

6 LLMs Applications No One Is Talking About
Large Language Models (LLMs) are reshaping fields from computational biology and code generation to creative arts, healthcare, robotics, and synthetic data generation, offering innovative solutions beyond common applications like chatbots.

A Large language model (LLM) is a form of machine learning model capable of performing various natural language processing (NLP) tasks, including text generation, text classification, conversational question answering, and language translation.
The term "large" pertains to the substantial number of values (parameters) that the language model can autonomously adjust as it learns. Some of the most successful LLMs boast billions of parameters.
These models undergo training using vast volumes of data and utilize self-supervised learning to predict the subsequent token in a sentence, considering the context around it. This iterative process continues until the model achieves a satisfactory level of precision.
Table of Contents
- Exploring the Frontiers of AI: Applications and Innovations
- Computational Biology
- Code Generation with LLMs
- Creative Work
- Medicine and Healthcare
- LLMs in Robotics
- Utilizing LLMs for Synthetic Datasets
- Conclusion
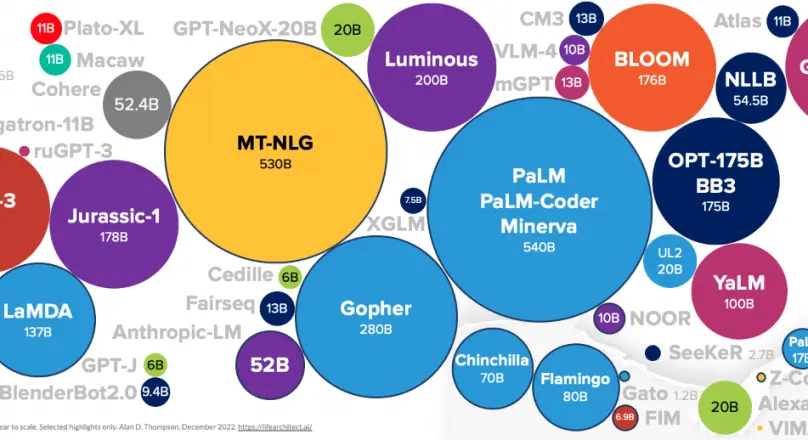
Figure: Datasets used for Training LLMs
Large Language Models (LLMs) have ushered in a new era of natural language processing, revolutionizing the way we interact with and understand language.
These sophisticated AI systems, equipped with massive computational power and extensive training, have found a multitude of applications across various domains.
From enhancing communication to automating complex tasks, LLMs have demonstrated their versatility and transformative potential. Some of the key applications discussed in this blog in detail include:
- Conversational Agents and Chatbots: LLMs power advanced chatbots and virtual assistants that engage in natural and meaningful conversations with users.
- Content Generation: LLMs are capable of generating high-quality content, including articles, blog posts, social media posts, and more. They can assist content creators by suggesting ideas, writing drafts, and even auto-completing sentences.
- Language Translation: LLMs have enabled significant advancements in machine translation. They can translate text from one language to another while maintaining context and nuance, facilitating global communication.
- Text Summarization: LLMs can automatically generate concise and coherent summaries of lengthy articles, documents, or reports, aiding in information extraction and comprehension.
- Sentiment Analysis: LLMs excel at analyzing and understanding the sentiment expressed in text. This is valuable for gauging public opinion, conducting market research, and monitoring social media sentiment.
Exploring the Frontiers of AI: Applications and Innovations
In the ever-evolving landscape of artificial intelligence (AI), Large Language Models (LLMs) have emerged as powerful tools, transforming a multitude of domains across various industries.
These models, with their natural language processing capabilities, have revolutionized the way we approach complex tasks, enabling advancements in computational biology, code generation, creative work, medicine, and robotics.
In this comprehensive exploration, we delve into the diverse applications and innovations driven by LLMs, showcasing their potential to reshape the boundaries of AI and shape the future of technology-driven endeavors.
From unraveling the intricate patterns in genetic sequences to automating programming tasks, LLMs demonstrate their versatility by adapting to specialized challenges and delivering remarkable outcomes.
