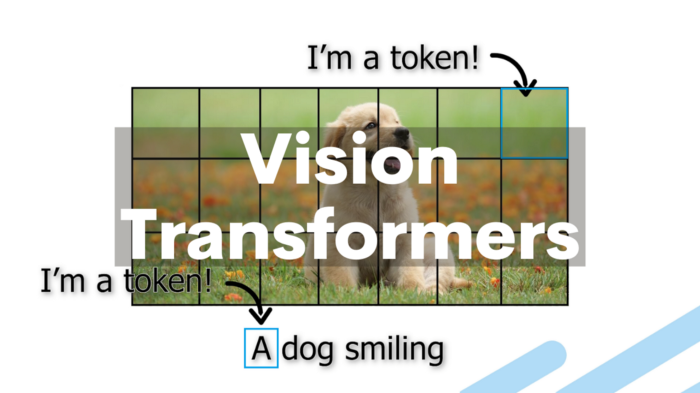
Table of Contents
- Introduction
- ViT vs. Convolutional Neural Networks
- Working of Vision Transformer
- Applications of Vision Transformers
- Benefits of Utilizing Vision Transformers
- Drawbacks of Utilizing Vision Transformers
- Conclusion
- Frequently Asked Questions (FAQ)
Introduction
As introduced by Vaswani et al. in 2017, self-attention-based architectures, particularly Transformers, have become the favored choice in natural language processing (NLP).
The prevailing approach involves pre-training these models on extensive text corpora and fine-tuning them on more specific tasks, commonly referred to as fine-tuning.
Transformers have demonstrated remarkable computational efficiency and scalability, enabling models with unprecedented scale in training, boasting over 100 billion parameters, as seen in works by Brown et al. in 2020. Despite the rapid growth in model sizes and dataset volumes, performance improvements continue unabated.
However, convolutional architectures have retained their dominance in computer vision, tracing back to seminal works like LeCun et al. in 1989, Krizhevsky et al. in 2012, and He et al. in 2016.
Drawing inspiration from the achievements in NLP, various research endeavors have sought to merge CNN-like architectures with self-attention mechanisms, as seen in Wang et al. in 2018 and Carion et al. in 2020.

Figure: Visualizing Attention Mechanism
Some have even attempted to replace convolutions entirely with self-attention, as explored in works by Ramachandran et al. in 2019. However, although theoretically efficient, these latter models have encountered challenges in effective scaling on modern hardware accelerators due to their use of specialized attention patterns.
Motivated by the successful scaling of Transformers in NLP, vision-based transformers, or ViT, directly apply a standard Transformer architecture to images with minimal alterations.
To achieve this, images are divided into patches, and these patches are represented as a sequence of linear embeddings, mirroring the treatment of tokens (words) in NLP applications. The model is trained for image classification in a supervised manner.
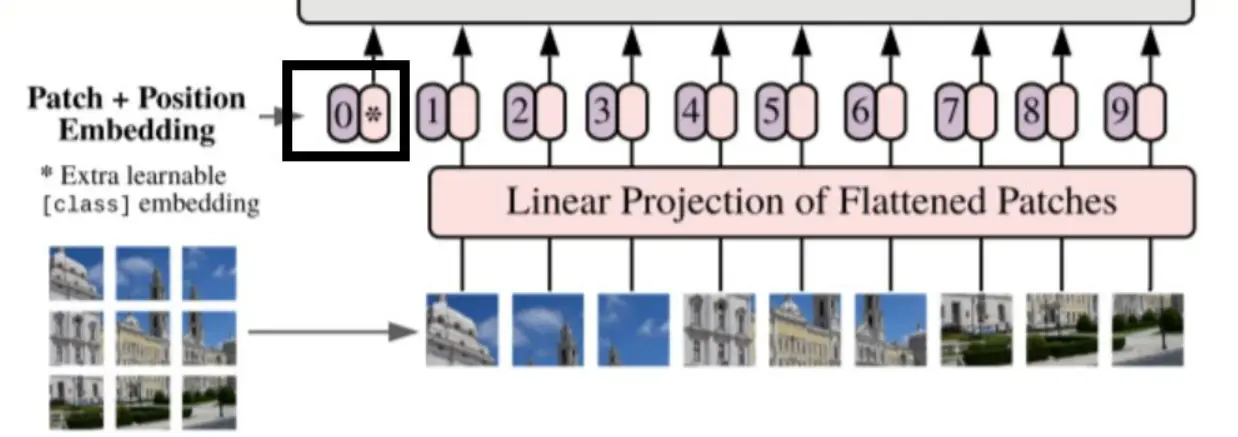
Figure: Converting Images into patches and feeding with positional embeddings
When subjected to training on moderately-sized datasets such as ImageNet without rigorous regularization, these Transformer-based models exhibit performance that falls slightly short, by a few percentage points, compared to ResNets of similar dimensions.
