

Synthetic Data: Type And Real-Life Examples


Data that has been artificially annotated is known as synthetic data. It is produced via simulations or computer algorithms. When genuine data is unavailable or needs to be kept hidden due to compliance risks or personally identifiable information (PII), synthetic data production is typically used. The healthcare, manufacturing, agricultural, and e-commerce industries all use it extensively. In this blog, we have mentioned different types of synthetic data and 4 real-life examples from 2022.
What is synthetic data?
Synthetic data is information that is produced artificially rather than by genuine methods. It is frequently developed with the use of algorithms and is applied to a variety of tasks, such as test data for new tools and products, model validation, and training AI models. One sort of data augmentation is synthetic data.
Importance of synthetic data
The power of synthetic data to provide features that otherwise wouldn't be possible with real-world data makes it crucial for a variety of applications. Synthetic data is a lifesaver when real data is scarce or when maintaining anonymity is of the utmost importance.
The artificial intelligence (AI) business industry is heavily dependent on this data.
- For assessing some disorders and circumstances when genuine data is lacking, the healthcare and medical industry use fake data.
- Artificial data is used to train self-driving Uber and Google vehicles.
- Fraud protection and detection are of utmost importance in the financial sector. Synthetic data can be used to investigate new fraudulent situations.
- Data professionals can access and utilise centrally stored data while still protecting its anonymity thanks to synthetic data. Synthetic data has the ability to mimic the key characteristics of genuine data without divulging its true meaning, maintaining privacy.
- In the research division, synthetic data enables you to create and offer cutting-edge goods for which the essential data might not otherwise be accessible.
Benefits of synthetic data
1. Full user control over synthetic data
In a simulation using synthetic data, everything is controllable. It has both blessings and drawbacks. Because there are instances where edge circumstances that can be recorded in real datasets are missed by synthetic data, it can be a curse. You might wish to use transfer learning for these applications to mix some actual data with the synthetic datasets.
However, this is also a benefit because you may choose the event frequency, item distribution, and much more.
2. The annotation of synthetic data is flawless
The flawless annotation offered by synthetic data is another benefit. Never again will manual data collection be necessary.
Each object in a scene can automatically create a variety of annotations. This might not seem like a significant concern, but it's a major factor in the low cost of synthetic data in comparison to real world data. The labelling of data is free. Instead, the initial expenditure in creating the simulation is the primary cost of using synthetic data. The cost-effectiveness of creating data over genuine data increases rapidly after that.
3. Synthetic data is generally multispectral
Companies that manufacture autonomous vehicles have learned how difficult it is to annotate non-visible data. They have therefore been among the strongest supporters of synthetic data.
Many businesses produce fictitious LiDAR data using simulations. Because it is synthetic, the data is already categorized and the ground truth is known. For computer vision applications using infrared or radar imaging, when humans can't completely interpret the imagery, synthetic data works well.
Methods of generating synthetic data
There are two methods for creating Synthetic data.
Basically, there are two approaches to get synthetic data. Use Generative models or traditional methods: specialised equipment and software together with data acquisition from other sources.
Both approaches can be used to produce various kinds of synthetic data. But before getting started, let's first quickly describe the most popular generative models and the applicable traditional techniques.
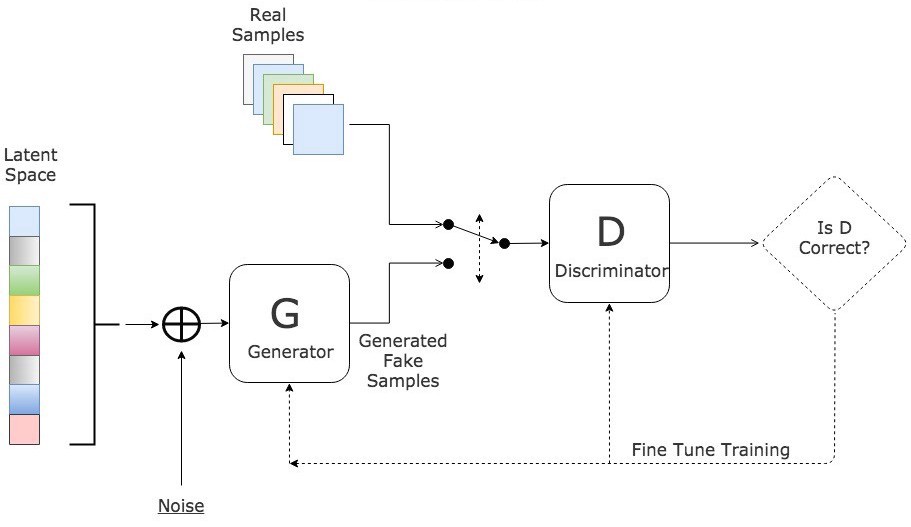
1. Generative adversarial networks (GANs)
.webp)
Deep learning generative algorithms called GANs produce new data points that mimic the training data. GAN consists of two parts: a generator that learns to produce false data and a discriminator that absorbs the false data into its learning process.
