

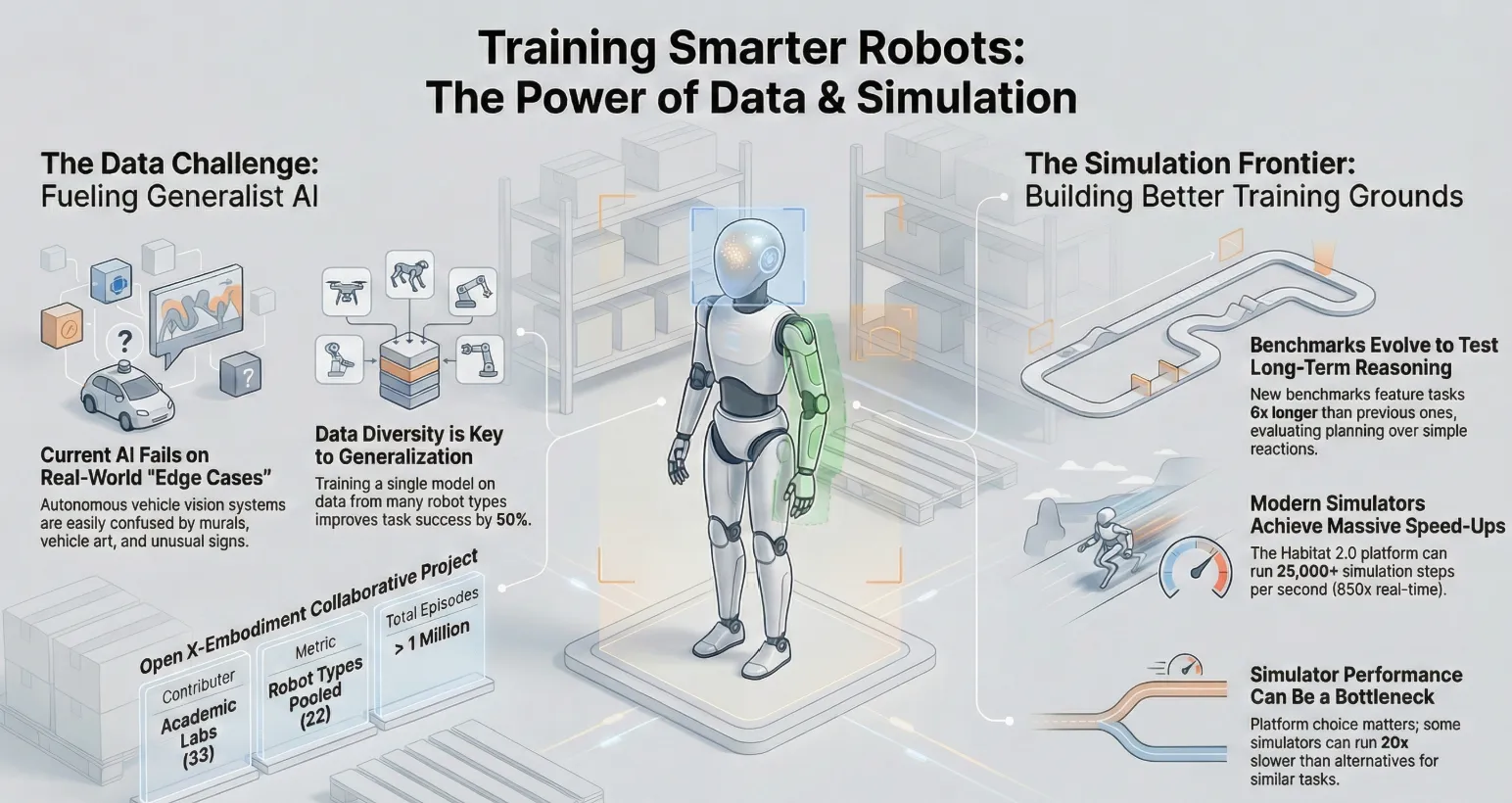
The Truth About Synthetic Robot Data
Synthetic training data enables robots to learn perception, motion, and interaction at scale. Generated in simulation, it offers low-cost labeling, safe edge-case testing, and faster development while addressing real-world data scarcity.


