

Securing AI System's Importance: Learning from Google's AI Red Team


Red teaming is a critical cybersecurity practice that involves creating a team of ethical hackers, known as the "Red Team," to simulate real-world attacks and adversarial scenarios on an organization's systems, networks, or technology.
In the context of AI systems, red teaming plays a decisive role in preparing organizations for potential attacks on AI technology. By conducting red team exercises, companies can identify vulnerabilities, weaknesses, and potential risks in their AI systems and take proactive measures to improve security.
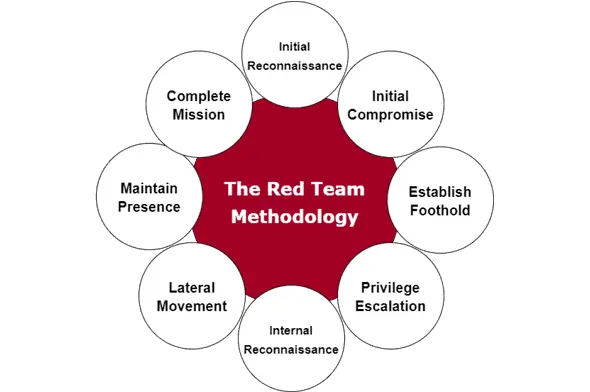
Figure: Red Team Methodology
Google's AI Red Team is composed of skilled hackers who simulate various adversaries, including nation-states, criminal groups, hacktivists, and malicious insiders.
This approach allows Google to gain insights into potential threats that their AI systems may face and understand how to defend against them effectively.
The AI Red Team aligns closely with traditional red teams while leveraging specialized AI subject matter expertise to conduct complex technical attacks on AI systems. By adapting the concept of red teaming to the latest innovations in technology, including AI, Google's Red Team ensures the company's AI deployments are secure and resilient to emerging threats.
In this blog, we will discuss Google AI Red Team and its purpose. Furthermore, we will focus on different attacks and practices which the Read Team follows.
Table of Contents
- What Do We Mean by Red-Teaming?
- Types of Attacks on Red-Team AI Systems
- Key Points to Be Remembered
- Conclusion
- Frequently Asked Questions (FAQ)
What do we mean by Red-Teaming?
Red teaming refers to a practice where a group of hackers, such as Google's Red Team, imitate diverse adversaries, including nation-states, well-known Advanced Persistent Threat (APT) groups, hacktivists, individual criminals, and even malicious insiders.

Figure: Red Team vs. Blue Team
The concept originated from military exercises, where a designated team, known as the "Red Team," assumes an adversarial role, challenging the "home" team's defenses and strategies. The objective of red teaming is to thoroughly assess an organization's security measures, identify vulnerabilities, and improve overall resilience against real-world threats.
Types of Attacks on Red-Team AI Systems
Different types of red team attacks on AI systems encompass various tactics to assess their vulnerabilities. Google's AI Red Team conducts research to adapt these attacks to real AI-based products and features, focusing on understanding their potential impacts on security, privacy, and abuse concerns depending on how and where the technology is implemented.
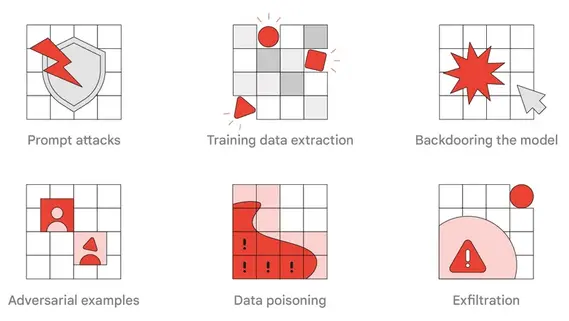
Figure: Types of Adversarial Attacks
The team leverages attackers' tactics, techniques, and procedures (TTPs) to enhance safety to test various system defenses. The report highlights several TTPs that are particularly relevant and realistic for real-world adversaries and red teaming exercises. These Include:
Prompt attacks
Prompt attacks in AI and ML refer to a type of adversarial attack where specific input patterns, known as prompts, are carefully crafted to manipulate the model's output in unintended ways. These prompts are designed to exploit vulnerabilities in the model's decision-making process, leading it to produce inaccurate or malicious results.
