

Segment Anything: Automated Labeling With Foundation Model


Image segmentation is a critical problem in computer vision, and it involves dividing an image into multiple segments based on their visual characteristics.
Accurate image segmentation is essential in many applications, including object recognition, image editing, medical image analysis, autonomous driving, and more.

Figure: Image Segmentation using Segment Anything
One of the main challenges in image segmentation is the variability and complexity of the images themselves. Images can have a wide range of features, such as color, texture, shape, and size, making it difficult to identify and segment objects accurately.
Additionally, images can contain noise, occlusion, and other visual artifacts that further complicate the segmentation task.
The Segment Anything model is an advanced computer vision model developed by Facebook AI that uses deep learning algorithms and traditional computer vision techniques to segment objects within images accurately.
This blog will introduce the Segment Anything model, outlining its main features, applications, and how it works.
Table of Contents
- Segment Anything (SAM)
- Architecture Details
- Segment Anything Dataset
- Training Details
- Potential Applications
- Conclusion
- Frequently Asked Questions (FAQ)
Segment Anything (SAM)
The Segment Anything model, developed by Facebook AI, is an innovative image segmentation model built upon the Foundation Model, a pre-trained image recognition model released by Facebook AI in 2020.
Image segmentation is an essential problem in computer vision, where an image is divided into multiple segments based on its visual features, such as color, texture, and shape.
Segment Anything combines traditional computer vision techniques and deep learning algorithms to segment objects within images accurately.
It is a highly flexible and versatile model that can handle complex and noisy images, making it suitable for use in various industries, such as healthcare, e-commerce, robotics, and more.
The Foundation Model on which the Segment Anything model is based is pre-trained on a massive dataset of images.
This pre-training enables the model to identify various objects and features within an image, which is essential for accurate segmentation.
The Segment Anything model leverages this pre-training to achieve accurate segmentation results without requiring as much training data as traditional segmentation models.
One of the most significant advantages of the Segment Anything model is its flexibility and versatility. It can handle various objects and image types, making it suitable for various applications.
For example, in the healthcare industry, the model can assist doctors in accurately detecting and diagnosing diseases such as cancer, heart disease, and more.
In the e-commerce industry, the model can improve the accuracy of product recognition and object detection, resulting in a better user experience.
The Segment Anything model combines traditional computer vision techniques, such as edge detection and morphological operations, and deep learning algorithms, such as convolutional neural networks (CNNs), to achieve accurate segmentation results.
This approach enables the model to handle complex and noisy images, making it suitable for various industries.
Architecture Details
We next describe the Segment Anything Model (SAM) for image segmentation. SAM has three components an image encoder, a flexible prompt encoder, and a fast mask decoder.
Here are some key details about the architecture and work:
- The image encoder can be any network that outputs a C×H×W image embedding.
- They use an MAE pre-trained Vision Transformer (ViT) with minimal adaptations to process high-resolution inputs, specifically a ViT-H/16 with 14×14 windowed attention and four equally-spaced global attention blocks.
- The image encoder’s output is a 16× downscaled embedding of the input image.
- They use an input resolution of 1024×1024 obtained by rescaling the image and padding the shorter side. The image embedding is, therefore, 64×64.
- To reduce the channel dimension, they use a 1×1 convolution to get to 256 channels, followed by a 3×3 convolution with 256 channels. A layer normalization follows each convolution.
