

VideoMimic: Learning Humanoid Robot Control from Monocular Video Using Real-to-Sim-to-Real Reinforcement Learning
VideoMimic turns monocular human videos into deployable humanoid robot policies. By combining 4D reconstruction, scene geometry, and reinforcement learning, it enables context-aware robot control without motion capture or handcrafted rewards.


Imagine teaching a humanoid robot to climb stairs or sit on a bench just by showing it a smartphone video. No motion capture suits. No handcrafted reward functions. No scripted lab terrain. Only a monocular RGB video of a human performing a task in the real world.
This is the core idea behind VideoMimic. It is a real-to-sim-to-real pipeline that turns everyday videos into transferable, environment conditioned control policies for humanoid robots.
For engineers in embodied AI, this marks a structural shift. It unifies monocular 4D reconstruction, physics simulation, and reinforcement learning into one deployable system. Instead of separating perception and control, VideoMimic connects them in a single data driven loop.
Contextual Control
Video source
Most imitation learning systems focus on copying motion trajectories. However, copying motion alone often fails in real environments. A policy trained on flat ground may break on stairs or uneven terrain. It lacks awareness of the surrounding geometry.
Reward engineered reinforcement learning systems can adapt to terrain, but they require heavy manual design. Each new skill often needs new rewards and scripted environments. This limits scalability.
VideoMimic addresses this issue through contextual control. The robot learns actions conditioned on 3D structure. The key insight is simple: motion without geometry is incomplete. The robot must learn how body dynamics interact with the environment.
To achieve this, VideoMimic reconstructs both human motion and scene geometry from a single monocular video. The result is behavior grounded in physical context rather than pure pose tracking.
The Real-to-Sim-to-Real Pipeline
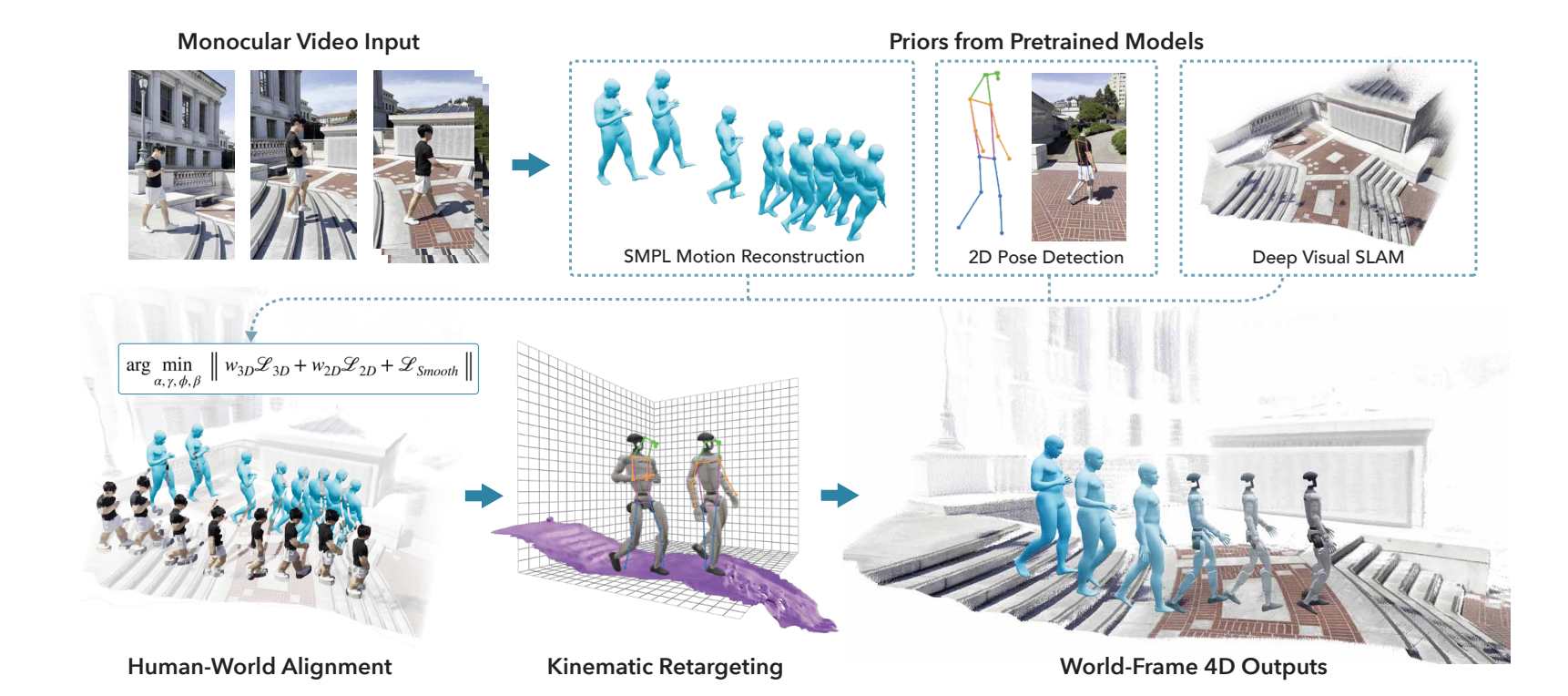
From input to final output
Image source
