

LLaMA 4 Explained - Everything You Need to Know
LLaMA 4, launched by Meta in April 2025, is a breakthrough AI model. With Scout and Maverick already live (and Behemoth coming), it blends speed, efficiency, and multimodal power. Its open-weight, Mixture-of-Experts design shows that open AI can rival GPT-4.5, Gemini, and other closed systems.


On April 5, 2025, Meta released a new set of AI models called Llama 4, marking a significant step in the AI world. At first, many critics doubted whether an open-weight model could compete with established systems like GPT-4.5, Claude 3.7, and Gemini 2.0.
Surprisingly, the new models - Scout, Maverick, and the soon-to-be released Behemoth - have gone beyond expectations, proving to be more powerful and versatile than initially thought.
What makes them stand out is that they don’t just handle text anymore; they can also interpret images, process much longer conversations, and deliver results that rival some of the most advanced AI systems available today.
This article explores how these models work, how well they perform, how easy they are to use, and how Meta is positioning them to compete with other leading AI tools.

LLaMA 4
What Is LLaMA 4?
LLaMA 4 is a large language model (LLM) launched by Meta which is their newest and smartest AI model . Think of it as a super-smart robot brain that can not only read, write, and answer questions like ChatGPT, but also understand images, solve complex problems, and handle very long conversations without forgetting context.
So, what makes LLaMA 4 different from older models? Here's the list:
- Open-weight : Anyone can use and build on it
- Faster and Smarter
- Strong at handling long conversations, understanding and writing
- More energy-efficient - Uses a special “Mixture-of-Experts (MoE)” design that does not consume massive computing power
