

6 Open-Source Datasets For Multimodal Generative AI Models
Explore 6 open-source datasets designed to train generative AI models across text, images, and audio, enhancing multimodal AI applications.


Table of Contents
- Introduction
- Why are multimodal generative AI models important?
- InternVid
- Flickr30k
- MuSe
- VQA
- Social IQ
- RGB-D Object Dataset
- Conclusion
- Frequently Asked Questions
Introduction
Today, there are various AI tools designed to handle a wide range of different tasks.
But what if there is a single that can write your content, design your visuals, and even compose music for your brand—all at once.
This isn’t the future; it’s happening now with multimodal generative AI models.
Multimodal generative AI models are a cutting-edge development to artificial intelligence that allows at creating content across multiple models, such as text, images, and audio.
Unlike traditional models that focus on a single data type, multimodal generative models leverage the complementary nature of different modalities to generate richer and more coherent outputs.
These models enable tasks like image captioning, text-to-image synthesis, and speech-to-image generation, where the AI system can understand and create content that seamlessly integrates across various forms of data.
By using the power of multimodal data, these models hold promise for enhancing human-computer interactions, facilitating content creation, and advancing creative applications in areas like art, design, and storytelling.
However, training these powerful models requires vast amounts of data that bridges the gap between different modalities.
This is where open-source datasets come into play, democratizing access to the fuel that drives multimodal innovation.
These datasets serve as the foundational building blocks upon which these sophisticated models are trained, refined, and validated.
By providing a rich dataset of multimodal data encompassing images, text, audio, and more, these datasets empower researchers and developers to push the boundaries of AI capabilities.
In this article, our team of AI experts researched and came up with the top open-source datasets for multimodal generative AI models.
These datasets are crucial due to their diverse content, detailed annotations, and broad applicability, providing a rich mix of text, images, and audio for generating complex and meaningful content.
We have also explored couple of multimodals you can check our findings and what could be a better model for you here: Evaluating and Finetuning Text To Video Model
Why are multimodal generative AI models important?

Multimodal generative AI models are a significant advancement in AI technology because they bridge the gap between how humans perceive and interact with the world.
Unlike traditional generative models that operate on a single data type, like text or images, multimodal models can process and combine information from various sources.
This allows for a better understanding of user intent and enables them to generate outputs that seamlessly blend different modalities.
Imagine describing a scene to a friend using words and gestures. This is essentially what multimodal AI does.
Processing a text description and potentially a reference image can generate a more comprehensive and creative output, like a new image or even a video that captures the essence of your description.
Examples of various multimodal generative models include LLava, Mistral, and ImageBind. These AI systems can analyze and combine text and images, allowing them to generate captions for pictures, answer questions about visual content, or even create new images based on a textual description.
Top open-source datasets for multimodal Generative AI model
1) InternVid

InternVid is an important resource in multimodal generative AI datasets, meticulously crafted to push the boundaries of video and text understanding.
With an impressive scale of 7 million videos, totaling a staggering 234 million clips paired with meticulously generated captions, this dataset offers great depth for training cutting-edge AI models.
Technical Insights:
- Multimodal Fusion: InternVid consists of the fusion of video and text at scale, presenting a lot of computational features.
From video-text correlations to nuances in visual aesthetics, the dataset consists of the complexity of multimodal interactions. - Scene Diversity: Spanning 16 diverse scenes and around 6 thousand distinct actions, InternVid ensures comprehensive coverage of real-world scenarios.
This diversity not only enriches training but also primes AI models for robust performance across varied contexts. - Rich Descriptive Annotations: Delving deeper, InternVid offers millions of video clips paired with meticulously crafted textual descriptions.
These annotations serve as invaluable guides, empowering machines to decipher textual instructions and synthesize corresponding visual narratives effectively.
Technical Applications:
- Revolutionizing E-Learning: InternVid makes the way for a major change in e-learning platforms. Imagine AI-powered systems that dynamically generate personalized video tutorials tailored to individual learning styles.
Textual analysis in real-time allows for seamless transitions between textual explanations and corresponding visual demonstrations, creating a truly interactive learning experience. - Video-Centric Chatbots: InternVid empowers the development of next-generation video-centric chatbots.
By training AI models on this rich dataset, chatbots can interpret textual prompts and respond with relevant video clips, fostering a more immersive and engaging user experience. - Surveillance Systems: InternVid can significantly enhance traditional surveillance systems.
By simultaneously analyzing video feeds and textual descriptions, AI models can gain a deeper understanding of the environment, facilitating real-time threat detection and response.
2) Flickr30k

