

Multi-View 3D reconstruction in autonomous vehicles, How it works?

Since the autonomous driving industry got its start at the 2005 DARPA Grand Challenge, numerous companies have trained and tested machine learning models to control every aspect of autonomous driving. The market leaders are continually updating and improving their ensembles of computer vision and control systems models to build safer, more efficient, and more adaptable autonomous vehicles.
Video cameras are becoming increasingly common in autonomous vehicles. This provides us a strong opportunity to reconstruct moving vehicles around our vehicle. The shapes (even sparse) and motions of the vehicles can be invaluable to analyze the surroundings, including vehicle type, speed, density, trajectory and predicting events to avoid collisions. Vehicle-to-Vehicle (V2V) communication systems can provide such analysis to other autonomous vehicles around our vehicle.
In the foreseeable future it will be commonplace for various land vehicles to be equipped with 3D sensors and systems that reconstruct the surrounding area in 3D. This technology can be used as part of an advanced driver assistance system (ADAS) for semi-autonomous operation (auto-pilot), or for fully autonomous operation, depending on the level of technological maturity and legal regulations.
Existing robotic systems are mostly equipped with active 3D sensors such as laser scanning devices or time-of-flight (TOF) sensors. 3D sensors based on stereo cameras cost less and work well even in bright ambient light, but the 3D reconstruction process is more complex. We can see an example of 3D Reconstruction of a street scene in the image below.

Img: 3D Reconstruction
Introduction
For a human, it is usually an easy task to get an idea of the 3D structure shown in an image. Due to the loss of one dimension in the imaging process, the estimation of the true 3D geometry is difficult and a so-called ill-posed problem, because usually infinitely many different 3D surfaces may produce the same set of images.
The goal of multi-view 3D reconstruction is to infer the geometrical structure of a scene captured by a collection of images from various different viewpoints. Usually the camera position and internal parameters are assumed to be known or they can be estimated from the set of images. By using multiple images, 3D information can be (partially) recovered by solving a pixel-wise correspondence problem.
The goal of urban reconstruction algorithms, to be more specific, is to produce fully automatic, high-quality, dense reconstructions of urban areas by addressing inherent challenges such as lighting conditions, occlusions, appearance changes, high-resolution inputs, and large scale outputs. In the context of autonomous driving, 3D reconstructions can be used for static obstacle detection (traffic lights, road signs, etc.) and avoidance or precise localization.
Let us begin by understanding more about what Multi-View 3D Reconstruction is.
What is multi-view 3D reconstruction?
Multi-View 3D Reconstruction or 3D reconstruction from multiple images is the creation of three-dimensional models from a set of images. It is the reverse process of obtaining 2D images from 3D scenes.
The essence of an image is a projection from a 3D scene onto a 2D plane, during which the depth is lost. The 3D point corresponding to a specific image point is constrained to be on the line of sight.
From a single image, it is impossible to determine which point on this line corresponds to the image point. If two images are available, then the position of a 3D point can be found as the intersection of the two projection rays. This process is referred to as triangulation, which is also used in Stereo Vision.
Explore Stereo Vision in Self-Driving Cars
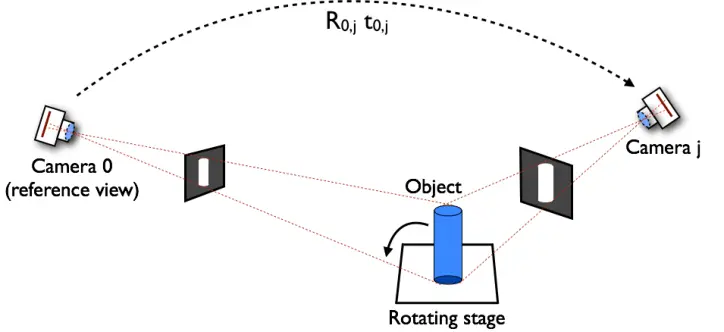
Stereo vision was the process of getting depth information from two images from the same side. In multi-view 3D reconstruction, multiple images of the object from multiple different viewpoints (all sides) are used to obtain the complete 3D shape of the object.
So, the goal of multi-view 3D reconstruction is to infer 3D geometry from a set of 2D images by inverting the image formation process using appropriate prior assumptions. In contrast to two-view stereo, multi-view reconstruction algorithms recover the complete 3D shape of an object by inferring shape from many viewpoints, as we can also see in the example below.

