

Self-Supervised Learning Approach with DINOv2


Table of Contents
- Introduction
- Algorithmic and Technical Improvements
- About Curating The Dataset
- Model and Training Details
- Performance Details
- Working Demonstration
- Conclusion
- Frequently Asked Questions (FAQ)
Introduction
Recently, Meta AI has developed a new method for training computer vision models called DINOv2. Unlike previous methods that require large amounts of labeled data, DINOv2 uses self-supervised learning, making it more flexible and able to learn from any collection of images.
The model does not require fine-tuning, and the high-performance features it produces can be used as inputs for simple linear classifiers, making it suitable as a backbone for a range of computer vision tasks.
DINOv2 outperforms all the standard approaches in the field, achieving strong prediction capabilities on classification, segmentation, and image retrieval tasks.
The model also delivers accurate depth estimation, a feature that current standard approaches cannot achieve.
The backbone remains general, allowing the same features to be used for multiple tasks simultaneously.
There are various potential applications of self-supervised computer vision models, such as mapping forests, tree by tree, across areas the size of continents.
Meta AI collaborated with the World Resources Institute to create accurate maps of forests worldwide, demonstrating the model's generalization capabilities.
Further, DINOv2 also complements other recent computer vision research from Meta AI, including Segment Anything, a promotable segmentation system focused on zero-shot generalization to a diverse set of segmentation tasks.
DINOv2 combines with simple linear classifiers to achieve strong results across multiple tasks, creating horizontal impact.
Algorithmic and technical improvements
Below, we discuss the challenges of training larger computer vision models and how DINOv2 addresses these challenges.
The first challenge is potential instability during training due to increased model size. DINOv2 includes additional regularization methods inspired by the similarity search and classification literature, making the training algorithm more stable.
The second challenge is implementing larger models more efficiently.
DINOv2's training code integrates the latest mixed-precision and distributed training implementations proposed in the PyTorch 2 framework and the latest compute algorithm implementations of xFormers, allowing faster and more efficient iteration cycles.
With equivalent hardware, the DINOv2 code runs around twice as fast with only a third of the memory usage, enabling scaling in data, model size, and hardware.
About Curating The Dataset
Meta AI describes building a large-scale pretraining dataset for computer vision models using publicly available web data in the paper.
They highlight that larger models require more data for training, but accessing such data is not always possible.
Therefore, to create the dataset, the publicly available repository has been used for crawling web data and building a pipeline to select useful data inspired by LASER.
The paper mentions two key ingredients for building a large-scale pretraining dataset from such a source: discarding irrelevant images and balancing the dataset across concepts.
They explain that such delicate curation cannot be done manually, and they wanted a method that allowed capturing distributions not easily associated with metadata.
They achieved this by curating a set of seed images from a collection of about 25 third-party datasets and extending it by retrieving images sufficiently close to those seed images.
This approach enabled the authors to produce a pretraining dataset totaling 142 million images out of the 1.2 billion source images. Further, this dataset enables them to train larger computer vision models and improve performance.
The above approach can be useful when no sufficiently large curated dataset is available. Publicly available web data can be leveraged with careful curation to create a large-scale pretraining dataset.
Model and Training Details
Architecture Details
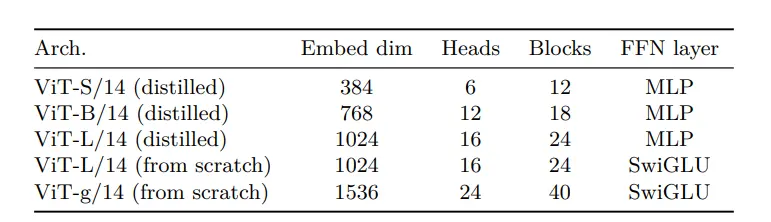
Figure: Architecture details of the ViT-S/B/L/g networks
MLP feed-forward networks have been used for distilled models and the SwiGLU function when training from scratch.
Training hyperparameters
The models were trained for 625,000 iterations using the AdamW optimizer, with an initial LayerScale value of 1e-5, weight decay, and a cosine schedule ranging from 0.04 to 0.2.
A learning rate warmup of 100,000 iterations and a teacher momentum cosine schedule ranging from 0.994 to 1.
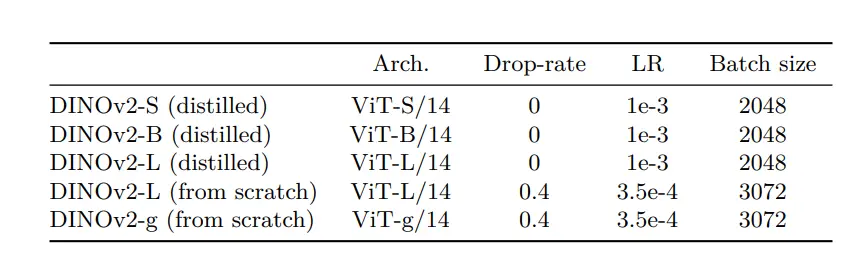
Figure: Training hyperparameters for DINOv2-S, DINOv2-B, DINOv2-L and DINOv2-g
Performance Details
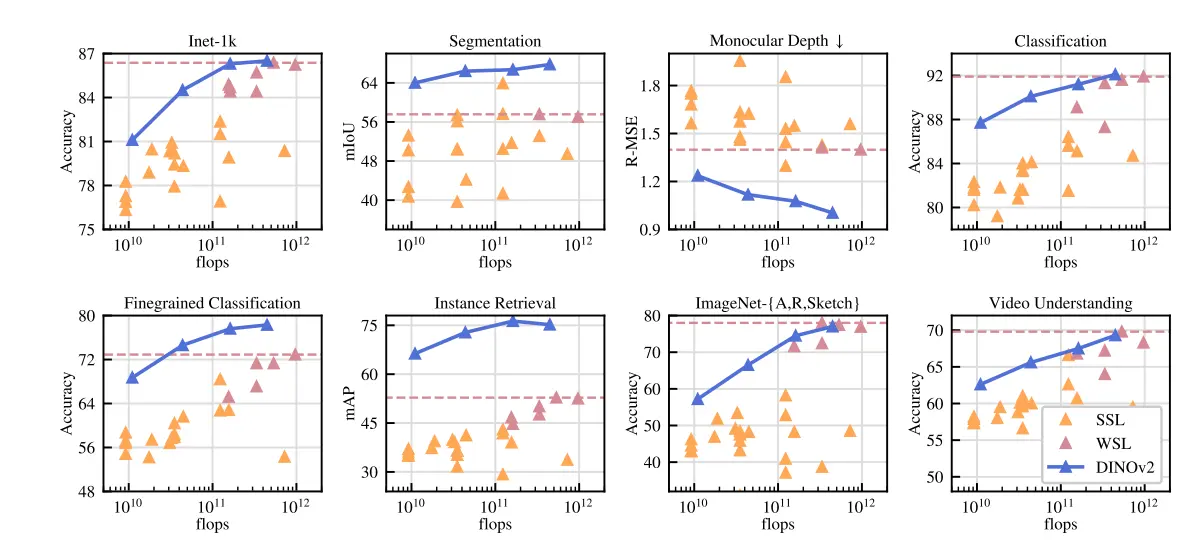
Figure: Performance Comparison of different tasks
In the above image, we have compared the DINOV2 models' performance on eight different vision tasks and provided average metrics for each task.
The features are extracted using our self-supervised encoders, DINOv2, represented by the dark blue line. The results are compared with those of other self-supervised methods (pale orange) and weakly-supervised methods (dark pink).
The best-performing weakly-supervised model's performance is represented using a dashed horizontal line.
DINOV2’s models outperform the previous state-of-the-art in self-supervised learning and achieve performance comparable to weakly-supervised features.
Working Demonstration
In the next section, we look at some actual results produced by Dinov2. For this, we analyze different tasks.
Semantic Segmentation
Semantic segmentation is a computer vision problem that includes labeling each pixel in an image with a semantic label, such as labeling all pixels relating to a car, person, tree, or road.
In the image below, the trees have been segmented in green color, while we see that the roads are gray and the sky is blue.