Flickr30k Entities emerges as an important dataset, that is crafted to unravel the complex patterns between visual stimuli and textual descriptions.
Beyond just image-caption pairs, this dataset serves as a goldmine of knowledge, fostering an understanding of the semantic connections inherent in visual content.
Technical Insights:
- Comprehensive Composition: Comprising 31,000 curated images sourced from Flickr, each accompanied by a suite of 5 reference sentences crafted by human annotators, Flickr30k Entities goes beyond the traditional image-caption datasets.
Its true innovation lies in the integration of bounding boxes and entity mentions. - Annotation: By incorporating bounding boxes, Flickr30k Entities facilitates precise object localization within images, empowering AI models to learn and annotate individual objects with pinpoint accuracy.
- Enhanced Semantic Understanding: This combination of textual and visual annotations allows AI models to have a greater comprehension of image content.
With this rich contextual information, models not only generate better image descriptions but also identify and name specific objects.
Technical Applications:
- Real-time Image Accessibility: Using the Flickr30k-trained models, mobile applications can overcome traditional boundaries by offering real-time image descriptions tailored for visually impaired users.
Imagine a scenario where a person points their smartphone camera at an object and immediately hears a clear, short voice description of what it is. This helps make information more accessible and inclusive for everyone - Revolutionizing Image Search: By training image search engines with Flickr30k , the gap between textual queries and visual content is reduced.
User query descriptions become more important, enabling users to articulate their search intent with more clarity, precision, and contextually relevant search results. - Immersive Educational Experiences: Leveraging the semantic richness of Flickr30k dataset, developers can create educational applications that improve the lines between the physical and digital realms.
3) MuSe
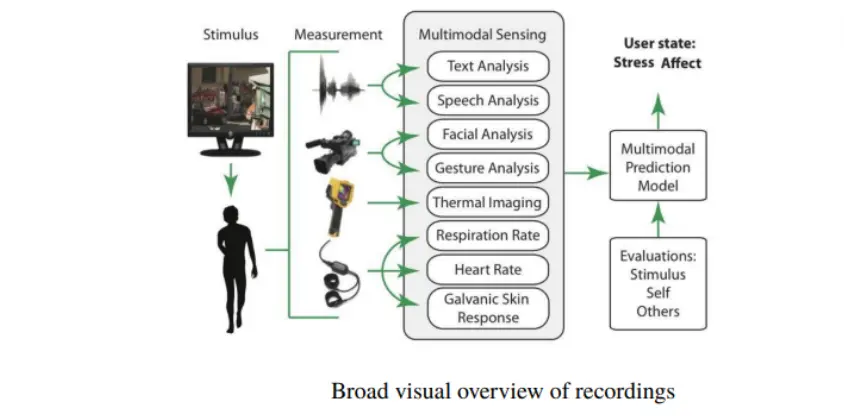
MuSe (Multimodal Semantic Understanding) is a designed to process and generate human-like responses across different models, such as text, images, and audio.
It features different scenarios with annotations that contains complexities of human stress.
The dataset supports various tasks, including dialogue generation and image captioning, making it an essential resource for researchers focused on multimodal AI.
Technical Insights:
- Multimodal Fusion at Scale: MuSe represents a dataset that includes seamlessly integrating audio and visual recordings of individuals undergoing stress.
Each recording is meticulously annotated, offering rich insights into emotional content that enable AI models to explore expressions of distress across different sensory modalities. - Emotional Annotation Enrichment: The raw data provide invaluable insights into the subtle nuances of stress expression.
These annotations serve as a roadmap for AI models, enabling them to understand not only the overall visual cues, like facial expressions but also subtle vocal audio indicative of stress.
Technical Applications:
- Driver Drowsiness Detection: Integrating MuSe data into in-car systems unlocks the potential for real-time analysis to detect driver drowsiness.
This approach could reduce accidents by triggering alerts prompting drivers to pull over and rest, leveraging AI to safeguard lives on the road. - Workplace Wellness Initiatives: Leveraging MuSe, companies gain real-time insights into employee stress levels during high-pressure scenarios.
Organizations can implement targeted interventions such as offering relaxation areas or guiding employees through mindfulness exercises, fostering a culture of well-being and resilience. - Dynamic Educational Platforms: Educational platforms use the power of MuSe-trained AI to monitor student stress levels in real time during online learning sessions.
Adaptive algorithms adjust the difficulty of learning materials or recommend breaks based on detected stress levels, fostering a supportive learning environment tailored to individual needs.
4) VQA