Over time, GANs have become more often used. They can be employed for dark-matter studies to replicate gravitational lensing and enhance astronomy photos. In order to recreate low-resolution, 2D textures at classic video games in 4K or higher resolutions, video game producers use GANs. GANs aid in producing cartoon characters and realistic images, taking pictures of real humans, and rendering 3D objects.
- The discriminator gains the ability to discriminate between the real data sample and the generator's bogus data.
- The generator creates bogus data during early training, and the differentiator quickly picks up on the fact that it is untrue.
- In order to update the model, the GAN delivers the outcomes to the discriminator and the generator.
VAEs, or variational auto-encoders, concentrate on discovering connections in the data set. In a similar manner, they recreate the set's data points while also creating fresh variations. Variational auto-encoders can be used to create a variety of complicated data types, including handwriting, faces, pictures, and tabular data.
The family of models known as autoregressive models, or ARs, is specifically devoted to time - series data and data sets having time-based measurements. By projecting future variables based on historical values, AR models generate data. They are frequently employed to predict future events, particularly in the economic and environmental sciences. They are frequently used to create artificial time series data.
2. Conventional techniques
Conventional approaches include working with a third - party provider that provides these services or producing synthetic data using software or other tools. Free software and tools can satisfy testing requirements, but they might not be sufficient for optimal content performance. Additionally, using this approach would call for the organization to have an IT resource.
Synthetic data types
As we previously stated, computer vision generative models and traditional methods of generation are applicable to all forms of synthetic data. Here, we've outlined five major categories, each of which specifies the methodology, tool, and software that should be used to the creation along with the sources of synthetic data.
1. Generation of tabular data
Tabular data typically contains much more private and sensitive information than other forms. It needs to be synthesised rather than just anonymized for these reasons. Data must be anonymized by removing any identifying attributes from the data set. But it's a tough process.
Some identifying information in the collection, such as name, address, and sex, needs to be eliminated in order to make the data anonymous. We have less meaningful data for upcoming analysis as we delete more data. And even after erasing a lot of the same person's private information, it is still able to determine someone using the scant information that is still available.
We should use GANs and their dedicated models, such as CTGAN, WGAN, and WGAN-GP, which all concentrate on tabular synthesis, to produce tabular data. The Synthetic Data Vault is a platform that provides libraries for simple learning of tabular data synthesising. Additionally, there are companies like MOSTLY AI, GenRocket, YData, Hazy, and MDClone that offer tabular synthetic data. The final one focuses on artificial medical data.
Tabular data synthesis has a wide range of uses, including in the financial sector for detecting fraud and economic forecasting, in the fields of insurance and healthcare for client and event studies, in social media for user behaviour, in streaming services for behaviour and a set of recommendations, and in promotional campaigns for consumer behaviour and responses.
2. Generation of time series data
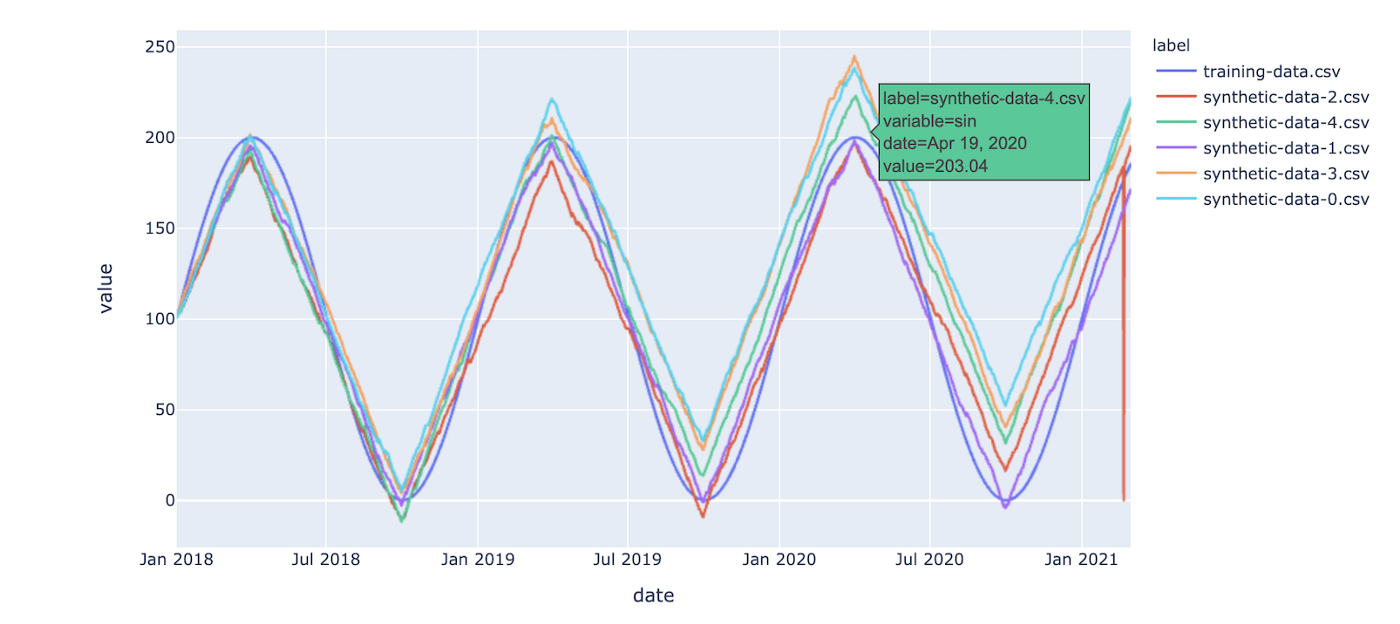
In some aspects, time series synthetic data can be compared to tabular data, but the fundamental distinction between them is that time series is focused on information that is associated with the time component. Autoregressive models (AR), which specialise in time series data, can be used by anyone to generate it with models. For synthesis, there seem to be GANs and a TimeGAN that is more temporally focused.