- Great at solving logic problems and math
- Multimodal-works well with both text and images
But this is just the start. Let’s dive deeper into how LLaMA 4 actually works under the hood and why it’s a big deal in the AI world
How Does LLaMA 4 Work?
People are excited about LLaMA4 not just because it's smart and fast, but because of the unique way it works.
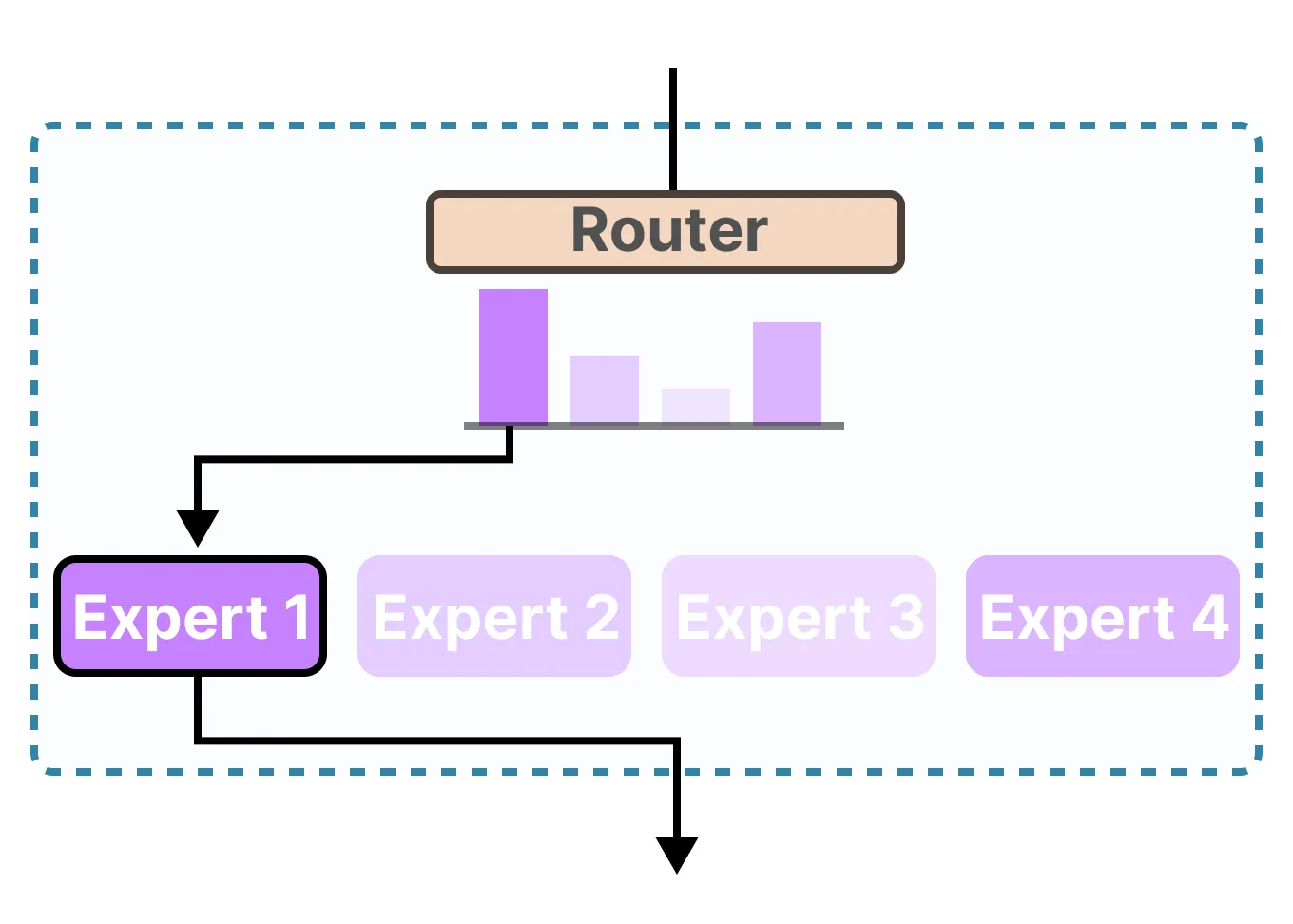
Unlike older AI models that use the traditional "Transformer" method that runs the entire network for every single word making it slow and expensive, LLaMA 4 does something different. LLaMA 4 changes this with a method called Mixture-of-Experts (MoE).
Because of this, LLaMA 4 can be huge and powerful, with hundreds of billions of settings (parameters), but still work quickly and not cost too much to run.
What is MoE?
Imagine you ask a question in a classroom full of 100 experts. Instead of all 100 answering, only the 2-3 experts knowing the topic best respond.
That's exactly what LLaMA 4 does. For every word or token, it only activates a few "experts" in the model instead of traversing the whole thing.
This smart move is the reason LLaMa 4 can compete with giants like GPT-4.5 while still being open and cost-effective.
Mixture-of-Experts
What’s Special About LLaMA 4?
LLaMA 4 is not just one model - it’s actually a whole family of models, each designed for certain type of tasks. We can think of it as three siblings: one being lightweight but sharp, the second one being all-rounder and strong, and the third (still in growing phase) is expected to be giant.
1. LLaMA 4 Scout
Scout is the "lightweight genius" of the family.
- It can read and understand long documents.
- It runs smoothly on a single GPU, making it budget-friendly.
- Perfect for customer support, chatbots, personal agents, etc.