The Visual Question Answering (VQA) dataset is a benchmark that challenges AI models to answer questions based on images.
It consists of thousands of images paired with questions requiring an understanding of both visual content and natural language. The questions range from simple identification to complex reasoning tasks.
VQA is crucial for improving your model's capabilities in visual reasoning, enabling applications in areas like interactive AI, image retrieval, and content generation.
Technical Insights:
- Image Diversity: VQA datasets encompass a wide range of image types, including everyday scenes, objects, and abstract concepts. This ensures the model can generalize its understanding to diverse visual inputs.
- Question Formulation: The way questions are formulated can significantly impact model performance.
Datasets may include questions phrased in natural language, grammatically correct questions, or specific question templates to encourage a consistent format for training. - Answer Grounding: Some datasets might include annotations that "ground" the answer within the image.
This could involve bounding boxes around answer-relevant objects or highlighting specific image regions that support the answer.
Technical Applications:
- Visually Aware Smart Assistants: Imagine a virtual assistant that leverages VQA capabilities. You could ask, "What color is the flower on the table?" while pointing your phone camera at the scene.
The assistant would analyze the image, understand the question's context, and answer accurately using its VQA-trained understanding. - Interactive Visual Learning: VQA can revolutionize education. Students could point a camera at objects or diagrams in textbooks and receive real-time explanations from a VQA-powered system.
Alternatively, they could pose questions about the visuals, fostering a more interactive and engaging learning experience. - Enhanced Customer Support Chatbots: VQA datasets can empower customer service chatbots. Users could submit images of faulty products or unclear instructions.
The VQA-powered chatbot would then analyze the image, understand the issue, and provide relevant solutions or troubleshooting steps, streamlining customer support interactions.
5) Social IQ

Social IQ is a dataset created to understand social interactions and human behavior through multimodal inputs.
It includes scenarios that shows various social contexts, complete with annotated dialogues and images.
You can use this dataset to interpret emotions, intentions, and social cues, helping the development of models that can provide empathetic and context-aware responses.
By focusing on real-world interactions, Social IQ helps enhance the AI’s ability to engage in nuanced conversations, making it vital for researchers exploring the intersection of social intelligence and generative models.
Technical Insights:
- Multimodal Data: These datasets go beyond text. They typically consist of video recordings paired with open-ended questions.
The videos capture real-world social interactions, including visual cues (body language, facial expressions), audio (tone of voice), and potentially textual elements within the scene (e.g., signs, written content). - Open-Ended Questions: Unlike traditional machine learning tasks with predefined answer sets, Social IQ datasets utilize open-ended questions that test a model's ability to reason and infer meaning from the social cues within the video.
This pushes AI models beyond basic language processing and image recognition, requiring them to grasp the intricate dynamics of human interaction. - Grounded Inference: Social IQ datasets aim to train AI models for "grounded inference." This means the model isn't just identifying objects or actions but also understanding the social context behind them.
For instance, analyzing a handshake and inferring the social purpose (greeting, business deal, etc.) based on the surrounding visual and audio cues.
Technical Applications:
- Personalized Social Media Feeds: Imagine social media platforms that curate content recommendations based on your current emotional state, interests, and even the social dynamics within a post (e.g., playful banter vs. heated debate).
Social IQ data can empower AI to understand these nuances and personalize your feed accordingly. - Emotionally Intelligent Chatbots: Customer service chatbots equipped with Social IQ can analyze a customer's sentiment in real time through text and potentially vocal cues.
This allows the AI to tailor its responses, offering empathetic support and escalating complex situations to human agents when needed. - AI-powered Education: Social IQ datasets can be used to train AI tutors who can identify a student's emotional state and adjust their teaching style accordingly.
This personalized approach can foster a more engaging and effective learning experience.
6) RGB-D Object Dataset