VideoMimic follows a structured pipeline. It converts a monocular RGB video into a deployable humanoid policy. The system moves through reconstruction, scene processing, reinforcement learning, and real world deployment.
Each stage maintains a consistent world frame. Motion, geometry, and control remain aligned. This consistency is essential. Without it, policies would learn mismatched physical relationships and fail outside simulation.
Monocular 4D Human Scene Reconstruction
The process begins with a casually recorded RGB video. From this input, VideoMimic reconstructs per-frame 3D human motion using SMPL parameters. At the same time, it recovers a dense scene point cloud.
Unlike many pose estimation systems, it does not operate only in a camera-relative frame. Instead, it resolves metric scale using a human height prior. It jointly optimizes global translation, global orientation, local pose parameters, and scene scale.
The optimization uses a Levenberg Marquardt solver implemented in JAX. Once compiled, it processes a 300-frame sequence in about 20 milliseconds on an NVIDIA A100 GPU.
The output is a metrically aligned human trajectory embedded in a consistent 3D scene. This step is critical. Without correct scale and world alignment, the reconstruction would not support meaningful physics simulation.
From Point Clouds to Simulator-Ready Terrain
Monocular point clouds contain noise and artifacts. Physics engines require structured geometry. VideoMimic first aligns the reconstruction to gravity. It then filters the point cloud and converts it into a lightweight mesh.
For a 300 frame sequence, this stage takes around 60 seconds. Gravity alignment takes about 5 seconds. Filtering and meshing take roughly 55 seconds.
The mesh supports heightmap generation and collision modeling during reinforcement learning. After this, motion retargeting maps human trajectories onto the robot embodiment.
Retargeting solves a nonlinear optimization problem over joint angles, root poses, and embodiment scale factors. It enforces joint limits, contact consistency, and collision avoidance. A 300 frame clip is retargeted in about 10 seconds on a single A100 GPU.
At this point, a monocular video has become a physically feasible robot trajectory inside a structured 3D environment.