Creative industries, too, witness a renaissance as LLMs engage in co-writing stories, generating poetry, and even aiding in visual content creation. In the realm of medicine, LLMs offer solutions for medical question answering, clinical information extraction, and information retrieval, promising to revolutionize healthcare processes.
Figure: Writing poetry using LLMs
The integration of LLMs in robotics opens doors to advanced task execution, code generation, and multi-modal interaction, pushing the boundaries of automation and intelligent decision-making.
Moreover, LLMs unleash the potential of synthetic data generation, introducing novel strategies to produce datasets for training specialized models, transcending conventional limitations. While these applications hold transformative potential, they also bring forth challenges, including the need to ensure accurate representation of real-world distributions and mitigate biases.
This section embarks on a journey through these captivating domains, shedding light on the groundbreaking contributions of LLMs, their promise, and their limitations.
As we navigate this landscape of AI innovations, we witness how LLMs are not merely tools but catalysts that propel us toward a future where AI seamlessly intertwines with various facets of human endeavor, amplifying capabilities and opening new vistas of exploration.
Below, we discuss more over applications of LLM, no one is talking about.
1. Computational Biology
In the realm of computational biology, the focus lies on non-textual data that presents analogous challenges in sequence modeling and prediction. A prominent application of LLM-like models in the field of biology is the generation of protein embeddings from amino-acid or genomic sequences.
Protein Embeddings
The Protein embeddings serve as inputs for various tasks, such as structure prediction, novel sequence creation, and protein classification. Despite the prowess of protein language models on academic datasets, their potential for real-world applications like drug design remains uncertain.
The primary goal of protein language models is their deployment in practical projects like drug design. However, evaluations typically target smaller or specialized datasets, overlooking how these models could contribute to protein design in controlled environments.
Elnaggar et al. devised LLM architectures to derive embeddings from protein amino acid sequences, benefiting per-amino acid and per-protein prediction tasks.
Notably, ProtT5, the best-performing architecture, achieved state-of-the-art results in protein secondary structure prediction. Wu et al. predicted antibody backbone and side-chain conformations using similar methods.
Lin et al. adopted the Evolutionary Scale Model Transformer-2 (ESM-2) to train a protein LLM. Scaling from 8 million to 15 billion parameters yielded significant performance enhancements, outperforming ProtT5 in protein structure prediction benchmarks.
ESMFold, an innovation introduced, utilizes ESM-2 embeddings for atomic resolution prediction from a single sequence, demonstrating faster inference times compared to existing models.
Furthermore, researchers harnessed ESM-1 and ESM-2 models to generate protein embeddings for diverse applications, including enzyme-substrate class prediction, protein design, disease-causing mutation identification, and antibody evolution.
Chen et al. introduced the xTrimoPGLM model, which simultaneously handles protein embedding and generation tasks. This model outperformed existing approaches across multiple tasks.
Innovative approaches expanded the scope of protein embedding models. Outeiral and Deane used codon sequences as inputs instead of amino acids, enhancing model capabilities.
Madani et al. trained ProGen on protein amino acid sequences with control tags to generate functional sequences. For antibodies, Shuai et al. developed an Immunoglobulin Language Model (IgLM) for sequence generation. This model demonstrated controllable generation of antibody sequences.
Genomic Analysis
In genomic analysis, LLMs enable the understanding of mutation effects and the prediction of genomic features from DNA sequences. Hierarchical LLMs like GenSLMs were introduced to accommodate longer sequences, pre-trained on gene sequences and evaluated for tasks like variant identification.
Nucleotide Transformers and HyenaDNA also emerged as genomic language models with improved performance and larger sequence processing capabilities.
In essence, LLM applications in computational biology extend to protein embeddings, structure prediction, genomic analysis, and more. These models exhibit potential for advancing research, prediction, and practical applications in the biological domain.
2. Code Generation with LLMs
One of the most advanced and widely adopted applications of Large Language Models (LLMs) involves generating and completing computer programs in various programming languages.