The RGB-D Object Dataset provides support for training AI models that use both RGB (color) and depth (D) information.
It features a wide variety of objects, each captured in both color and depth, along with detailed annotations like class labels and 3D pose data.
This approach can be used in tasks such as object recognition and contextual understanding, allowing models to better understand and interact with their environment.
RGB-D Object Dataset significantly enhances its use in robotics and augmented reality.
Technical Depth:
- Beyond RGB Channels: Unlike traditional RGB datasets that capture only color information, the RGB-D Object Dataset incorporates depth data.
Depth sensors measure the distance of each pixel from the camera, creating a 3D representation of the scene. This is crucial for tasks like: - 3D Object Recognition: AI models using this dataset can not only identify objects based on color but also understand their shape and size due to the depth information.
- Precise Object Localization: Depth data allows models to pinpoint the exact location of objects within the scene, essential for tasks like robotic grasping and manipulation.
- Sensor Calibration: The dataset provides meticulously calibrated RGB and depth channels, ensuring perfect alignment for accurate 3D reconstruction.
This eliminates errors caused by misalignment between the camera and depth sensor. - Multiple Viewpoints: Each object is captured from three different viewpoints, providing the AI model with a more comprehensive understanding of the object's 3D structure from various angles. This is particularly beneficial for tasks where object orientation is crucial.
Technical Applications:
- Enhanced Smart Home Systems: RGB-D Object Dataset revolutionizes smart home ecosystems by enabling real-time object recognition and interaction.
Equipped with RGB-D cameras, AI-powered systems objects based on depth and color data, facilitating intuitive commands like "Turn off the lamp on the table," where the system identifies and interacts with specific objects with precision and efficiency. - Real-time Robotic Autonomy: Robotics enters a new era with RGB-D Object Dataset, empowering robots to navigate and manipulate their environments with unparalleled precision.
Conclusion
The open-source datasets highlighted above are crucial for companies looking to enhance their AI models.
These datasets offer a wealth of diverse, high-quality data that can significantly improve the training of multimodal generative AI models.
By leveraging these resources, companies can unlock new opportunities for innovation across natural language processing, computer vision, and multimedia content generation.
As AI technology continues to advance, integrating these open-source datasets with cutting-edge AI models will drive progress and open up new possibilities.
If you're also looking to push the boundaries of AI and explore new creative and interactive solutions, these datasets are a valuable asset for your projects.
If you need any assistance or have questions about using these datasets, Labellerr is here to help. Reach out to us for expert support and guidance to make the most out of your AI projects.
You can explore other open-source multimodal datasets here.
Frequently Asked Questions
Q1) What are multimodal generative AI models?
Multimodal generative AI models are advanced artificial intelligence systems capable of understanding and generating content across multiple modalities, such as text, images, and audio.
These models leverage the complementary nature of different data types to produce richer and more coherent outputs.
Q2) Why are multimodal generative models important?
Multimodal generative models are important because they enable more natural human-machine interactions and facilitate a holistic understanding of multimodal data.
They unlock new possibilities for innovation in areas such as assistive technologies, multimedia content generation, and creative design.
Q3) What role do open-source datasets play in training multimodal generative models?
Open-source datasets serve as invaluable resources for training multimodal generative models.
They provide diverse and extensive collections of multimodal data, enabling researchers and developers to build robust and scalable models without the need for proprietary datasets.
References:
1) InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation.(Link)
2) Making the V in VQA Matter: Elevating the Role of Image Understanding in Visual Question Answering(Link)
3) Flickr30K Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models(Link)
4) Social-IQ: A Question Answering Benchmark for Artificial Social Intelligence(Link)
5) MuSE: a Multimodal Dataset of Stressed Emotion(Link)

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
