

Small Object Detection using YOLO with SAHI Explained
Small object detection often fails with standard YOLO inference due to image resizing. This blog shows how Slicing Aided Hyper Inference (SAHI) improves recall by breaking images into slices and recovering missed objects.


At first glance, the image looks clear. Cars are visible, roads are packed, and nothing seems hidden. But when a detection model looks at the same image, many of those cars simply disappear.
This happens because small and distant objects are easy to lose when large images are resized for inference. Models like YOLO are fast and accurate, but they often miss objects that occupy only a few pixels. The result is low recall, even when the scene feels obvious to the human eye.
One way to fix this is not to change the model, but to change how it sees the image. Slicing Aided Hyper Inference (SAHI) breaks large images into smaller parts and runs detection on each slice. This simple shift allows YOLO to recover objects it would otherwise miss.
Why Detection Models Struggle with Small Objects?
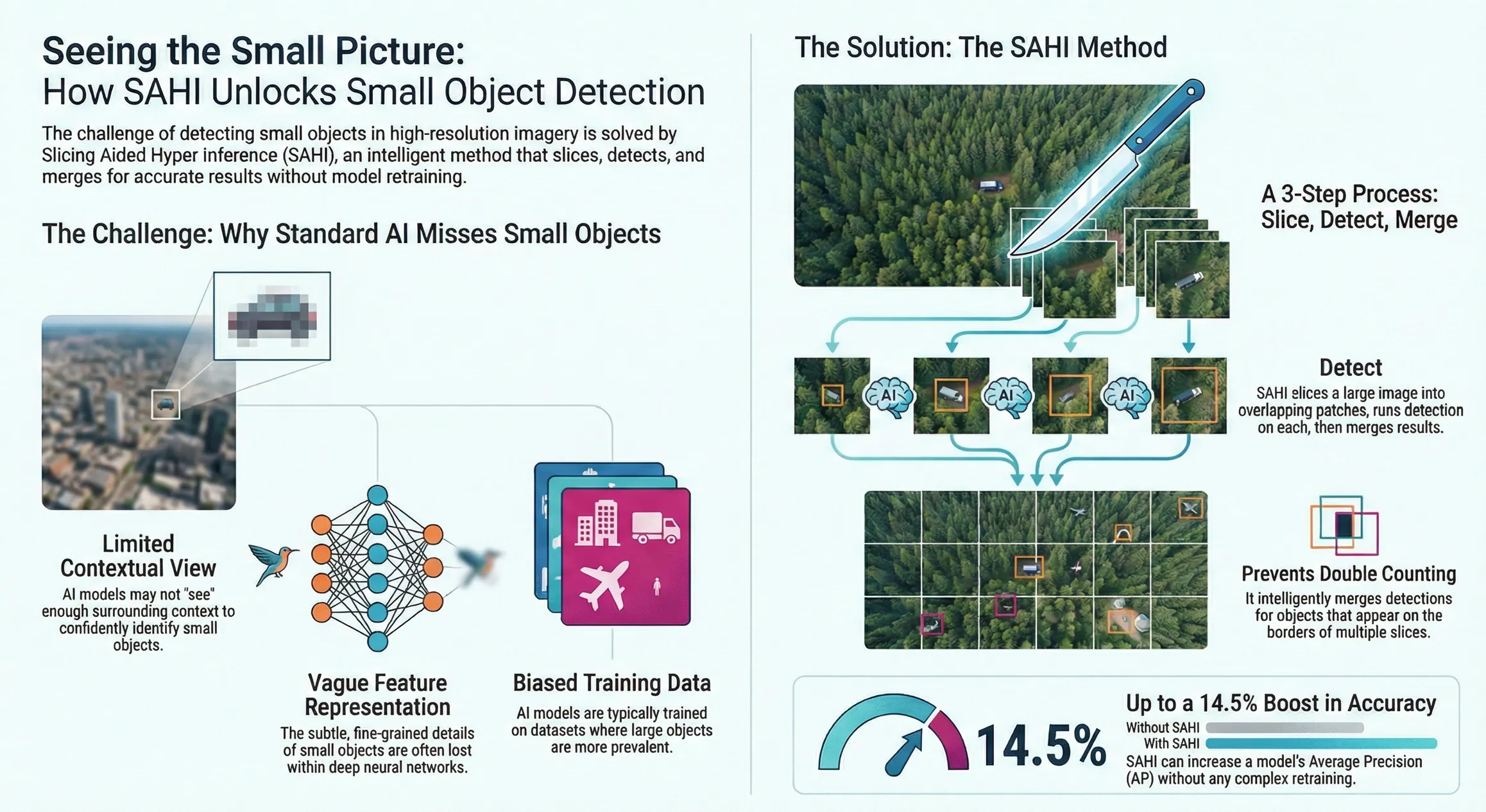
SAHI: Making Small Objects Visible to AI
Small objects do not fail because they are rare. They fail because they are small in the wrong place. In large images, tiny objects often blend into the background long before a model can learn their shape.