Modern robots learn from data, not rules. Cameras, LiDAR, radar and internal feedback streams continuously feed machine learning models. These models decide what the robot sees, how it plans, and how it moves in the physical world.
As robots move into open environments, data needs have increased. Robots now face more objects, layouts, and edge cases. Real-world data collection cannot scale fast enough to meet this demand.
Synthetic datasets have become a key part of robot training. They allow engineers to generate large amounts of data in simulation. This data is controlled, repeatable, and easy to label.
Synthetic data is no longer experimental. It is now a standard part of robotics pipelines. It is widely used in autonomy, manipulation, and safety testing.
What Is Synthetic training Data?
Synthetic Training
Synthetic data is created by computer models, not physical sensors. In robotics, it represents simulated sensor readings and environment interactions. These simulations are designed to match real operating conditions.
A synthetic dataset may include RGB images, depth maps, LiDAR point clouds, or radar signals. It may also include tactile data, joint states, and full motion trajectories.
Each data sample comes from a simulation engine. The engine models physics, sensors, and environment behavior. This allows full control over the data generation process.
The key feature of synthetic data is ground truth. Labels such as object position, segmentation masks, speed, and collisions are produced automatically. This removes the need for manual labeling and enables dense supervision that is hard to achieve in real-world data.
Types of Synthetic Datasets Used in Robot Training
1. Visual and Video Data
Visual data is the most common type of synthetic data. It is mainly used to train computer vision systems.
2D and 3D Images
These images are created in simulation and labeled automatically. Labels include bounding boxes, segmentation masks, depth, and surface normal. This provides accurate supervision at low cost.
Photorealistic Videos
Advanced models such as NVIDIA Cosmos can generate realistic videos. These videos may include several camera views. They can be created from a single image or a text prompt.
Augmented Visuals
World-to-world style transfer is applied to simulated scenes. Diffusion-based filters add weather, lighting, and terrain changes. This helps reduce the sim-to-real gap.
2. Kinematic and Motion Data
Kinematic data describes how a robot moves and acts in its environment. It is essential for learning control and physical behavior.
Rich Trajectories
Trajectories store sequences of states, actions, and rewards. They show how a robot behaves over time. Some systems can generate hundreds of thousands of trajectories in a few hours.
Occupancy Maps
Occupancy maps show free space and obstacles in a grid. Robots use them for navigation and path planning.
3. Non-Visual Sensor Data
Synthetic data can model sensors that are costly or difficult to use in real settings.
Tactile Data
Synthetic tactile signals are created using physics-based models. Finite element methods simulate contact forces and surface deformation. This helps robots learn grasping and slip detection.
LiDAR and Radar Data
Simulators generate LiDAR point clouds and radar signals at scale. These datasets help robots learn rare and unsafe scenarios.
Spectral Signatures
In remote sensing, synthetic data models how light interacts with surfaces. Atmospheric effects are also included. This supports satellite and Earth observation tasks.
How synthetic data is generated?
Synthetic data is created using computer simulations, generative AI, and 3D models of real environments. Collecting real data is often expensive, dangerous, or limited by privacy rules. Because of this, developers use specialized platforms to generate large, task-specific datasets at scale.
Most synthetic data pipelines follow these core methods:
1. Digital Twin Reconstruction and Scene Creation
Simulated Scene
The process starts by building a virtual version of the real world.
Neural Reconstruction:
Tools like NVIDIA NuRec capture real scenes using simple devices, such as smartphones. These scenes are converted into accurate 3D digital twins using the OpenUSD format.