This section focuses on LLMs specifically tailored for programming tasks, although it's important to note that general chatbots, partially trained on code datasets like ChatGPT, are increasingly used for programming tasks as well.

Figure: Code Generation using LLMs
In the realm of code generation, LLMs are utilized to create new code based on given specifications or problem prompts. Numerous programming-specific LLMs and approaches have been proposed for this purpose.
For instance, Chen et al. introduced Codex, a fine-tuned GPT-3 LLM specialized in generating Python functions from doc strings.
Codex outperformed other models on evaluations, particularly when fine-tuned on filtered datasets. Another effort by Chen et al. aimed to enhance Codex's performance through a self-debugging prompting approach, leading to improved results in tasks like C++ - to - Python translation and text-to-Python generation.

Figure: Codex by Open AI
Gunasekar et al. introduced Phi1, a smaller model that generates Python functions from doc strings, achieving competitive results with fewer parameters. Additionally, multilingual programming LLMs like Polycoder and CodeGen have been explored, with Codex excelling in Python-specific tasks.
Nijkamp et al. developed the CodeGen family of LLMs and demonstrated their effectiveness on various programming tasks, including multi-step program synthesis.
Furthermore, Li et al. introduced the AlphaCode LLM for solving competitive programming questions. This model, pre-trained on a multilingual dataset and fine-tuned using a curated dataset of competitive programming problems, achieved high performance through large-scale sampling, filtering, and clustering of candidate solutions.
Despite these achievements, a significant challenge in applying LLMs to code generation is the constraint posed by the context window, which limits the ability to incorporate the entire code base and dependencies.
To address this constraint, frameworks like RepoCoder, RLPG, and ViperGPT have been proposed to retrieve relevant information or abstract it into an API definition, thus overcoming the long-range dependency issue.
In the realm of code infilling and generation, LLMs are used to modify or complete existing code snippets based on provided context and instructions. InCoder and SantaCoder are examples of LLMs developed for code infilling and generation tasks.
Additionally, efforts like DIDACT aim to leverage intermediary steps in the software development process to predict code modifications and improve the understanding of the development process.
3. Creative Work
For tasks involving creativity, Large Language Models (LLMs) have predominantly been employed in the generation of stories and scripts.
In the context of generating long-form stories, Mirowski and colleagues propose an innovative approach using a specialized LLM named Dramatron.
With a capacity of 70 billion parameters, this LLM employs techniques like prompting, prompt chaining, and hierarchical generation to create complete scripts and screenplays autonomously. Dramatron's effectiveness was qualitatively assessed through co-writing and interviews with industry experts.
Likewise, Yang and the team introduce the Recursive Reprompting and Revision (Re3) framework that utilizes GPT-3 for generating lengthy stories of over 2,000 words.
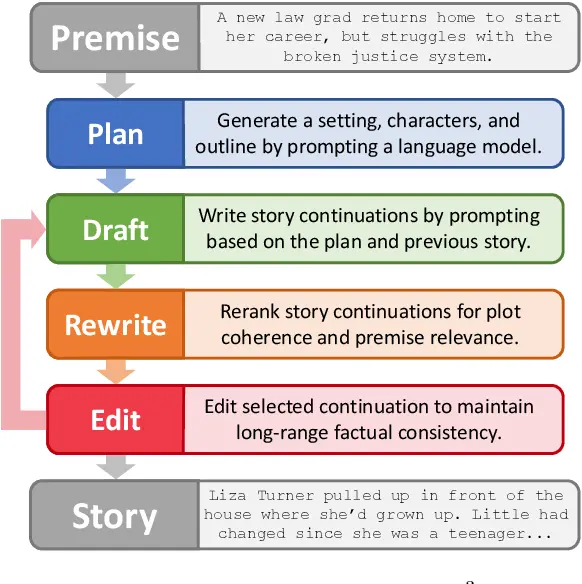
Figure: Generating Stories with Recursive Remprompting and Revision
The Re3 approach employs a zero-shot prompting strategy to create a plan for the story, followed by recursive prompts to generate story continuations. These continuations are evaluated for coherence and relevance using Longformer models in a Rewrite module.