While this outcome might initially seem discouraging, it can be expected because Transformers lack some of the inherent inductive biases in CNNs, such as translation equivariance and locality. Consequently, they require assistance in generalizing effectively when trained on limited data.
However, the scenario changes when the models are trained on larger datasets containing 14 million to 300 million images. We discover that extensive training data surpasses inherent biases.
Vision Transformer (ViT) achieves outstanding results when it is pre-trained on datasets of sufficient scale and then applied to tasks with fewer data points.
When pre-trained on either the publicly available ImageNet-21k dataset or our in-house JFT-300M dataset, ViT competes with or outperforms existing state-of-the-art models on various image recognition benchmarks.
ViT vs. Convolutional Neural Networks
The Vision Transformer (ViT) model takes a novel approach by breaking down an input image into a sequence of image patches, akin to how transformers handle word embeddings in text data. It then directly predicts class labels for the image.
In a 2021 paper titled "Do Vision Transformers See Like Convolutional Neural Networks?" authored by Raghu et al. from Google Research and Google Brain, the distinctions between ViT and the traditional Convolutional Neural Networks (CNNs) are explored. Here, we summarize six key insights from the paper:
- ViT exhibits greater similarity between representations obtained in shallow and deep layers compared to CNNs.
- Unlike CNNs, ViT derives its global representation from shallow layers, yet it also places significance on the local representation from these shallow layers. For example, Consider an image of a beach with a prominent sun (global feature) and seashells scattered in the sand (local features). In ViT, even in the shallow layers, it captures the global view of the beach and the local details of seashells. In contrast, a typical CNN might primarily emphasize the seashells in its shallow layers and only gradually integrate the global context.
- Skip connections in ViT hold even more influence compared to their counterparts in CNNs (such as ResNet), significantly impacting performance and the similarity of representations.
- ViT retains a greater amount of spatial information when compared to ResNet.
- ViT demonstrates the capability to learn high-quality intermediate representations when trained with extensive data.
- The representation produced by MLP-Mixer aligns more closely with ViT than with ResNet.
Understanding these fundamental distinctions between Vision Transformers and Convolutional Neural Networks is crucial as transformer architectures extend their dominance from language models into vision, supplanting CNNs as the go-to choice for visual tasks.
Working of Vision Transformer
In a nutshell, the Vision Transformer (ViT) operates as follows:
- The image is divided into patches.
- These patches are then flattened.
- Lower-dimensional linear embeddings are generated from the flattened patches.
- Positional embeddings are added to the sequence.
- The resulting sequence is used as input for a standard transformer encoder.
- The model is pretrained with image labels on a large dataset.
- It is further fine-tuned on a downstream dataset for image classification.