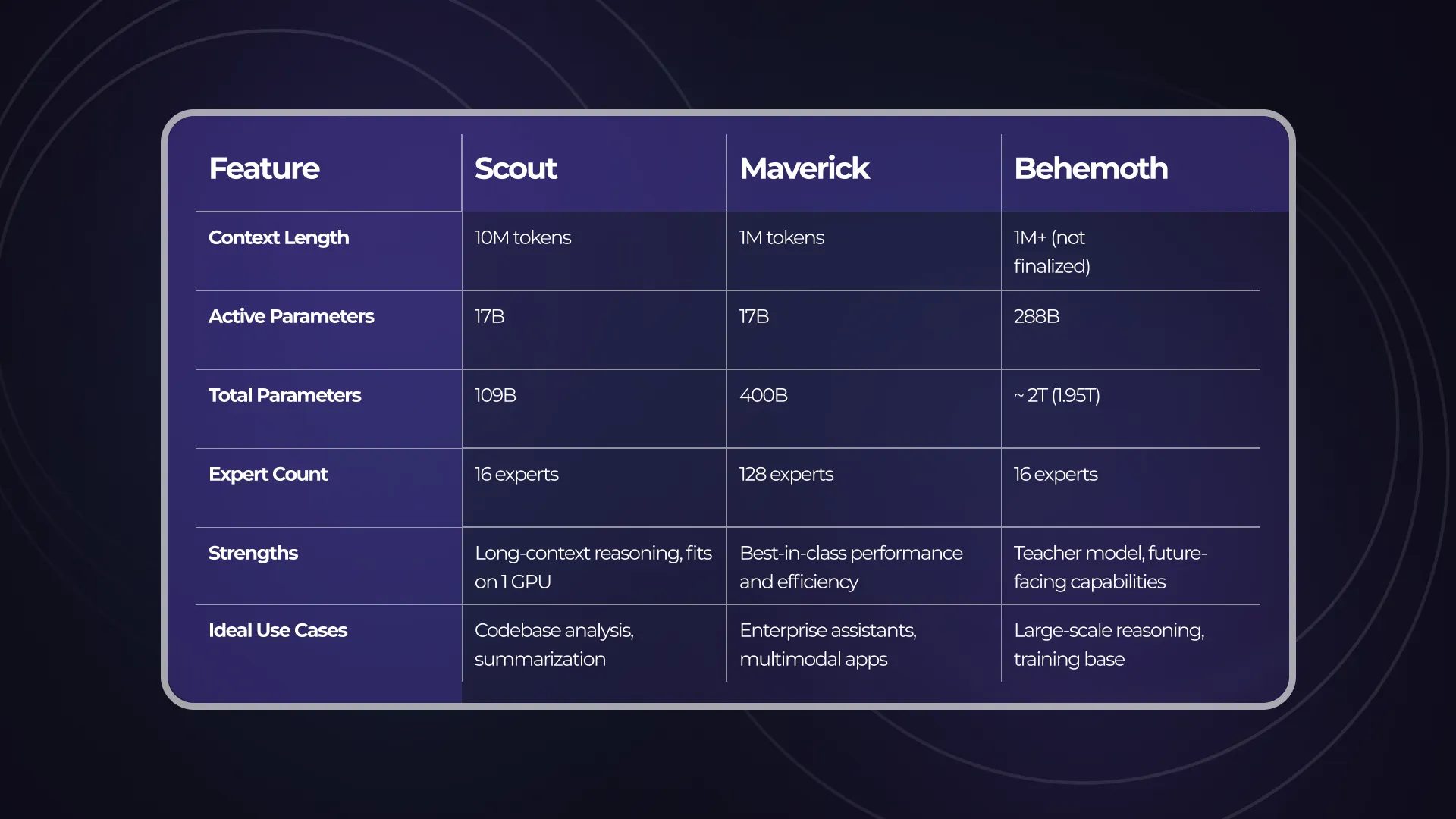
Scout Model Specifications:
- Active Parameters: 17B (out of 109B total, 16 experts)
- Context Length: Up to 10 million tokens
- Hardware Requirements: Single H100 GPU (INT4 support)
- Cost Efficiency: ~$0.09 per million tokens
2. LLaMA 4 Maverick
Maverick is the main workhorse - the one Meta itself uses in apps like Facebook, Instagram, and WhatsApp.
- Smarter than previous models as it can see and understand text along with images.
- Can reason better, explain things clearly, and answer tough questions making it great for Multilingual chat, generative content, enterprise use cases, etc.
- Competes with the best AI models in the world like GPT-4o and Gemini 1.5
Maverick Model Specifications
- Active Parameters: 17B (out of 400B total, 128 experts)
- Context Length: 1 million tokens, multimodal inputs supported
- Hardware: FP8 on H100 DGX-class systems
- Languages: Supports 12 languages natively
- Benchmark Leadership: Outperforms GPT-4.5 in several tasks
3. LLaMA 4 Behemoth (Coming Soon)
Behemoth is still being trained, but it's expected to be a game-changer.
- Will be the most powerful model in the LLaMA family.
- Will act as "teacher model" to train and teach other smaller models.
- Designed for Research, distillation base model, reasoning-intensive tasks.