Reinforcement Learning in Simulation
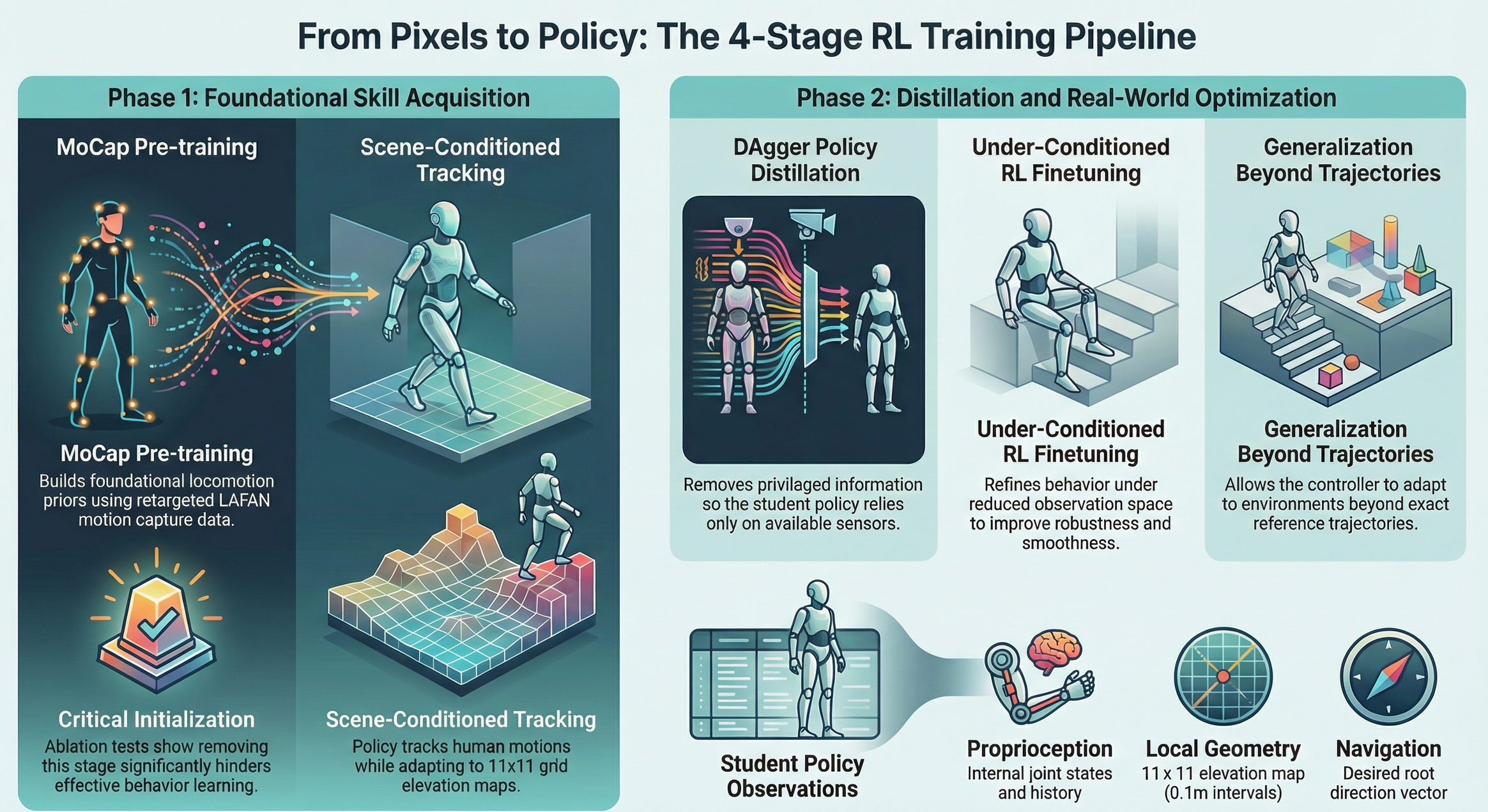
Reward driven improvement
Policy learning takes place in IsaacGym using Proximal Policy Optimization (PPO). Training proceeds in four structured stages to ensure stability and generalization.
The first stage uses motion capture pre training. LAFAN motion data is retargeted to the Unitree G1 humanoid. This builds locomotion priors and stabilizes learning. Ablation experiments show that removing this stage significantly weakens performance.