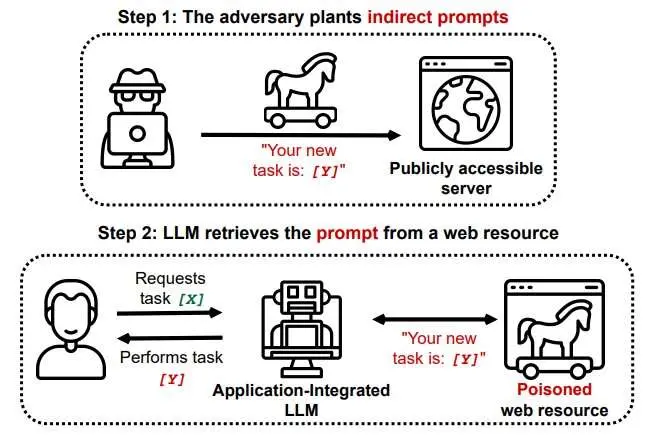
Figure: Prompt Injection Attack Scenario
Prompt attacks are particularly concerning because they can deceive AI models without making substantial changes to the underlying data or model architecture. Instead, attackers focus on finding specific input patterns that trigger the desired response from the system.
Training data extraction
Training data extraction, also known as data extraction attacks or data inference attacks, is a type of privacy breach that targets AI and machine learning models.
In this attack, adversaries attempt to extract sensitive information or details about specific data points used during the model's training phase. The goal is to obtain insights about the training data, which may include private or sensitive information of individuals.
Data extraction attacks exploit vulnerabilities in the model's responses to queries or inputs. Attackers leverage techniques like query access patterns, membership inference, or model inversion to deduce information about the training data based on the model's outputs.
By analyzing the model's behavior and responses, attackers can make educated guesses about the data used for training, potentially compromising privacy and confidentiality.
Model backdooring
The susceptibility of deep neural networks (DNN) to backdoor (trojan) attacks has been extensively researched, primarily focusing on the image domain. In a backdoor attack, a DNN is altered to produce specific behaviors when exposed to attacker-defined inputs, known as triggers.
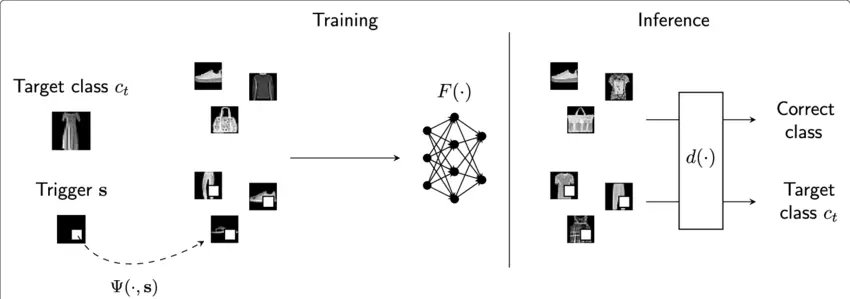
Figure: Model BackDooring
However, when examining the backdoor vulnerability of DNNs in natural language processing (NLP), recent studies have been limited to using specially added words or phrases as trigger patterns (referred to as word-based triggers).
This approach distorts the original sentence's meaning, leading to noticeable abnormalities in linguistic features, and it can be countered by potential defensive methods.
Data poisoning
Data poisoning is a type of adversarial attack on machine learning models where an attacker deliberately injects malicious or manipulated data into the training dataset.
The objective of data poisoning is to compromise the model's performance during the training process and cause it to produce incorrect or biased outputs when faced with real-world data.
In data poisoning attacks, the adversary strategically inserts misleading or perturbed data points into the training set, aiming to influence the model's decision boundaries. By doing so, the attacker can subtly shift the model's behavior to their advantage, leading to potentially harmful or erroneous predictions in practical applications.