Furthermore, factual inconsistencies are addressed through local edits facilitated by a combination of GPT-3 and BART models in an Edit module. This iterative process enables fully automated story generation.
Another framework by Yang et al. is the Detailed Outline Control (DOC), designed to maintain plot coherence throughout lengthy narratives using GPT-3. Similar to Re3, DOC utilizes high-level planning, drafting, and revision, but incorporates a detailed outliner and controller.
The detailed outliner dissects the high-level outline into subsections and generates its content iteratively using a structured prompting approach. A detailed controller helps ensure the generated content's relevance and coherence.
In both cases of long-form story generation, the inherent limitations of LLMs regarding context windows necessitate breaking down the task into manageable sub-tasks. This modular prompting approach is driven by the current capabilities of LLMs and is particularly useful in co-writing scenarios.
When it comes to short-form creative content generation, Chakrabarty and team propose CoPoet, a collaborative poetry generation tool utilizing fine-tuned T5 and T0 models.
Razumovskaia et al. uses PaLM for cross-lingual short story generation with planned prompts. Wang et al. leverage GPT-4 within the ReelFramer tool to co-create news reels for social media.
Ippolito et al. introduce the Wordcraft creative writing assistant, which incorporates LaMDA for creative writing tasks. Calderwood et al. employ fine-tuned GPT-3 in their Spindle tool for generating choice-based interactive fiction.
For broader creative tasks, Haase and Hanel assess multiple LLMs, including ChatGPT, for idea generation using the Alternative Uses Test. These LLMs perform on par with human participants in generating alternative uses for given items.
In the realm of visual creativity, LLMs enhance user control in image generation. Feng et al. propose LayoutGPT, where an LLM generates CSS Structure layouts based on textual prompts.
These layouts guide image generation models, proving effective in text-to-image generation and indoor scene synthesis.
Lian et al. implement a similar concept, using an LLM to generate natural language layouts to guide a diffusion model in image creation. This modality conversion framework has also been applied in robotics and knowledge work.
In essence, LLMs find diverse applications in creative tasks, contributing to story generation, poetry creation, newsreel co-creation, and idea generation, among others.
These models enhance creativity across both textual and visual domains, driven by their ability to generate and manipulate content based on provided prompts and instructions.
4. Medicine and Healthcare
In the field of medicine, LLMs have found numerous applications, resembling those in the legal domain, including medical question answering, clinical information extraction, indexing, triage, and health record management.
Medical Question Answering and Comprehension
Medical question answering involves generating responses to medical queries, both multiple-choice and free-text.
Singhal et al. devised a specialized approach by employing few-shot, CoT, and self-consistency prompting to adapt the general-purpose PaLM LLM for medical question answering. Their Flan-PaLM model, combining the three prompting strategies, achieved top performance on various medical datasets.
Figure: Medical Question Answering using LLMs
Building on this, they introduced Med-PaLM, integrating clinician input and task-specific human-engineered prompts. A subsequent model, Med-PaLM 2, using PaLM 2 as a base, demonstrated state-of-the-art results on the MultiMedQA benchmark.
Liévin et al. also harnessed zero-shot, few-shot, and CoT prompting to tailor GPT-3.5 for medical question answering, incorporating Wikipedia retrieval for enhancing prompts. Nori et al. evaluated GPT-4 on medical datasets, outperforming GPT-3.5, yet raising concerns about erroneous generations and bias.
Yunxiang et al. fine-tuned a LLaMA LLM, ChatDoctor, for medical question answering, incorporating external knowledge sources.
Similarly, Venigalla et al. trained a new model, PubMedGPT, for medical tasks, while Peng et al. introduced GatorTronGPT. These specialized models exhibit varying performance compared to general-purpose LLMs. Specific tasks, such as triage, genetics, and surgery board exam questions, have also been explored using LLMs.
Medical Information Retrieval
Medical text poses challenges with domain-specific terminology. Agrawal et al. utilized InstructGPT for clinical information extraction, introducing methods for structured output. Rajkomar et al. treated medical acronym disambiguation as a translation task, training a specialized T5 LLM.