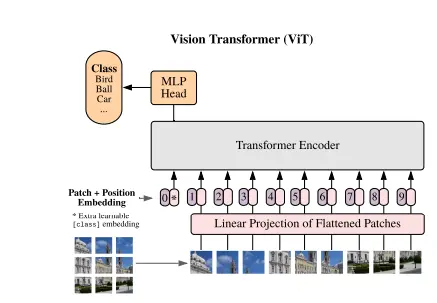
Figure: Architecture of Vision Transformer
Image patches serve as sequence tokens, similar to words in natural language. The encoder block used in ViT is identical to the original transformer introduced by Vaswani et al. in 2017. The main variation lies in the number of these blocks.
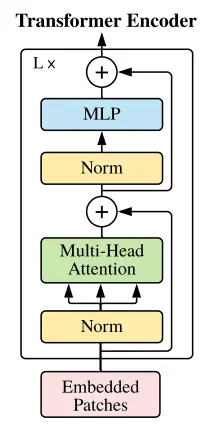
Figure: MLP head for final classification with Transformer encoder.
To demonstrate the scalability of ViT with more data, three different models were proposed, each varying in the number of blocks, multi-head attention, and MLP size.
The embedding size (D) remains fixed across layers to enable short residual skip connections. ViT does not incorporate a decoder; instead, it includes an additional linear layer known as the MLP head for final classification.

Figure: Details of Vision Transformer model variants
However, the effectiveness of ViT depends on having access to a substantial amount of data and the associated computational resources, making it a mixed case of sufficiency and resource dependency.
Applications of Vision Transformers
Vision Transformers (ViTs) have gained substantial attention due to their versatility and scalability, opening up several noteworthy applications:
Image Classification
ViTs have made strides in image classification, particularly on large datasets. While CNN-based methods excel at small to medium datasets by capturing local information effectively, ViTs outperform them on vast datasets by learning a more generalized representation.
Figure: Image Classification
ViTs enable advanced image categorization, generating descriptive captions for images rather than simple labels. They learn comprehensive representations of data modalities, making generating text descriptions for images possible.
Image Segmentation
Intel's DPT (DensePredictionTransformers) is an example of using ViTs for image segmentation. It achieves impressive performance, such as 49.02% mIoU on ADE20K for semantic segmentation and improved monocular depth estimation compared to traditional fully-convolutional networks.
Anomaly Detection
Transformer-based models are employed in image anomaly detection and localization networks. These models use a reconstruction-based approach and patch embedding to preserve spatial information, facilitating detection and localizing anomalous areas within images.
Action Recognition
ViTs have found applications in video classification for action recognition. Google Research has explored pure-transformer-based models for this purpose, extracting spatiotemporal tokens from input videos and encoding them using transformer layers. They have also proposed efficient variants to handle long video sequences and train on relatively small datasets.
Autonomous Driving
In the realm of autonomous driving, Tesla has incorporated Transformer modules, specifically cross-attention modules, into their neural network architecture. These modules play a vital role in tasks like image-to-BEV (Bird's Eye View) transformation and multi-camera fusion, contributing to advanced autonomous driving capabilities.

Figure: Autonomous Driving
These diverse applications underscore the broad potential of ViTs in addressing various computer vision challenges and tasks across different domains.
Benefits of Utilizing Vision Transformers
Using Vision Transformers (ViTs) for image classification offers several advantages:
- Global Feature Learning: ViTs can grasp global features of images by attending to any part of the image, regardless of its location. This capability proves valuable for tasks like object detection and scene understanding.
- Robustness to Data Augmentation: ViTs exhibit reduced sensitivity to data augmentation compared to Convolutional Neural Networks (CNNs). Consequently, they can be effectively trained with smaller datasets.
- Versatility: ViTs are versatile and adaptable, making them suitable for various image classification tasks, including object detection, object recogonition, and image segmentation.
Drawbacks of Utilizing Vision Transformers
However, there are several drawbacks associated with the use of Vision Transformers for image classification:
- High Computational Cost: Training ViTs is computationally expensive due to their substantial parameter count, which can result in lengthy training times.