Most detection models resize images before inference. This step saves computation but removes fine details. When an object spans only a few pixels, resizing can erase it completely. What looks obvious to the human eye becomes noise to the model.
There is also a scale imbalance problem. Large objects dominate feature maps and gradients during training and inference. Small objects receive less attention and weaker signals. As a result, models tend to ignore them, leading to low recall in dense scenes.
How SAHI (Slicing Aided Hyper Inference) Works
SAHI Demo : Official GitHub Repository
Slicing Aided Hyper Inference (SAHI) is a technique and software library designed to improve small object detection in large, high-resolution images. Instead of processing the entire image at once, SAHI breaks it into smaller parts and runs detection on each part independently.
This approach allows models to detect small objects more reliably without changing their architecture.
1. Image Partitioning (Slicing)
The process begins by dividing the original high-resolution image into smaller, overlapping slices. Each slice has fixed dimensions, such as 640×640 or 832×832 pixels.
To avoid missing objects that lie near slice boundaries, adjacent slices overlap with each other. This overlap is controlled using parameters like overlap_height_ratio and overlap_width_ratio, commonly set around 0.2.
2. Independent Inference on Each Slice
Each slice is passed through the object detection model independently. Models such as YOLOv5, YOLOv8, or transformer-based detectors can be used without modification. The large images are resized to a fixed input size, which causes small objects to lose detail.
SAHI avoids this issue by running inference on smaller slices, preserving the original resolution and fine-grained features.
Because every slice undergoes its own forward pass, the number of forward passes per image increases. This can lead to longer inference times but it significantly improves the detection of small objects.
3. Optional Full-Image Inference
SAHI can optionally perform an additional inference pass on the full, un-sliced image. This step helps capture large objects that may be split across multiple slices. The results from this full-image inference are later merged with the slice-based predictions.
4. Result Merging and Stitching
After inference all predictions from individual slices are mapped back to the original image coordinates. Since overlapping slices can produce duplicate detections for the same object, SAHI applies merging strategies to clean the results.
Non-Maximum Suppression (NMS) is used to suppress overlapping bounding boxes by keeping the one with the highest confidence score.
Some implementations also use GREEDY NMS which merges boxes based on an Intersection over Union threshold often set around 0.75. These steps ensure that each object is counted only once, even if it appears in multiple slices.
Slicing Aided Fine-Tuning
Beyond inference, SAHI can also be applied during training through Slicing Aided Fine-Tuning. In this approach, training images are sliced into overlapping patches and resized.
This increases the relative size of small objects within each patch, helping the model learn stronger representations for them. As a result, the detector becomes more accurate when identifying small objects during inference.
Code Implementation
To understand the real impact of SAHI, theory alone is not enough. We evaluate standard YOLO inference and YOLO combined with SAHI on the same set of high-resolution images. The goal is to measure how slicing affects small object detection both visually and quantitatively.
Dataset and Ground Truth Annotations
Ground truth annotations were created manually using Labellerr. Each visible car was annotated with bounding boxes to ensure accurate supervision. Manual annotation was chosen to avoid label noise and to maintain precise object boundaries, especially for small vehicles that are easy to miss.
These annotations serve as the reference for all quantitative evaluations. Both standard YOLO inference and YOLO combined with SAHI are evaluated against the same ground truth, ensuring a fair and consistent comparison.