- Sparse prompts are mapped to 256-dimensional vectorial embeddings. A point is represented as the sum of a positional encoding of the point’s location and one of two learned embeddings indicating whether the point is either in the foreground or background. An embedding pair represents a box, and free-form text is represented using the text encoder from CLIP.
- Dense prompts (i.e., masks) have a spatial correspondence with the image. The input masks at a 4× lower resolution than the input image, then downscale an additional 4× using two 2×2, stride-2 convolutions with output channels 4 and 16, respectively. A final 1×1 convolution maps the channel dimension to 256. GELU activations and layer normalization separate each layer.
- Using a lightweight decoder, the image, and prompt embeddings are efficiently mapped to an output mask. They modify a standard Transformer decoder and use a two-layer decoder.
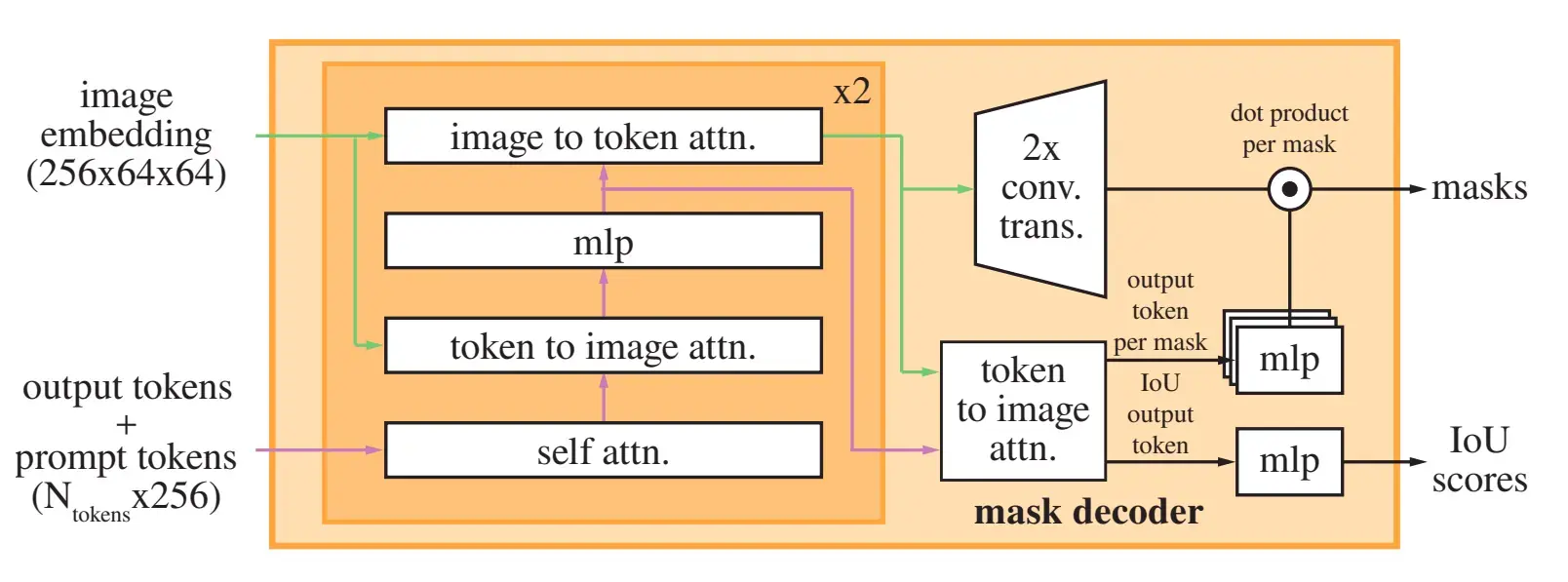
Figure: Details of Light-weight mask decoder
- Each decoder layer performs four steps: (1) self-attention on the tokens, (2) cross-attention from tokens (as queries) to the image embedding, (3) a point-wise MLP updates each token, and (4) cross-attention from the image embedding (as queries) to tokens.
- To ensure the decoder can access critical geometric information, positional encodings are added to the image embedding whenever they participate in an attention layer. The original prompt tokens (including their positional encodings) are re-added to the updated tokens whenever they participate in an attention layer.
- After running the decoder, they unsampled the updated image embedding by 4× with two transposed convolutional layers (now it’s downscaled 4× relative to the input image).
- The tokens attend again to the image embedding, and the updated output token embedding is passed to a small 3-layer MLP that outputs a vector.
- The tokens attend once more to the image embedding.
- The updated output token embedding is passed to a small 3-layer MLP (multi-layer perceptron) that outputs a vector matching the channel dimension of the upscaled image embedding.
- Finally, a mask is predicted using a spatially point-wise product between the upscaled image embedding and the MLP's output.
- The transformer used in this process has an embedding dimension of 256.
- The transformer MLP blocks have a large internal dimension of 2048, but they are applied only to the prompt tokens, for which there are relatively few (rarely greater than 20).
- In cross-attention layers with a 64x64 image embedding, the channel dimension of the queries, keys, and values is reduced by 2x to 128 for computational efficiency.
- All attention layers use eight heads.
- The transposed convolutions used to upscale the output image embedding are 2x2, with stride 2, and have output channel dimensions of 64 and 32.
- These transposed convolutions have GELU activations and are separated by layer normalization.
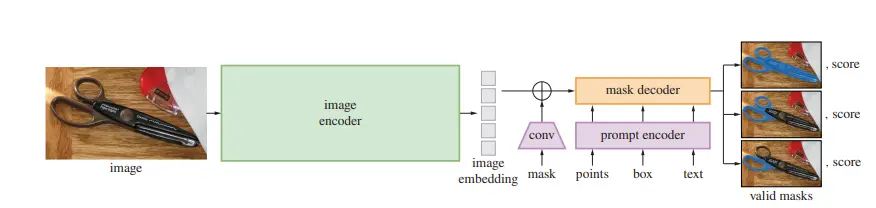
Figure: Segment Anything Model (SAM) overview
Segment Anything Dataset
The SA-1B dataset is a large-scale computer vision dataset with 11 million images and 1.1 billion segmentation masks. The images are licensed and privacy-protected, ensuring they can be used for research and development.
The images in the SA-1B dataset are diverse and high-resolution, with an average resolution of 3300×4950 pixels. However, the images have been downsampled to 1500 pixels on their shortest side to reduce the data size.
Even after downsampling, the images are significantly higher resolution than many existing vision datasets, such as COCO images which are only around 480×640 pixels.
To protect individual privacy faces and vehicle license plates have been blurred in the released images.
The segmentation masks in the SA-1B dataset were generated mostly automatically by a data engine, with 99.1% of the masks generated fully automatically.
The quality of the automatic masks is compared to professional annotations, and various mask properties are analyzed and compared to prominent segmentation datasets.
The analysis concludes that the automatic masks included in the SA-1B dataset are high quality and effective for training models. Therefore, SA-1B only includes automatically generated masks.
The SA-1B dataset is released to aid the future development of foundation models for computer vision. It will be available under a favorable license agreement for certain research uses and with protections for researchers.