Figure: Semantic Segmentation using Dinov2
Depth Estimation
Depth estimate is a computer vision problem that estimates the distance between objects in a scene based on a single image or a succession of images.
The purpose is to construct a depth map representing the distance between objects in a picture from the viewer's perspective.
In the blow images, we see that the passage ends up in dark color which intuitively indicates that the image has more depth, as compared to other objects which are ahead of it.

Figure: Depth Estimation using Dinov2
Conclusion
In conclusion, Meta AI's DINOv2 model offers a flexible and efficient approach to training computer vision models through self-supervised learning without needing large amounts of labeled data.
The model produces high-performance features that can be used as a backbone for various computer vision tasks without requiring fine-tuning.
DINOv2 outperforms standard approaches in the field, achieving strong prediction capabilities on various vision tasks, including accurate depth estimation.
The model also complements other recent computer vision research from Meta AI and can have potential applications in mapping forests, tree by tree, across large areas.
Further, we also looked at the approach to curating a large-scale pre-training dataset using publicly available web data, enabling them to train larger computer vision models and improve performance.
Next, we discussed the challenges of training larger models and how DINOv2 addresses these challenges through additional regularization methods and efficient training code.
Next, we also looked at the model's training hyperparameters.
We then compared its performance on eight different vision tasks with other self-supervised and weakly-supervised methods, demonstrating its superiority over the previous state-of-the-art in self-supervised learning and its comparable performance to weakly-supervised features.
DINOv2 significantly improves self-supervised learning for computer vision, with potential applications in various fields.
For more details regarding Dinov2, refer to:
- https://arxiv.org/pdf/2304.07193.pdf
- https://ai.facebook.com/blog/laser-multilingual-sentence-embeddings/
About the Company
Labellerr is a computer vision workflow automation platform with expertise in using LLMs and other foundation models to use in easing out the data preparation process to accelerate AI development.
Frequently Asked Questions (FAQ)
1. What is Dino v2?
DINO v2, also known as DIstillation of knowledge with No labels and vIsion transformers 2, is an advanced self-supervised learning algorithm created by Facebook AI.
It is a continuation of the original DINO model and utilizes vision transformers (ViT) to extract knowledge from images without needing labeled data. DINO v2 builds upon the success of its predecessor, offering innovative capabilities in self-supervised learning.
2. What is the difference between segment anything and DINOv2?
Segment Anything and DINOv2 differ in their focus and capabilities. Segment Anything is primarily a promotable segmentation system that aims to generalize across various segmentation tasks without requiring specific training for each task. It emphasizes zero-shot generalization to diverse segmentation tasks.
On the other hand, DINOv2 is a more versatile model that combines with simple linear classifiers to deliver impressive performance across multiple tasks, extending beyond the domain of segmentation. It achieves horizontal impact by offering strong results in various areas beyond just segmentation.
3. What is the image size of DINOv2?
DINOv2 employs a Transformer architecture with a patch size of 14. In the case of a 224x224 image, this configuration includes 1 class token along with 256 patch tokens. If larger images are used, they should have dimensions that are multiples of the patch size (14) to ensure compatibility with the models.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