Asset Population:
The virtual scene is filled with SimReady assets. These are realistic 3D models of objects like shelves or medical equipment. Each asset includes physics behavior and semantic labels.
Steerable Scene Generation:
Some systems use diffusion models guided by Monte Carlo Tree Search (MCTS). These models build scenes step by step, such as kitchens or restaurants. Physical rules prevent objects from overlapping or clipping.
2. LLM-Driven Automated Generation
Platforms such as AGIBOT Genie Sim 3.0 let users describe scenes in plain text. The system then creates structured 3D environments automatically. It can also generate many variations without manual coding.
3. Domain Randomization and Augmentation
Simulation settings like lighting, textures, object colors, camera views, and gravity are changed automatically. This exposes models to rare and difficult cases.
After simulation, diffusion-based models improve visual realism. World Foundation Models like NVIDIA Cosmos Transfer add weather effects and visual noise. This helps reduce the gap between simulation and reality.
4. Specialized Sensor and Motion Data
Tactile data is generated using finite element analysis (FEA). Tools like Abaqus and Isaac Gym simulate pressure, contact, and slip.
Systems such as GR00T-Dreams generate motion data at scale. From a single image and a language prompt, they produce sequences of robot states, actions, and rewards.
Why Synthetic Data Is Used
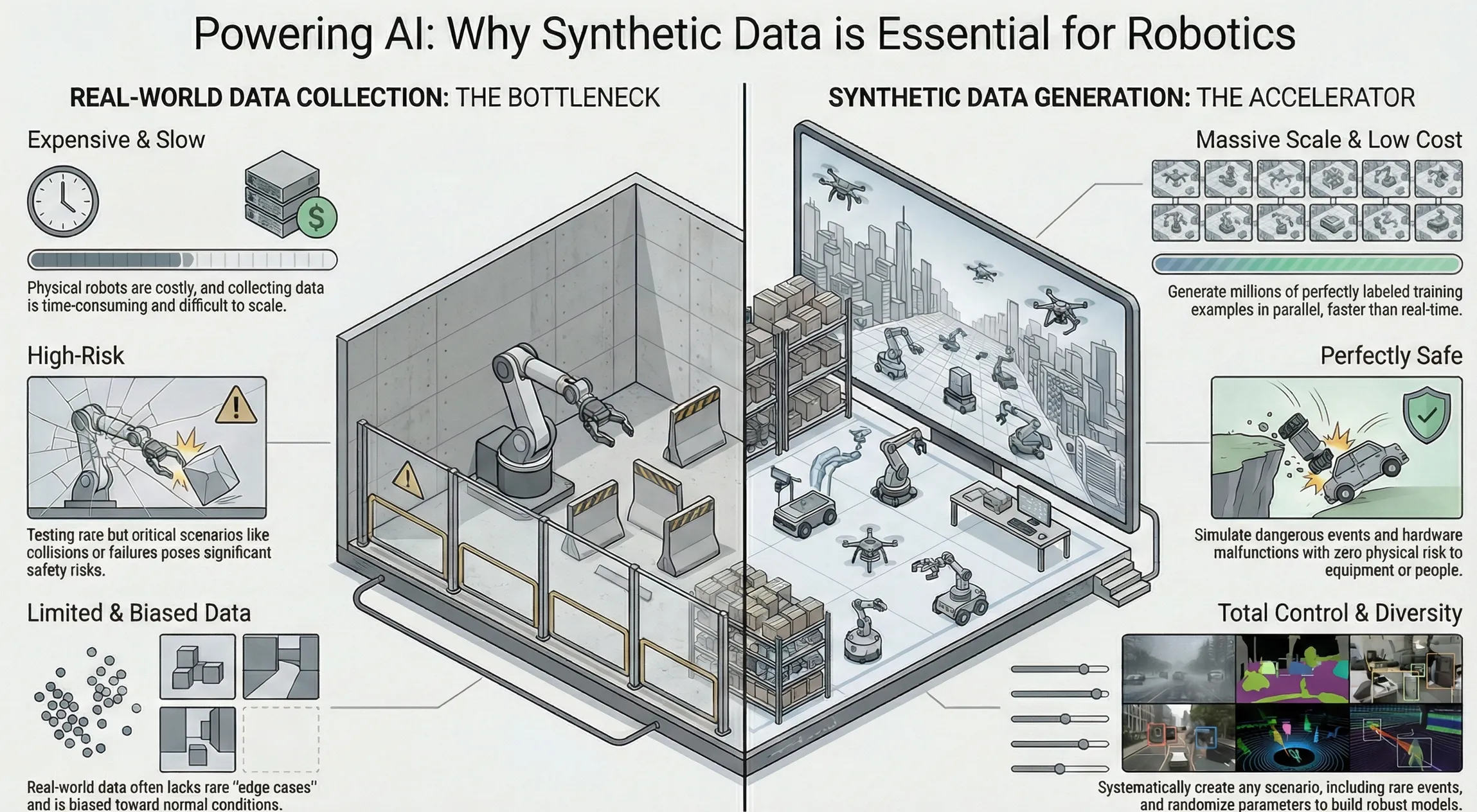
Synthetic Data Benefits
The shift toward a synthetic-first approach in AI training is driven by a clear problem. High-quality real-world data is becoming harder to obtain. At the same time, robots need data grounded in physical interaction, not just web-scale text.
In robotics, the main bottleneck is no longer compute power. It is the lack of diverse, accurately labeled training data. This data scarcity limits progress in Physical AI. Synthetic data directly addresses this constraint.
The main reasons for using synthetic data are outlined below.
1. Overcoming Data Scarcity and Prohibitive Costs
Cost Efficiency
Collecting and labeling real-world data is expensive and slow. It requires physical hardware, operators, and manual annotation. Synthetic data automates labeling and removes much of this cost. This makes large-scale dataset creation economically viable.