The second stage introduces scene conditioned tracking. The policy receives terrain input through an 11×11 elevation map sampled at 0.1-meter intervals around the torso. The robot learns to track reconstructed motion while adapting to stair height and terrain slope.
The third stage applies DAgger for policy distillation. The student policy no longer depends on privileged target joint angles. Instead, it relies only on proprioception, local heightmaps, and desired root direction. These inputs are available at deployment.
The final stage performs reinforcement learning fine tuning under the reduced observation space. This improves smoothness, robustness, and generalization beyond exact reference trajectories.
Reconstruction Performance
VideoMimic was evaluated on the SLOPER4D dataset. Compared to prior methods such as TRAM and WHAM, it achieves stronger results in both motion accuracy and geometry reconstruction.
It reports a world frame MPJPE of 696.62 compared to 954.90 for TRAM. It also reports a Chamfer Distance of 0.75 compared to 10.66 for TRAM.
These results highlight the benefit of joint human scene optimization. Accurate terrain reconstruction directly impacts control learning. Incorrect geometry produces inconsistent physics during training and weakens policy performance.
Real World Deployment
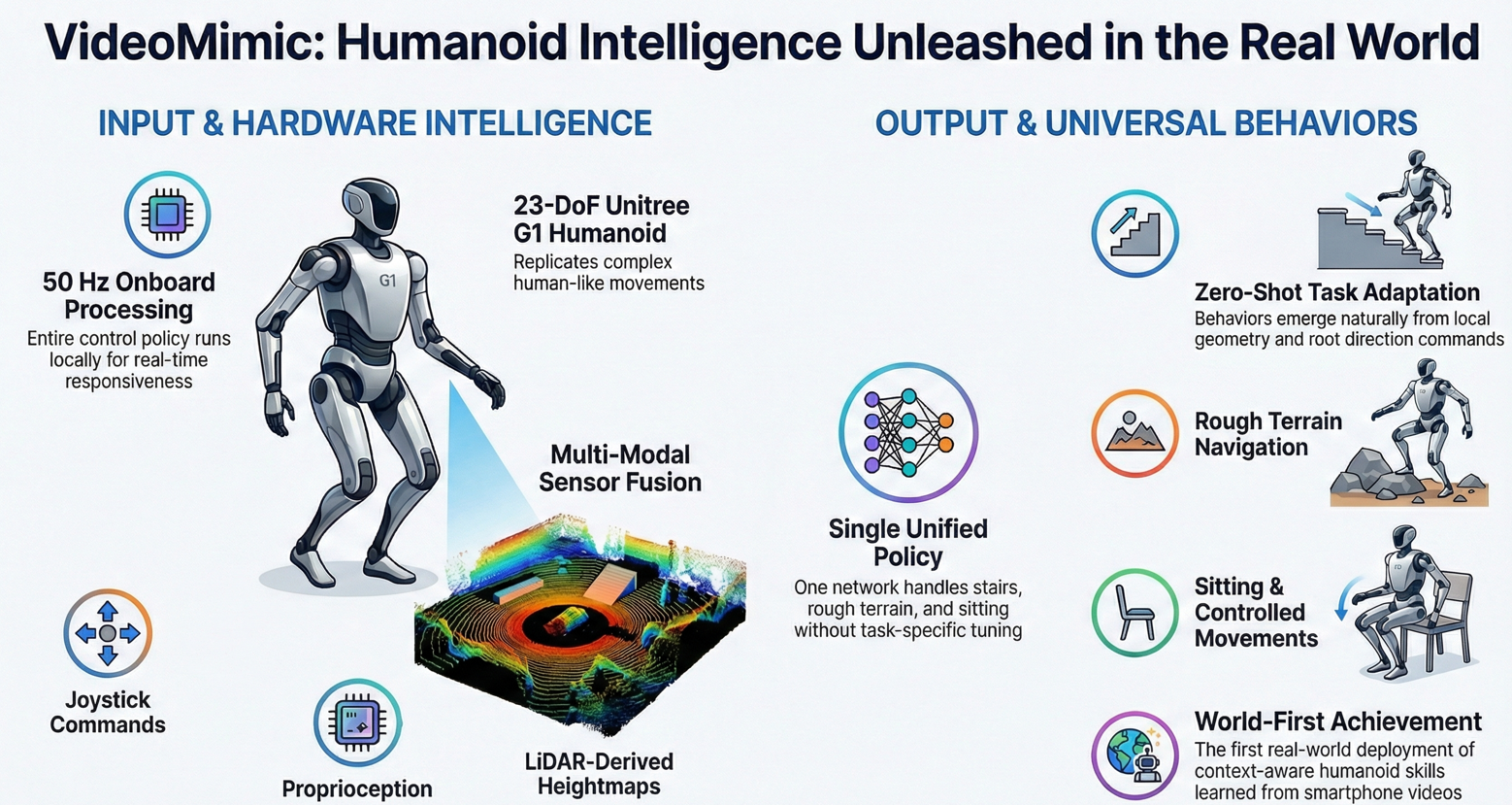
Connecting motion across contexts
The trained controller runs on a 23-DoF Unitree G1 humanoid at 50 Hz onboard. The robot receives proprioceptive inputs, a LiDAR-derived heightmap, and joystick-based root direction commands.