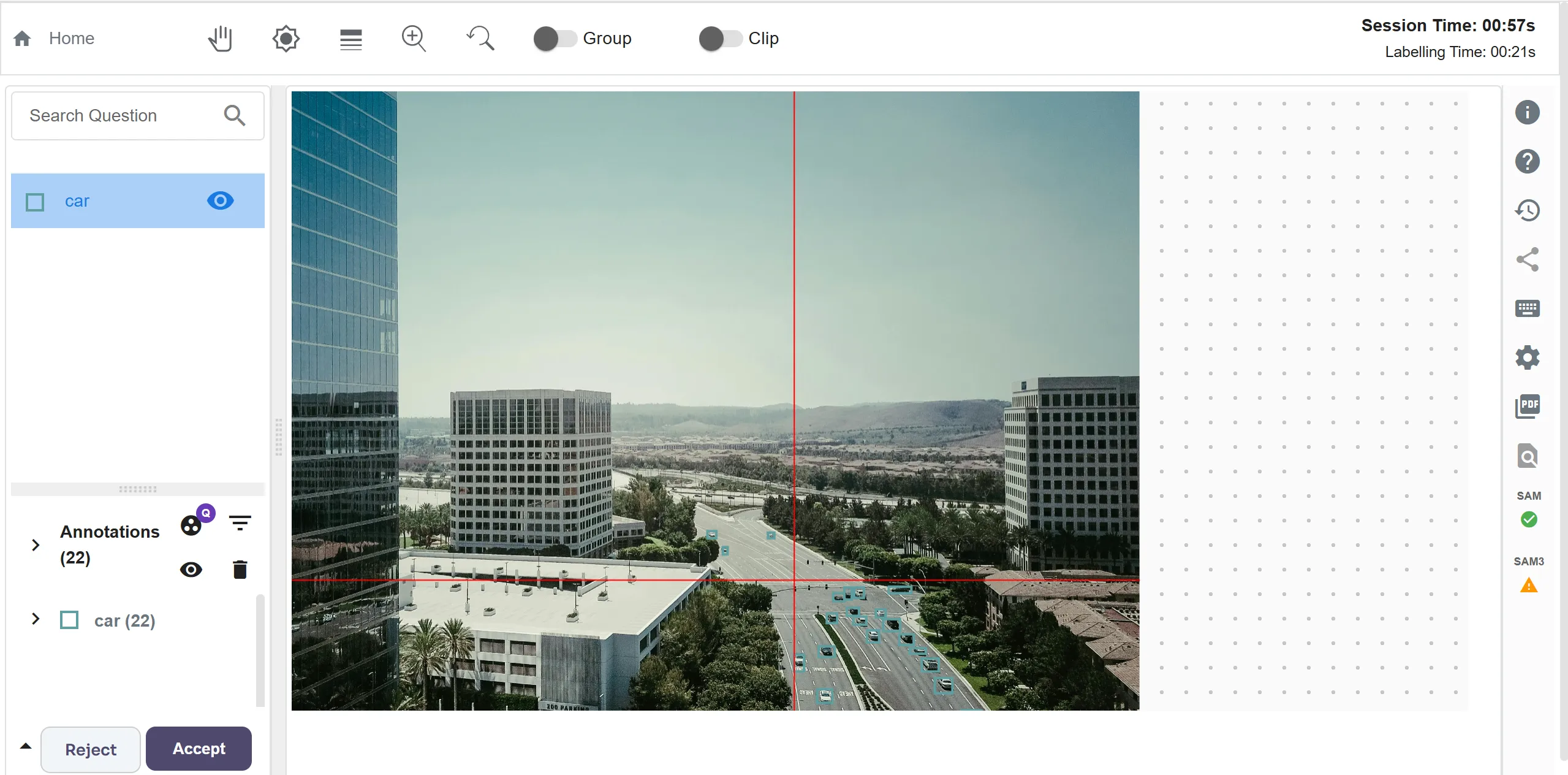
Image labelling using Labellerr for Ground Truth
Baseline: Standard YOLO Inference
We start with standard YOLO inference as the baseline. The detector processes the full image in a single forward pass after resizing it to the model’s input size. No slicing or multi-scale tricks are applied. This setup represents how YOLO is commonly used in practice.
Because the entire image is resized at once, small and distant cars lose fine details. As a result, many objects are missed, leading to low recall. This baseline helps establish how much small-object information is lost before introducing SAHI.

Yolo Detection Without SAHI
Baseline YOLO Code
from ultralytics import YOLO
from pathlib import Path
import json
# Load YOLOv8m
model = YOLO("yolov8m.pt")
image_dir = Path("dataset/images")
output_dir = Path("outputs/normal_yolo")
output_dir.mkdir(parents=True, exist_ok=True)
image_paths = sorted(image_dir.glob("*.jpg"))
# Run inference (COCO car = class 2)
results = model(
[str(p) for p in image_paths],
conf=0.15,
classes=[2],
device="cpu"
)
# ------------------ SAVE VISUAL OUTPUTS ------------------
for img_path, r in zip(image_paths, results):
r.save(filename=str(output_dir / img_path.name))
print("Normal YOLOv8 (car-only) predictions saved")
# ------------------ SAVE COCO JSON ------------------
coco_preds = []
image_id = 1 # IMPORTANT: must match GT image_id order
for r in results:
if r.boxes is None:
image_id += 1
continue
for box in r.boxes:
x1, y1, x2, y2 = box.xyxy[0].tolist()
coco_preds.append({
"image_id": image_id,
"category_id": 0, # GT uses car = 0
"bbox": [x1, y1, x2 - x1, y2 - y1],
"score": float(box.conf[0])
})
image_id += 1
with open("normal_yolo_preds.json", "w") as f:
json.dump(coco_preds, f)
print("Normal YOLOv8 predictions JSON saved")
YOLO with Slicing Aided Hyper Inference (SAHI)
To address the limitations observed in standard YOLO inference, we apply Slicing Aided Hyper Inference (SAHI). Instead of running detection on the full image, SAHI divides each high-resolution image into smaller overlapping slices.