Rapid Data Generation
Simulation platforms such as NVIDIA Isaac Sim can generate more than one million synthetic images per hour. This allows teams to create massive datasets quickly. Collecting the same volume manually would take years.
Accelerated Development
Simulation reduces reliance on physical robots and test sites. Models can be trained, tested, and validated entirely in simulation. This shortens development cycles and speeds up deployment.
2. Safety and Handling Edge Cases
Dangerous Scenarios
Testing rare or hazardous situations in the real world is risky. This is especially true for autonomous vehicles and mobile robots. Synthetic data allows safe simulation of long-tail events, such as near-misses, collisions, or extreme weather.
Controlled Complexity
Simulation environments can model complex vehicle dynamics, sensor noise, and lighting effects. Conditions such as glare, fog, or motion blur are difficult to capture consistently in real-world data. Simulation makes these effects repeatable and controllable.
3. Privacy, Regulation, and Bias Reduction
Legal Compliance
Privacy laws such as GDPR (General Data Protection Regulation) and HIPAA (Health Insurance Portability and Accountability Act) restrict the use of sensitive human data. Synthetic medical records and images avoid direct use of real patient information. This enables training on rare diseases and edge cases without privacy violations.
Improving Fairness
Real-world datasets often underrepresent certain groups or conditions. Synthetic data can be generated to balance coverage across demographics and environments. This helps reduce algorithmic bias.
4. Technical Superiority and Generalization
Sim-to-Real Transfer
High-fidelity simulations model physics and sensors with increasing accuracy. This allows robots to learn skills in simulation and transfer them to real hardware. A sim-first approach reduces real-world trial and error.
Zero-Shot Learning
Large synthetic datasets expose models to wide variation. For example, billion-scale datasets such as SynGrasp-1B enable robots to interact with new objects and environments without task-specific fine-tuning.