Behemoth Model Specifications
- Active Parameters: 288B
- Total Parameters: Estimated ~2 trillion
- Training Efficiency: 390 TFLOPs/GPU using FP8
- Benchmarks:
- MATH-500: 87.3% (vs. GPT-4.5 at 83.9%)
- GPQA Diamond: 65.1%
LLaMA 4 Family
Is It Free?
Yes! One of the coolest things about LLaMA 4 is that it is open-weight. What does this mean:
- Developers and researchers can download it and use it for free
- You can build apps, tools, or chatbots using LLaMA 4
Reminder: apps exceeding 700 million users need a special license from Meta.
What Can People Do With LLaMA 4?
LLaMA 4 is not just powerful – it can be used in many interesting ways:
- Chatbots for customer service, helping companies provide faster responses
- AI tutors for students
- Tools that help lawyers or doctors helping them summarize long documents
- Apps that write or fix computer code
- Tools that understand both pictures and text
You can also try out LLaMA 4 in Meta apps like Facebook, Instagram, WhatsApp, and Messenger - just look for the Meta AI icon!
Hands-on Llama 4-Scout
We can either run the official Colab notebook provided on HuggingFace or follow the step-by-step guide below.
LLaMA 4 Scout
Steps:
Step 1: Environment Setup
To start, we install the essential libraries:
!pip install -U transformers
Transformer library is used to run and load LLaMA 4 Scout model.
Step 2: Authenticate with Hugging Face
To access gated models, log in using your Hugging Face account:
from huggingface_hub import login
login(new_session=False)
Step 3: Run the Pipeline
The simplest way to run text + image queries is using a pipeline:
from transformers import pipeline
pipe = pipeline("image-text-to-text", model="meta-llama/Llama-4-Scout-17B-16E-Instruct")
messages = [
{
"role": "user",
"content": [
{"type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/p-blog/candy.JPG"},
{"type": "text", "text": "What animal is on the candy?"}
]
},
]
pipe(text=messages)
Step 4 (Optional / Advanced): Load Model Directly
from transformers import AutoProcessor, AutoModelForImageTextToText
processor = AutoProcessor.from_pretrained("meta-llama/Llama-4-Scout-17B-16E-Instruct")
model = AutoModelForImageTextToText.from_pretrained("meta-llama/Llama-4-Scout-17B-16E-Instruct")
inputs = processor.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=40)
print(processor.decode(outputs[0][inputs["input_ids"].shape[-1]:]))
Step 5: Set Hugging Face Token
For gated models, set your Hugging Face token as an environment variable:
import os
os.environ['HF_TOKEN'] = 'YOUR_TOKEN_HERE'
Step 6: Use via Hugging Face + OpenAI API
We can also interact with LLaMA 4 Scout using an API-based approach:
import os
from openai import OpenAI
client = OpenAI(
base_url="https://router.huggingface.co/v1",
api_key=os.environ["HF_TOKEN"],
)
completion = client.chat.completions.create(
model="meta-llama/Llama-4-Scout-17B-16E-Instruct",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Describe this image in one sentence."},
{"type": "image_url", "image_url": {"url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"}}
]
}
],
)
print(completion.choices[0].message)
Conclusion
LLaMA 4 is more than just another AI model - it’s a powerful, versatile, and accessible family of models that can handle text, images, long conversations, and complex problem-solving.
From the lightweight Scout for personal agents, to Maverick for enterprise and multimodal tasks, and the upcoming Behemoth for research and large-scale applications, LLaMA 4 proves that open-weight AI can compete with the best in the world.
Whether you’re a developer, researcher, or just curious about AI, LLaMA 4 opens up a world of possibilities — and the best part? It’s freely available for most use cases.
FAQs
What makes LLaMA 4 different from older models?
It’s faster, smarter, energy-efficient, handles long conversations, solves logic and math problems, and works with both text and images. And the best part -
It is open-weight model.
What are the different models in the LLaMA 4 family?
- Scout: Lightweight, ideal for personal agents and chatbots.
- Maverick: Main workhorse, multimodal, used in Meta apps.
- Behemoth: Coming soon, designed for research and large-scale tasks
Do I need a powerful computer to run LLaMA 4?
It depends on the model. Scout runs on a single GPU, making it budget-friendly, while Maverick and Behemoth need high-end setups.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