YOLO is then applied to each slice independently, and the results are merged back into the original image space.

Yolo Detection Without SAHI
from sahi import AutoDetectionModel
from sahi.predict import get_sliced_prediction
from pathlib import Path
import json
detection_model = AutoDetectionModel.from_pretrained(
model_type="yolov8",
model_path="yolov8m.pt",
confidence_threshold=0.15,
device="cpu"
)
image_dir = Path("dataset/images")
output_dir = Path("outputs/sahi_yolo")
output_dir.mkdir(parents=True, exist_ok=True)
# COCO class IDs to EXCLUDE (keep only car = 2)
EXCLUDE_IDS = [i for i in range(80) if i != 2]
coco_preds = []
image_id = 1 # MUST match GT image_id order
for img_path in sorted(image_dir.glob("*.jpg")):
result = get_sliced_prediction(
image=str(img_path),
detection_model=detection_model,
slice_height=512,
slice_width=512,
overlap_height_ratio=0.25,
overlap_width_ratio=0.25,
exclude_classes_by_id=EXCLUDE_IDS
)
# ------------------ SAVE VISUALS ------------------
result.export_visuals(
export_dir=str(output_dir),
file_name=img_path.stem
)
# ------------------ SAVE COCO JSON ------------------
for obj in result.object_prediction_list:
coco_preds.append({
"image_id": image_id,
"category_id": 0, # GT uses car = 0
"bbox": obj.bbox.to_xywh(),
"score": obj.score.value
})
image_id += 1
with open("sahi_yolo_preds.json", "w") as f:
json.dump(coco_preds, f)
print("YOLOv8 + SAHI (car-only) predictions saved + JSON exported")
Quantitative Comparison between yolo and yolo+SAHI
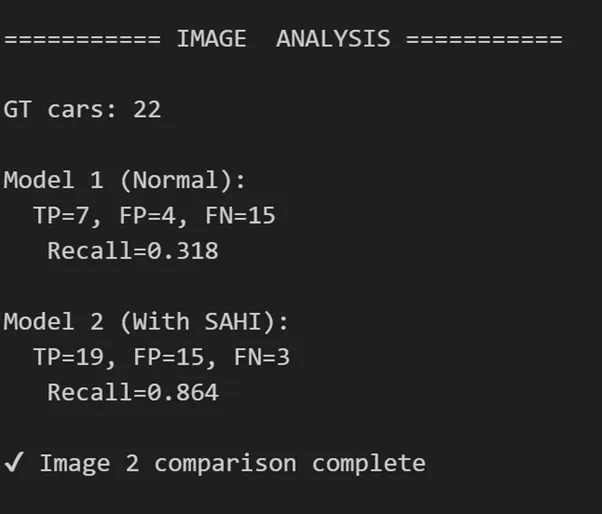
Comparision
The evaluated image contains 22 ground-truth cars. With standard YOLO inference, only 7 cars are correctly detected, while 15 are missed. This results in a recall of 31.8%, indicating that most small and distant vehicles are not captured.
After applying SAHI, YOLO detects 19 out of 22 cars, reducing missed detections to just 3. Recall increases significantly from 31.8% to 86.4%, showing that slicing helps the model recover objects lost during full-image resizing.
Although the number of false positives increases with SAHI, the large reduction in false negatives makes this trade-off acceptable for small object detection tasks where missing objects is more critical than producing extra detections.
Conclusion
Small object detection remains a major challenge for single-pass detectors like YOLO. When high-resolution images are resized, many small and distant objects are lost, leading to low recall.
By applying Slicing Aided Hyper Inference, YOLO is able to detect objects that were previously missed. Both visual results and quantitative metrics show a clear improvement, with recall increasing from 31.8% to 86.4%. These results confirm that changing the inference strategy can be as effective as changing the model itself.
Why does YOLO struggle with small object detection?
YOLO resizes high-resolution images to a fixed input size, which causes small objects to lose important visual details and reduces recall.
How does SAHI improve small object detection with YOLO?
SAHI slices large images into smaller overlapping patches and runs YOLO on each slice, preserving object details and improving recall.
Does using SAHI affect inference speed?
Yes, SAHI increases inference time because multiple slices are processed, but it significantly improves detection accuracy for small objects.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