Domain Randomization
Simulation parameters such as lighting, gravity, friction, and object properties can be changed automatically. This forces models to learn robust features. As a result, performance remains stable under real-world uncertainty.
5. Industrial and Research Democratization
Open Access and Scale
Synthetic data lowers the barrier to entry for robotics research. Platforms such as AGIBOT Genie Sim 3.0 have released more than 10,000 hours of synthetic data. This enables teams without large test facilities to train advanced models.
Standardized Benchmarking
Automated labeling pipelines ensure consistent ground truth. This reduces annotation errors compared to manual labeling. In many cases, error rates drop by up to 30 percent. Consistent labels also support reliable benchmarking across research groups.
Limitation of synthetic Training data
Synthetic data is a powerful tool for scaling AI, but it comes with clear limitations. These include technical gaps, data quality risks, and infrastructure constraints. If not managed carefully, these issues can lead to brittle and unsafe models in real-world deployment.
- Sim-to-Real Reality Gap
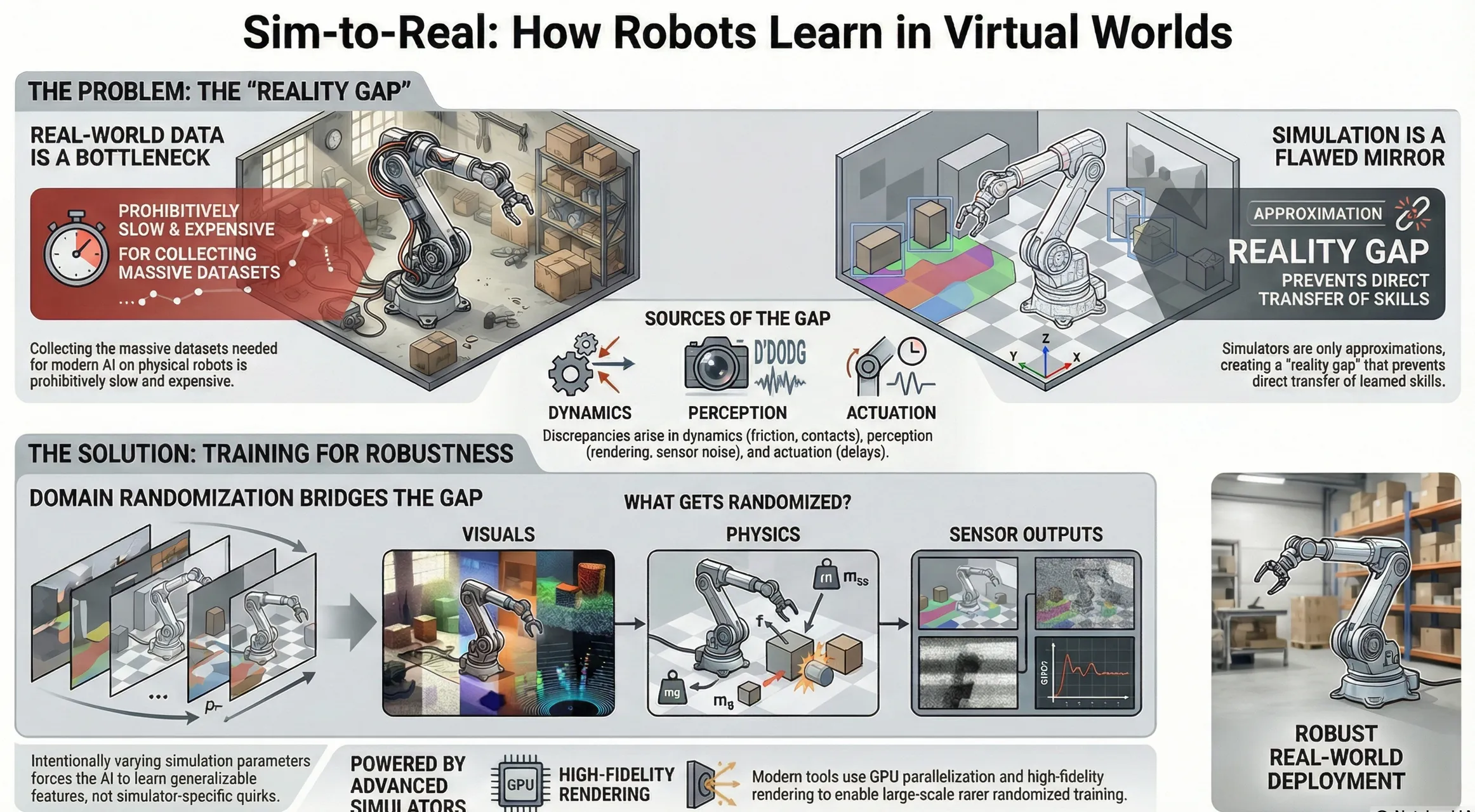
Simulation vs Reality
The most serious limitation is the sim-to-real gap (Δgap). It arises because simulations rely on simplified assumptions that do not fully reflect physical reality.