Time series synthetic data is most frequently used in the areas of financial forecasting, demand forecasting, commerce, market forecasting, transaction recording, nature forecasting, component monitoring in machines, and robotics.
In summary, algorithms can learn patterns, make predictions about the future, and spot abnormalities using time series data. Most tabular data providers also provide time series synthetic data, as the two features frequently coexist and benefit from each other. As a result, providers typically provide both options.
3. Data generation for images and videos
There are countless uses for synthetic picture and video data, and there are countless methods in which it might be put to use. But there are two significant branches that we can identify that call for visual data synthesis. They are face generation and computer vision.
A machine learns how to comprehend what it sees through the computer vision procedure in order to carry out a certain activity. The robotics and automobile sectors have a significant demand for it. Both of which depend on computers to discern between background and objects as well as their sizes and distances from one another.
4. Data generation for Text
Less frequently used in business, text and sound synthetic data are more commonly used in research and creative endeavours. However, textual data can be used to train chatbots, algorithms that scan email for spam, or machine learning models that recognise abuse, for example.
The text generation model GPT-3 merits addressing when discussing synthesised text. Generative Pre-trained Transformer 3 is what it's called. To train machine learning models for text recognition or interpretation, GPT-3 is an autoregressive model that creates text that sounds like human speech. There is also the web utility Text Generation API, which generates brief text paragraphs depending on input using the GPT-2 model.
5. Sound data generation
Similar to textual synthetic data, services for sound synthesis are not frequently provided. That may be true because using specialised software to create and manipulate a certain frequency does not necessitate synthesising it. Professional alternatives like Ableton Live and iZotope, coding-focused ones like Max and Pure Data, and a very basic one like Audacity are all available.
Text-to-speech systems for services and general speech administration for robotics could both benefit from synthetic sound data. There are several ways to obtain this data for machine learning training, but Google's Text-to-Speech service is one of the most well-liked. It features a variety of genders, tongues, and English accents.
Here are a few examples from the actual world when synthetic data is employed.
- Healthcare: Organizations in the healthcare industry develop models using synthetic data and test a range of datasets for problems for which there is no actual data. Artificial intelligence (AI) models are being trained in the area of medical imaging while always maintaining patient privacy. In addition, they are using synthetic data to foresee and predict disease trends.
- Agriculture: Applications for computer vision that help predict crop yield, identify crop diseases, identify seeds, fruits, and flowers, model plant growth, among other things, can benefit from synthetic data.
- Banking and finance: By using synthetic data to create new, effective fraud detection techniques, data scientists can help banks better detect and prevent online fraud.
- E-Commerce: By adopting cutting-edge machine learning models developed on synthetic data, businesses can profit from effective inventory and warehousing management as well as better online shopping experiences for their customers.
- Manufacturing: Businesses use synthetic data for quality assurance and predictive maintenance.
- Disaster forecasting and risk management: Governmental entities use artificial data to forecast natural disasters in order to reduce risks and prevent disasters.
- Automotive and robotics businesses mimic and train autonomous vehicles, robots, and drones using synthetic data.
- You'll see a lot of instances where a corporation or organization can handle a data scarcity or a lack of pertinent data by using synthetic data. We also looked at the methods that can be used to produce fake data and who would profit from it.
The use of real data will always preferable when making business decisions. However, synthetic data is the next-best option when certain real raw data is not available for analysis. However, it must be remembered that in order to produce synthetic data, professionals with a solid grasp of data modelling are required. A thorough comprehension of the actual data as well as its surroundings is also essential. This is required to make sure that the generated data is as accurate as possible.
If you liked the information, then stay update with Labellerr!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
