

5 Image Data Augmentation Techniques To Mitigate Overfitting In Computer Vision

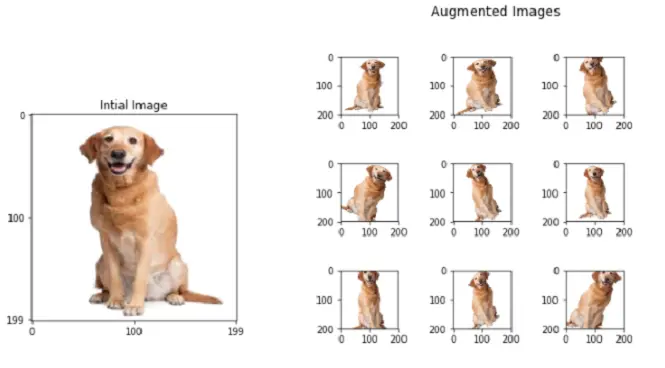
Deep Convolutional Neural networks have been shown to be effective for a variety of computer vision applications in a variety of fields, including autonomous vehicles, medical imaging, etc. However, in order for these networks to function exceptionally well in real-world situations, they greatly rely on big quality data. But how large a set of data must be for a good model to exist? Data is one area where there is little doubt: the more high-quality data you have, the better it is. You can even take help from a professional training data platform that gives your work the access of expert labelers. To eliminate any lingering questions, we will use an image augmentation strategy to increase the volume of training data, preventing our model from generalizing the training visual data.
What is data augmentation?
Data augmentation is the technique of creating additional data points from current data in order to artificially increase the amount of data. In order to amplify the data set, this may involve making small adjustments to the data or utilizing machine learning methods to produce new sets of data in the generative model of the original data.
Importance of data augmentation
Here are a few of the factors that have contributed to the rise in popularity of data augmentation approaches in recent years.
1. It enhances the effectiveness of machine learning models (more diverse datasets)
Practically every state-of-the-art deep learning application, including object identification, picture classification, image recognition, understanding of natural language processing, semantic segmentation, and others, makes extensive use of data augmentation techniques.
By creating fresh and varied examples for training datasets, augmented data is enhancing the efficiency and outcomes of deep learning models.
2. Lowers the expense of running the data collection operations
Deep learning models may require time-consuming and expensive operations for data collecting and data labeling. By adopting data augmentation techniques to change datasets, businesses can save operating costs.
All about deep learning models that you should know: read here
How does overfitting occur and what causes it?
When a model is trained, the validation errors get smaller if the model can pick up on the underlying job. Overfitting occurs when the model repeatedly learns trends from training data that are unable to generalize to the test data, causing the training error to keep declining while the errors on the test/hold-out data grows.
Issues caused by insufficient image data
Overfitting has several primary causes, one of which is access to a very small amount of good quality training data.
The better it is for us to have more high-quality data, yet acquiring such data can be very costly and time-consuming.
Strong computer vision models ought to be unaffected by slight image modifications (such as translation and rotation). If a model can identify an image on the left, we might also want it to identify an image on the right. However, this is not always a given unless the model has been specifically trained to do so.
Get to know more about data augmentation and how to train your model with limited data :Read here
Simple image augmentation methods and examples
The quantity of the data can be increased by using these five primary picture modification techniques. To help you comprehend all of these strategies, examples will be provided.
- Geometric transformations
2. Color space adjustments
3. Random erasure
4. A kernel filter
5. Mixing images
1. Geometric transformations
Prior to utilising this method, it is critical to comprehend which data alterations are appropriate for maintaining the label (e.g. for digit recognition, flipping 6 in some way might turn into 9).
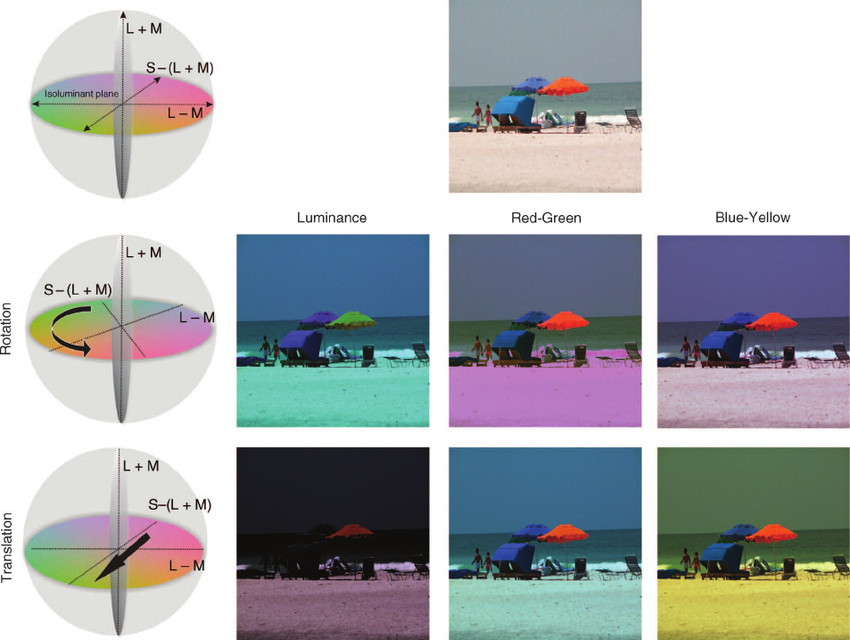
2. Colorspace Transformation
Brightness and contrast adjustments are probably the most popular methods, but this technique has a wide range of potential applications and provides more room for creativity in image transformation.
3. Random erasure
The label may not be preserved using this method, much like with the geometric transformation. However, it is intriguing since it compels the model to focus on the entire image as opposed to a portion of it. For instance, the model might not be able to identify the elephant by simply glancing at its face since it might be blacked out, which causes the model to consider the entire scene. The dropout approach, a regularisation method that zeroes out a random portion of weights in a neural network layer, served as the model for this methodology. Additionally, it aids in resolving occlusion or unclear test picture concerns (e.g. some part of an image hidden by a object or something else).