Simulated sensors often assume perfect calibration, while real sensors experience noise, drift, and latency. Visual simulation adds further mismatch, as renderers may contain physical errors or prioritize visual realism over physical correctness.
- Saturation and Diminishing Returns
More synthetic data does not always improve performance. Research shows that synthetic datasets follow rectified scaling laws, where gains flatten beyond a certain size. In practice, performance improvements often diminish at very large scales.
What matters more than volume is diversity. Variation in environments, objects, and interactions has a stronger impact than adding more demonstrations.
- Data Quality Risks and Model Collapse
Heavy dependence on synthetic data introduces quality risks. A key failure mode is model collapse, where systems train on their own generated outputs and amplify errors over time.
Poorly designed generators may further introduce bias amplification, reducing fairness and generalization.
- Infrastructure and Validation Bottlenecks
Scaling synthetic data generation creates system-level challenges. These workloads are often artifact-heavy, making compute alone insufficient. Teams frequently encounter limits in storage bandwidth and data movement.
Validation is another challenge. Models trained on synthetic data must be continuously tested against real-world ground truth. In some cases, performance is limited by model architecture, not data scale.
- Human Oversight Requirements
Synthetic data cannot replace human judgment. Human-in-the-loop (HITL) processes are still required to curate, validate, and refine datasets. This ensures physical realism, safety, and reliable deployment in production systems.
Conclusion
Synthetic data helps scale AI systems, but it has clear limits. These limits affect how well models work in the real world.
The biggest issue is the sim-to-real gap. Simulations simplify physics and miss effects like wear, drift, and contact details. Simulated sensors also assume clean signals, while real sensors have noise and delay. Visual scenes may look real but still behave incorrectly.
More synthetic data does not always improve results. After a point, gains slow down. Diversity matters more than size. New environments and objects help more than repeating similar data.
Data quality is another risk. Models trained mostly on synthetic data can drift away from real behavior. Errors may repeat and grow. Bias in the data generator can also carry into the model.
Scaling synthetic data is not easy. Storage, data movement, and validation become bottlenecks. Models must be tested against real data to stay reliable. In some cases, model design limits performance more than data size.
Human oversight is still needed. Synthetic data must be checked and refined to match real-world behavior. Today, it works best when combined with real data and human review.
FAQs
What is synthetic training data in robotics?
Synthetic training data is data generated in simulation or by generative models that imitates real sensor outputs such as images, LiDAR, motion trajectories, and tactile signals for training robots.
Why is synthetic data important for modern robot training?
Synthetic data helps overcome real-world data scarcity, reduces cost, improves safety, and enables large-scale, well-labeled datasets needed for perception, planning, and control.
Can robots trained on synthetic data work reliably in the real world?
Yes, but only when synthetic data is carefully validated and combined with real-world data to reduce the sim-to-real gap and improve generalization.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