Img: Multi-View 3D Reconstruction
Generally, Light Detection and Ranging (LIDAR) devices are used in autonomous vehicles and robots to get the 3D measurements. LIDAR contains laser scanners which directly give the 3D information. However, these scanners are very expensive and prone to interference and noise due to bulk hardware present in the device.
To address this problem, cameras can be used as an alternative as they are lighter and cheaper compared to sensors like Lidars. Multi-views of an object of interest are obtained using multiple cameras or one moving camera and they are given as input to algorithms like structure from motion (SFM) algorithm to compute the 3D shape.
In the SFM algorithm, an appropriate set of mixed feature extraction techniques are employed to get a good number of 3D inlier points. The obtained results are then visualized as 3D point clouds and used for further processing like 3D Scene flow, Object Tracking, Localization, Path Planning, etc.
You can read more about 3D Scene flow and Object Tracking in our other blogs. (Link)
One very common method for 3D Reconstruction is using multiple stereo images from different viewpoints. Using stereo vision, 2.5D depth maps can be obtained. We can fuse multiple such 2.5D depth maps using 3D fusion techniques to get the complete 3D structure of an object. The system of 3D reconstruction and mapping based on stereo vision is also known as “Simultaneous Localization and Mapping” (SLAM).
But today, as with many other algorithmic challenges, deep neural networks have surpassed the performance of these earlier approaches. Deep CNN-based methods have so far achieved the state of the art results in multi-view 3D object reconstruction. The two core modules of these methods are view feature extraction and multi-view fusion.
But why do we need Multi-View 3D Reconstruction in Autonomous Vehicles? We’ll discuss this in the next section.
Why do we need multi-view 3D reconstruction in autonomous vehicles?
Reconstruction allows us to gain insight into qualitative features of the object which cannot be deduced from a single plane of sight, such as volume and the object relative position to others in the scene.
In the context of autonomous driving, 3D reconstructions can be used for detecting and avoiding obstacles like traffic lights, road signs, etc.
It can also be used for precise localization of the vehicle, determination of available free space and accurate path planning, as we can also see in the image below.

Img: 3D Reconstruction for Path Planning
However, despite significant research in the area, reconstruction of multiple dynamic rigid objects like vehicles remains hard. In the next section, we’ll discuss a few challenges that are generally faced while trying to achieve Multi-View 3D Reconstruction.
Challenges
There has been a rich history of detection, tracking and reconstruction of vehicles. Their performances are progressively improving thanks to recent advances in deep learning. In particular, detection of parts of vehicles like wheels, headlights, doors, etc. across multiple views is becoming increasingly reliable.
However, the detected part locations are still not precise enough to directly apply triangulation-based 3D reconstruction methods, and are incomplete in the presence of occlusions. For the same reason, tracking via per-frame detection is not stable enough to be useful for structure-from-motion approaches for 3D reconstruction.
Feature tracking works well within each view but is hard to correspond across multiple cameras with limited overlap in fields of view or due to occlusions. On the other hand, advances in deep learning have resulted in strong detectors that work across different viewpoints but are still not precise enough for triangulation-based reconstruction.
Reconstruction of objects observed from wide-baseline, uncalibrated and asynchronized cameras is difficult too. Corresponding feature points across wide-baseline views is near impossible given that each camera sees only parts of a vehicle like front, one side, or back at any given time instant.
Inherent challenges such as lighting conditions, occlusions, appearance changes, high-resolution inputs, and large scale outputs remain a big issue too.
Particularly, reconstructing moving vehicles in a busy intersection is hard because of severe occlusions. Furthermore, the cameras are often asynchronized, provide wide-baseline views with little overlap in fields of view and need to be calibrated each frame as they are often not rigidly attached and sway because of wind or vibrations.
Summary
Multi-View 3D reconstruction is the task of obtaining complete 3D shapes of objects from multiple 2D images.
In the last decade, great advances have been made in multi-view reconstruction.
An open question that remains for the autonomous driving problem is what kind of accuracy and completeness are necessary to realize safe mapping, localization, and navigation.
For localization and loop-closure detection high accuracy is required. In contrast, for obstacle avoidance, high completeness is necessary in order not to miss any obstacle.
Several challenges like occlusions, wide-baseline views, difficulty in tracking a feature across multiple views makes the task difficult.
Even after the recent advances in technology and despite the claims by several companies, we still need to wait for at least a decade to see completely safe autonomous vehicles on the roads.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