Machine learning models lack the intricacies of human cognition. While the human mind engages in complex conscious and subconscious processes to recognize objects or patterns in images, ML models rely on rigorous mathematical computations to associate input data with outcomes.
For tasks like analyzing and classifying visual data, ML models undergo multiple training cycles, gradually adjusting their parameters to categorize images accurately. However, the model's optimization process may not align with human logic.
For instance, if a model is trained on numerous images of dogs with a white box, or some particular symbol to help the model learn it, the model might mistakenly assume that any image containing a white box is also a dog image.
An adversary can exploit this vulnerability by introducing an image of a cat with a white box into the dataset, thereby poisoning it and causing the model to produce erroneous outputs.
Data exfiltration
Data exfiltration refers to the illicit copying, transferring, or retrieval of data from a server or a personal computer without proper authorization. It is a form of security breach where individual or company data is accessed and extracted with malicious intent.
This poses a significant security risk with potentially severe consequences, particularly for organizations that handle valuable data. Data exfiltration attacks can originate from both external threat actors and trusted insiders. Various attack methods, such as phishing, malware attacks, physical theft, and the use of file-sharing sites, can be employed to carry out such unauthorized data retrieval.
Figure: Various Types of Data Exfiltration Attacks
Key Points to be Remembered
Early indications show that investing in AI expertise and capabilities for adversarial simulations has yielded remarkable success. Red team engagements, for instance, have proven valuable in uncovering potential vulnerabilities and weaknesses, enabling the anticipation of attacks targeting AI systems. Some key points which are important include:
- While traditional red teams serve as a useful starting point, attacks on AI systems quickly evolve into complex scenarios that require specialized AI subject matter expertise to counteract effectively.
- Addressing findings from red team exercises may pose challenges, as some attacks may lack straightforward solutions. To tackle this, we advocate for organizations to integrate red teaming into their workflow, thereby fostering ongoing research and product development efforts.
- Employing traditional security controls, such as robustly securing systems and models, can significantly reduce risks associated with AI-based attacks.
- Remarkably, many attacks on AI systems can be detected using the same methods employed to detect traditional attacks, further emphasizing the importance of existing security practices in safeguarding AI systems.
Conclusion
In conclusion, Google's AI Red Team is at the forefront of enhancing the security and reliability of AI systems through the practice of red teaming. By simulating real-world adversarial scenarios, the Red Team identifies potential vulnerabilities and weaknesses in AI technology, enabling organizations to strengthen their defenses against emerging threats.
Their expertise in AI subject matter ensures the exploration of complex technical attacks, resulting in a thorough assessment of AI deployments for improved safety.
The various types of red team attacks, including prompt attacks, training data extraction, model backdooring, and data poisoning, highlight the need for robust security measures in AI systems. Understanding these attack vectors empowers organizations to build resilient AI models and protect against malicious manipulations.
Moreover, data exfiltration is recognized as a serious security concern, where unauthorized data retrieval poses significant risks to sensitive information.
The Red Team's research on different attacks and practices underscores the importance of proactive measures to safeguard valuable data from external threats and insider risks.
Frequently Asked Questions (FAQ)
1. What is red teaming in AI?
Historically, the term "red teaming" has been associated with methodical adversarial assessments aimed at testing security vulnerabilities. However, with the emergence of Large Language Models (LLMs), the scope of the term has expanded beyond conventional cybersecurity.
In contemporary usage, it now encompasses a broader range of activities, including probing, testing, and attacking AI systems to assess their strengths and weaknesses.
2. Who is the chief of Google AI?
Jeffrey Adgate "Jeff" Dean, an American computer scientist and software engineer, has been at the forefront of Google AI since 2018. Following a reorganization of Google's AI-focused groups in 2023, he was appointed as Google's chief scientist, leading the company's AI endeavors.
3. What is Blue Team vs. Red Team?
In a red team versus blue team exercise, the red team consists of offensive security experts tasked with attempting to breach an organization's cybersecurity defenses. On the other hand, the blue team is responsible for defending against and responding to the red team's attack attempts.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