Gu et al. employed GPT-3.5 and knowledge distillation to train PubMedBERT for adverse drug event extraction, outperforming general LLMs. The medical domain, like law, grapples with challenges like hallucination, bias, and data obsolescence.
These applications showcase the potential of LLMs in advancing medical question answering, clinical information extraction, and more, while emphasizing the need for cautious application in safety-critical contexts.
5. LLMs in Robotics
In the realm of robotics and embodied agents, the integration of LLMs has introduced advancements in high-level planning and contextual knowledge utilization.
High-Level Task Execution
Ahn et al. incorporated a PaLM-540B LLM into the SayCan architecture to convert text-based instructions into a sequence of executable robot tasks.
The LLM suggests potential next actions by evaluating a set of low-level tasks based on the input. The final low-level task is determined by combining LLM-proposed tasks with affordance functions, which assess the feasibility of task completion given the current context.
Driess et al. extended this approach by combining PaLM-540B with visual input, enhancing task prediction and long-term planning.
Code Generation for Robotics
Vemprala et al. combined ChatGPT with a library of robotic functions for code generation. ChatGPT breaks down high-level natural language instructions into lower-level function calls.
Models like Codex and GPT-3 have been employed for hierarchical code generation, code-based task planning, and maintaining a written state. This approach aids in automating robotic tasks and enhances interaction with humans.
Multimodal Integration
Some studies have integrated LLMs with multimodal inputs. Liu et al. utilized GPT-4 within the REFLECT framework to detect and explain robot failures using multi-modal sensory data converted into text-based summaries.
Huang et al. combined LLMs with text-based environment feedback for robotic task planning. While LLMs offer high-level planning capabilities, their limitations in directly processing image and audio data restrict their applicability.
Simulated Environments
In simulated environments, LLMs have been used for agent training and skill acquisition. Wang et al. employed GPT-4 in the VOYAGER framework for a Minecraft agent.
The agent autonomously explores, acquires new skills, and completes tasks. GPT-4 proposes tasks, generates code to solve them, and verifies task completion. Similar approaches have been applied in Minecraft and VirtualHome environments.
6. Utilizing LLMs for Synthetic Datasets
The remarkable ability of LLMs to engage in in-context learning opens up a realm of possibilities, one of which involves generating synthetic datasets for training smaller, domain-specific models.
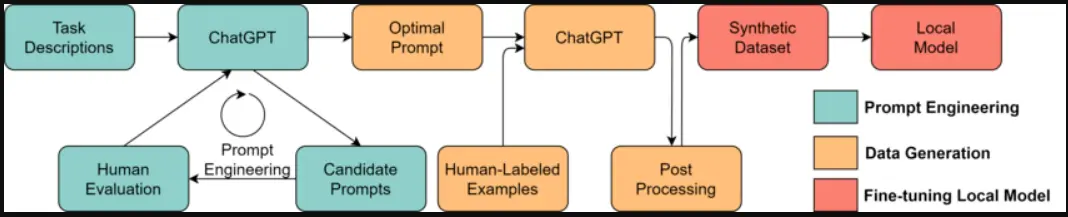
Figure: Workflow for Synthesising Data in LLMs
Labeling and Training Data Generation
Wang et al. propose an innovative approach to dataset labeling using GPT-3, aiming for cost-effective labeling as compared to human annotators. These GPT-3 labels show superior performance in scenarios with limited labeling resources.
Ding et al. present three distinct prompting strategies for training data creation using GPT-3, involving label generation for known examples, generation of examples and labels, and assisted data generation with supplementary Wikidata context. While GPT-3 exhibits promising performance, fine-tuning smaller models through these approaches has shown mixed results.
Synthetic Data Generation with LLMs
Gunasekar et al. leverage GPT-3.5 for synthetic data generation in training a code generation LLM. Synthetic Python textbooks and exercises are crafted to impart reasoning and algorithmic skills. Importantly, this approach emphasizes the introduction of randomness while maintaining data coherence and quality.