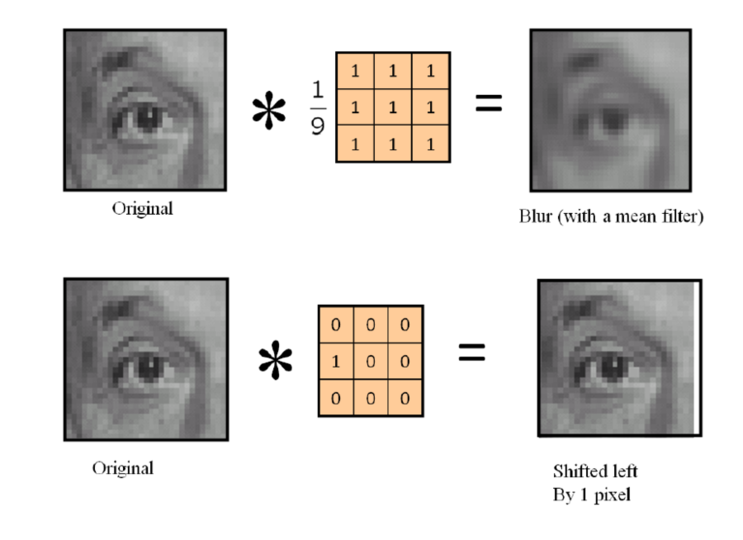
4. A kernel filter
These methods are frequently used to apply filters to sharpen or blur photographs. They employ a NxN kernel, which is similar to how Convolutional Neural Nets operate internally (CNN). Additionally, when all of the photographs in the training set have an identically high level of sharpness, they are excellent for strengthening the model's resistance to motion shots.
5. Mixing images
Two techniques for combining photos include pixel averaging (mixup) and overlapping crops (Cut-Mix). Let's think about pairing the elephant with the picture of the forest on the right.
Best practices, tips, and techniques
It's important to note that even while DA is a strong tool, you should use it with caution. When using augmentations, you may want to go by the following general guidelines:
- Pick the right augmentations for the task: Imagine that you are attempting to identify a face in a picture. Your model suddenly performs poorly even throughout training when you select Random Erasing as an augmentation strategy. This is due to the augmentation process randomly erasing the face from an image. The same is true for voice recognition and the addition of noise injection to the tape. When selecting DA approaches, keep these scenarios in mind and use reasoning.
- In one sequence, avoid using too many augmentations. You could just make a brand-new observation with nothing to do with your prior training (or testing data)
- Before beginning training on data, view the augmented data (pictures and text) in the notebook and listen to the transformed audio sample. Making a mistake when creating an augmenting pipeline is rather simple. It is therefore always advisable to confirm the outcome.
The training data size may therefore expand if these techniques are used to all of the photos inside it. To use the strategies that keep the labels, it is crucial to comprehend the data, nevertheless.
If you need more assistance to train your computer vision model, then you can connect with us. We are a training data platform that helps in training high-quality data. We have a team of high-skilled annotation experts. Alongside, we are also proficient with large scale custom data collections covering audio, image, testing, sentiment and point of interest. We help you generate data artificially, giving you access to hard-to-find or edge-case data.
If you are looking for a platform that can serve you the best purpose in your data training project, then we are here to help.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