- Inefficiency in Image Processing: ViTs may not be as efficient as CNNs when processing images because they attend to every part of the image, including areas that may not be relevant to the specific task at hand.
- Lack of Interpretability: ViTs may lack the interpretability of CNNs, making it challenging to comprehend how they arrive at their predictions. This can hinder the understanding of their decision-making processes.
Conclusion
In conclusion, the advent of self-attention-based architectures, notably Transformers, marked a pivotal moment in the field of natural language processing (NLP).
These architectures, introduced by Vaswani et al. in 2017, swiftly gained prominence for their exceptional ability to efficiently process vast amounts of text data.
They were pre-trained on extensive text corpora and fine-tuned for specific NLP tasks, consistently achieving remarkable results. Transformers demonstrated remarkable computational scalability, boasting models with over 100 billion parameters, as exemplified by works like Brown et al. in 2020.
However, the story differed in computer vision, where convolutional neural networks (CNNs) had long held sway.
CNNs, with their roots tracing back to seminal works in the late 20th century, retained their dominance. Yet, inspired by the success of Transformers in NLP, researchers sought to bridge the gap between CNNs and self-attention mechanisms.
Some even ventured to replace convolutions entirely with self-attention, albeit encountering scaling challenges due to specialized attention patterns.
The turning point came when vision-based Transformers, known as Vision Transformers (ViT), emerged. These models applied the Transformer architecture to images with minimal modifications, primarily by dividing images into patches, akin to handling text tokens.
When subjected to training on substantial datasets, ranging from 14 million to 300 million images, ViT showcased its prowess. It excelled when pre-trained on large-scale datasets and then fine-tuned for tasks with limited data points, reaching or surpassing state-of-the-art results in various image recognition benchmarks.
ViT's distinctiveness became evident when compared to traditional CNNs. It exhibited greater similarity between representations in shallow and deep layers, capturing both global and local features effectively even in early layers.
Skip connections in ViT played a significant role in enhancing its performance and retained a substantial amount of spatial information. ViT proved its ability to learn high-quality intermediate representations, and its representations aligned more closely with models like MLP-Mixer.
The operational principle of ViT involved breaking down images into patches, generating lower-dimensional embeddings, adding positional information, and using a standard Transformer encoder.
ViT's effectiveness varied with data scale and computational resources, underscoring its mixed dependency on sufficiency and available resources.
ViT found applications across diverse domains, including image classification, captioning, segmentation, anomaly detection, action recognition, and autonomous driving.
Its benefits encompassed global feature learning, robustness to data augmentation, and versatility across image classification tasks. However, challenges persisted, including high computational costs, potential processing inefficiencies, and limited interpretability.
In conclusion, integrating self-attention-based architectures like Vision Transformers into computer vision represents a transformative shift.
This journey from NLP to computer vision underlines the adaptability and potential of Transformer models across different domains. As they continue to evolve, Transformers are poised to redefine the landscape of visual tasks, gradually supplanting traditional CNNs as the preferred choice for various computer vision challenges.
Frequently Asked Questions (FAQ)
1. Do Vision Transformers surpass CNNs in performance?
The Vision Transformer (ViT) demonstrates superior results in several benchmarks compared to state-of-the-art convolutional networks, and it achieves this with reduced computational resource requirements, especially when it is pre-trained on extensive datasets.
2. How do CNNs and Vision Transformers differ?
CNNs, being a more established architectural framework, are more straightforward to explore, execute, and train when compared to Transformers. CNNs employ convolution, which is a "local" operation confined to a limited image area. In contrast, Visual Transformers utilize self-attention, constituting a "global" operation as it gathers insights from the entire image.
3. Can Vision Transformer be classified as a deep learning model?
To put it plainly, a vision transformer is indeed a deep learning model. It adapts transformers, initially created for natural language processing, to perform image recognition tasks.
Its approach involves dividing an image into patches, subjecting them to transformer processing, and then consolidating this information for purposes like classification or object detection.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