A single unified policy enables stair climbing, stair descent, rough terrain traversal, sitting, and standing. No task specific tuning is required. All behaviors emerge from geometry conditioned control.
This represents the first real world deployment of a context aware humanoid policy learned directly from monocular human videos.
Limitations
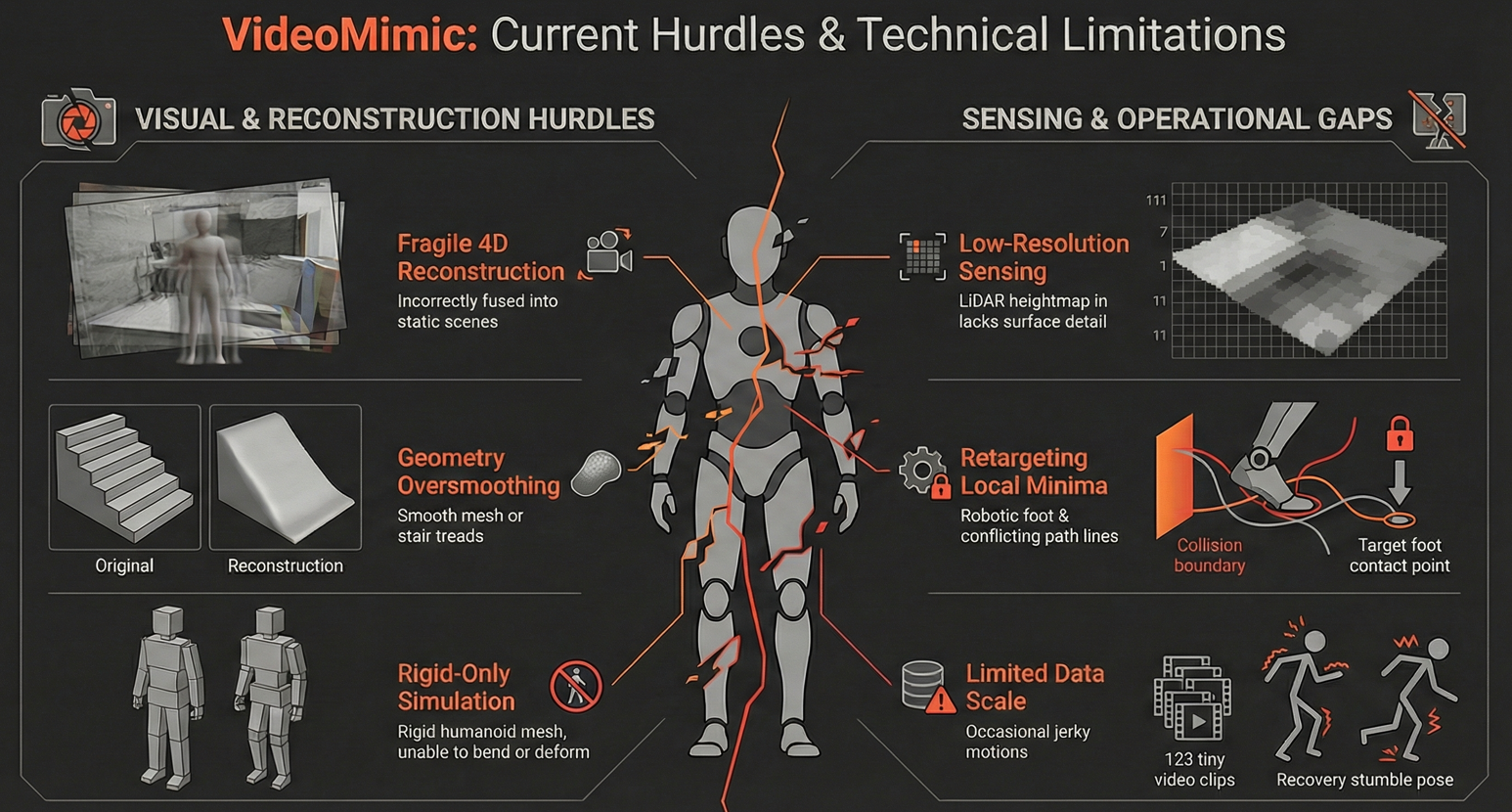
Reconstruction limitations
While VideoMimic shows strong real world results, several practical limitations remain across reconstruction, retargeting, sensing, simulation, and data scale.
Reconstruction can suffer from camera pose drift, which creates ghost layers. Dynamic human points may merge into the static scene. Low texture environments degrade reconstruction quality. Aggressive filtering may create holes that complicate meshing. NKSR reduces noise but can over smooth fine geometry like narrow stair edges.
Retargeting assumes scaled human poses are feasible for the robot. This may fail in cluttered scenes. Conflicts between foot contact enforcement and collision avoidance can trap the optimizer in poor local minima. Reinforcement learning later compensates for these imperfections.
At deployment, the policy uses only proprioception and an 11x11 LiDAR heightmap. This coarse grid works for stairs and terrain but lacks resolution for fine contact reasoning or manipulation.
Simulation models the environment as a single rigid mesh. Extending to articulated or deformable objects would require richer simulation and reconstruction methods.
The distilled policy is trained on only 123 video clips. Limited diversity sometimes leads to recovery behaviors and slightly jerky motion. Larger datasets and real world fine tuning would likely improve smoothness and robustness.
Conclusion
VideoMimic shows that humanoid robots can learn context aware whole body skills directly from monocular human videos. By reconstructing metric scale motion and scene geometry, retargeting trajectories, and training reinforcement learning policies in simulation, it turns passive video into executable behavior.
Its main contribution is architectural. Perception, geometry, and control operate as one integrated loop rather than separate modules.
For engineers, this reframes video as a scalable supervision signal for embodied intelligence. It moves robotics closer to a future where machines learn by observing the world around them.
How does VideoMimic learn robot control from a single monocular video?
VideoMimic reconstructs metric-scale 3D human motion and scene geometry from RGB video, retargets the motion to a humanoid robot, and trains a reinforcement learning policy in simulation before deploying it in the real world.
Why is geometry conditioning important in humanoid imitation learning?
Pure motion copying ignores environmental structure. Geometry conditioning allows the robot to adapt actions based on terrain like stairs, slopes, or uneven ground, improving robustness and real-world transfer.
What makes VideoMimic different from traditional imitation or RL systems?
It unifies 4D reconstruction, physics simulation, and reinforcement learning in one pipeline, eliminating handcrafted reward design and separating perception from control.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