Yoo et al. introduce GPT3Mix, a novel method that harnesses GPT-3 to augment datasets for classification tasks. Synthetic examples and pseudo-labels are jointly generated based on real dataset instances and task specifications, facilitating fine-tuning of smaller models like BERT and DistilBERT.
Bonifacio et al. present InPars, a strategy for generating synthetic retrieval instances using LLMs. GPT-3 prompts are used to create relevant questions associated with randomly sampled documents, contributing to training a smaller model for ranking documents in response to questions.
AugGPT, an approach devised by Dai et al., employs ChatGPT (GPT-3.5) to augment base datasets with rephrased synthetic examples. These augmented datasets then aid in fine-tuning specialized BERT models, surpassing conventional augmentation techniques.
Shridhar et al. introduce Decompositional Distillation, which exploits LLM-generated synthetic data to replicate multi-step reasoning capacities. GPT-3 decomposes problems into sub-question and sub-solution pairs, enhancing the training of smaller models to address specific sub-tasks.
Challenges and Consideration
While the use of LLM-generated synthetic data offers cost efficiency, caution must be exercised due to potential pitfalls. The concept of hallucinated distributions highlights the difficulty in verifying whether synthesized data accurately represents real-world distributions.
This concern is particularly significant when both input and target data are generated by LLMs. Incorporating LLMs into the data generation process poses risks of unrepresentative training distributions.
Conclusion
As we delve into the amazing ways Large Language Models (LLMs) are used, it's clear they're more than just tools. They're like engines of change in many different areas. Think about stuff like biology, art, medicine, and robots. LLMs are like super helpful pals that can reshape how things work and make them even better.
In biology, LLMs help us understand proteins, genes, and DNA. They can even help design new drugs and spot diseases. These models are like guides pushing the frontiers of science.
In coding, LLMs are like wizards. They make writing software easier by understanding human language and turning it into code. It's like they speed up how programmers create cool stuff. For creative stuff, LLMs are like creative buddies. They help writers, artists, and poets come up with new ideas and make cool things. It's like having a brainstorming friend right there with you.
In medicine, LLMs are like super-smart doctors. They answer medical questions, find info, and organize medical data. They're super useful, but we need to watch out for problems like biases and safety issues.
In robots, LLMs are like planners. They figure out what robots should do and help write the code to make it happen. This makes robots work smarter and better with people.
LLMs are also great at making pretend data for training other smart programs. But we have to be careful to make sure the data is useful and accurate. While LLMs do amazing things, they're not perfect.
Sometimes they can say things that aren't true or fair. So, we need to be smart when we use them and not just believe everything they say.
In the end, exploring what LLMs can do is like an adventure. They're changing how we do stuff and making the world cooler. But we need to be careful and think about how we use them to make sure we're doing good things. The future with LLMs looks bright, but we need to be responsible and make sure we're doing it right.
Frequently Asked Questions
1. What is a Large Language Model (LLM)?
A Large Language Model (LLM) is a powerful type of machine learning model that can handle various tasks involving human language.
It can do things like generate text, classify text, answer questions in conversations, and translate languages. The "large" in its name refers to the many values it can learn from data, often billions of them, making it incredibly adaptable and smart.
2. How do Large Language Models (LLMs) learn and improve?
LLMs learn by training on massive amounts of data. They use a technique called self-supervised learning, where they predict the next word in a sentence based on the words that come before it.
This helps them understand the context of the language. This process is repeated over and over until the model becomes really good at predicting words and understanding language.
3. What are some practical applications of Large Language Models (LLMs)?
LLMs have revolutionized various fields. In conversation, they power advanced chatbots and virtual assistants. For content creation, LLMs can generate high-quality articles, social media posts, and more. They're also crucial for language translation, making global communication easier.
LLMs can summarize long texts, analyze sentiment in text, and even assist in generating creative work like stories and poetry. In medicine, they answer medical questions, extract information, and manage health records.
Additionally, LLMs have found applications in robotics, aiding in task planning and automation. They're also used to create synthetic datasets for training other specialized models.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