Figure: Example images with overlaid masks from the SA-1B dataset.
Training Details
Now, we move on to the training details of SAM. This includes:
- The AdamW optimizer has a warm-up period of 250 iterations and a step-wise learning rate decay schedule.
- The initial learning rate is 8e-4, and the batch size is 256 images.
- To regularize the model, weight decay (wd) is set to 0.1, and drop path (dp) is applied with a rate of 0.4.
- Layer-wise learning rate decay (ld) of 0.8 is used, and no data augmentation is applied.
- The model is initialized with an MAE pre-trained ViT-H model.
- Training is distributed across 256 GPUs to handle the large image encoder and 1024x1024 input size. Up to 64 randomly sampled masks per GPU are used to limit GPU memory usage.
- Filtering SA-1B masks to discard those that cover more than 90% of the image qualitatively improves results.
- For ablations and other variations on training, large-scale jitter with a scale range of [0.1, 2.0] is used to augment the input when training with data from the first and second data engine stages only.
- To train ViT-B and ViT-L, 180k iterations with a batch size of 128 distributed across 128 GPUs are used. The learning rate is set to lr = 8e-4/4e-4, ld = 0.6/0.8, wd = 0.1, and dp = 0.6/0.4 for ViT-B/L, respectively.
Potential Applications
There are numerous applications where the Segment Anything Model can be employed. These include:
- SAM has potential applications in various domains that require finding and segmenting image objects.
- SAM could be incorporated into larger AI systems for a more general multimodal understanding of the world, such as understanding both visual and textual content on a webpage.
- In AR/VR, SAM could enable object selection based on a user's gaze and lift it into 3D.

Figure: Gaze-based Object Detection
4. SAM can improve creative applications for content creators, like extracting image regions for collages or video editing.
5. SAM could aid scientific studies of natural occurrences on Earth or space by localizing animals or objects to study and track in the video.
Conclusion
In the above blog, we studied SAM (Segment Anything Model) developed by Facebook AI. SAM is an innovative image segmentation model built upon the Foundation Model, a pre-trained image recognition model released by Facebook AI in 2020.
Initially, we had a brief discussion about SAM. Then we moved on to discussing SAM’s architecture details.
SAM has three components, an image encoder, a flexible prompt encoder, and a fast mask decoder. We build on Transformer vision models with specific tradeoffs for (amortized) real-time performance.
Next, we talked about the dataset used for training SAM. The SA-1B dataset is a large-scale computer vision dataset with 11 million images and 1.1 billion segmentation masks, with high-resolution images downsized to reduce data size and protect privacy.
The automatic masks a data engine generates are of high quality and released under a favorable license agreement for certain research uses.
Further, we discussed the training details. SAM's training details include a warm-up time of 250 iterations, a drop path with a rate of 0.4, a layer-wise learning rate decay of 0.8, and no data augmentation.
The model is trained on the SA-1B dataset using 256 GPUs and 256 pictures in a batch. 180k iterations with a batch size of 128 are utilized for ViT-B and ViT-L, with varied learning rates, layer-wise learning rate decay, weight decay, and drop path values.
Finally, the Segment Anything Model (SAM) has many potential applications in image object segmentation domains such as AR/VR, content creation, and scientific studies.
It might potentially be integrated into bigger AI systems for multimodal world knowledge.
Book a demo with Labellerr's sales team to see how ML teams can leverage the benefits of SAM in their computer vision development workflow using Labellerr.
Frequently Asked Questions (FAQ)
1. What is segmentation in data labeling?
The major purpose of segmentation entails assigning an appropriate label to each pixel depending on what that pixel represents in the picture. Thus, it divides images into multiple zones or segments in accordance with the object to which pixels belong.
2. How does the segment anything model work?
SAM, the Segment Anything Model, is designed to be promotable, allowing it to accept different input prompts like points or boxes that indicate the specific object to be segmented.
For instance, by drawing a box around a person's face, SAM can generate a mask specifically for that face. Additionally, multiple prompts can be provided to segment multiple objects simultaneously.
This flexibility enables SAM to cater to diverse segmentation requirements and accurately identify and isolate desired objects in an image.
3. Is segment anything model open source?
Segment Anything Model" offers the advantage of being trainable on small datasets, making it highly applicable across a diverse array of applications, even in situations with limited resources.
The release of this model as an open-source initiative represents a noteworthy milestone in democratizing AI technology, making it more accessible and available to a wider audience.
This move encourages broader participation and empowers individuals and organizations to leverage the benefits of AI in their respective domains.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
