

Image Segmentation: The Power Behind Self-Driving Car Navigation

Driving a car is often taken for granted. Little do we know that this effortless task is a result of millions of years of evolution. Every time we are driving, our brain is able to analyze, in a matter of milliseconds, what kind of vehicle (car, bus, truck, auto, etc.) is ahead of us and in which direction it is moving. To be able to drive like humans, machines need to be able to do the same.
Autonomous Vehicles are machines capable of navigating the environment without human intervention. Such an interaction with the environment requires a system that provides the vehicle with accurate information about the surroundings.
Hence, understanding the situation and surroundings is a critical component of any self-driving system, also sometimes called environmental perception. It provides crucial information about the driving domain, including but not limited to identifying clear driving areas and surrounding obstacles. Image segmentation is a very important step in this direction.
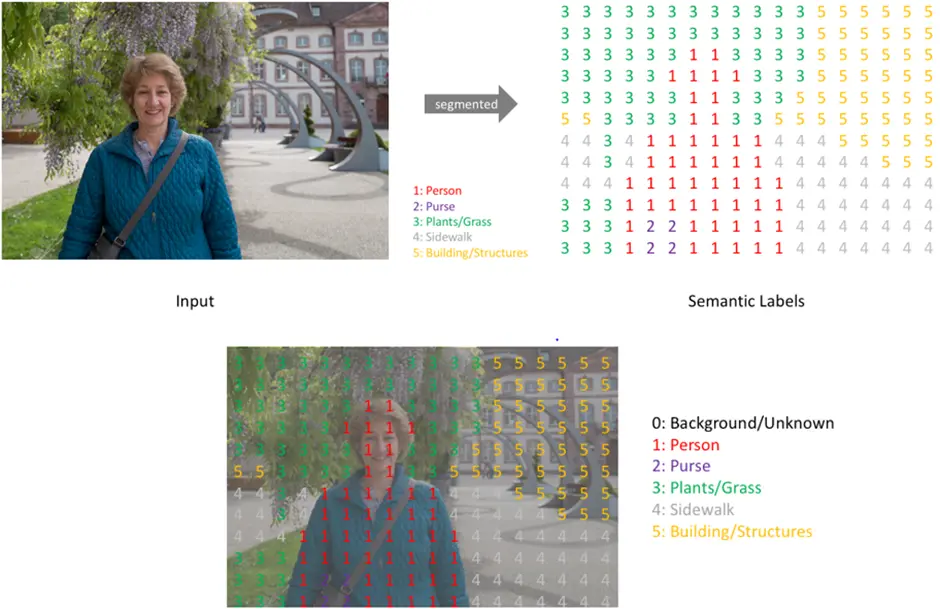
Image segmentation is a widely used perception method for self-driving cars that associates each pixel of an image with a predefined class, like car or pedestrian, as we can also see in the image below.

Table of Contents
Introduction
Being able to move efficiently and safely in vehicles that are driverless has been a hot research topic in recent years, and many companies and research centers are trying to come up with the first completely practical driverless car model. This is a very promising field with a lot of possible benefits such as increased safety, fewer costs, comfortable travel, increased mobility, and reduced environmental footprint.
With the rise and advancements in computer vision, we are able to build computer vision models that can detect objects, determine their shape, predict the direction the objects will go in, and many other things. Image Segmentation is also one of the key concepts within computer vision. It allows computers to color-code objects in an image based on their type by matching each pixel with the object class it belongs to.
Autonomous driving depends on the information received by sensors of the surrounding environment in order to form a complete picture of the driving situation. Because the visual signal is very rich in such information, doing image segmentation correctly is crucial for scene understanding. The more we perform image segmentation with high accuracy and a short time, the more correctly the vehicle understands the surrounding environment and accordingly makes the right decision every moment.
Now, there is a simpler and more popular way to deal with this challenge too, i.e. object detection, where we classify objects into different classes and draw bounding boxes around them, but it does not give an equally detailed, pixel-level overview of the objects and accurate edges & shape. You can see the difference in both with the image below.

What if just detecting objects isn’t enough? What if we want to dive deeper? We want to analyze our image at a much more granular level.
Image segmentation provides insight into the composition of the image in the highest possible detail. It consists of the pixel-label classification of the image. The goal of image segmentation is to assign each pixel in the image a label from a predefined set of categories. Image segmentation can be very useful for navigation scenarios, allowing to the creation of an accurate representation of the environment.
Segmentation of images into regions or objects that are typically found in street scenes, such as cars, pedestrians, or roads allows for a comprehensive understanding of the surrounding which is essential to autonomous navigation.
Let us begin by understanding image segmentation.
What is Image Segmentation?
Image segmentation is the process of partitioning a digital image into multiple image segments, also known as image regions or image objects (sets of pixels). The goal of segmentation is to simplify and/or change the representation of an image into something that is more meaningful and easier to analyze.
Image segmentation is typically used to locate objects and boundaries (lines, curves, etc.) in images. More precisely, image segmentation is the process of assigning a label to every pixel in an image, according to the class it belongs to, such that pixels with the same label (class) share certain characteristics, like the same color. Therefore, image segmentation is sometimes referred to as “pixel-wise classification.” We can see an example of this in the image below.
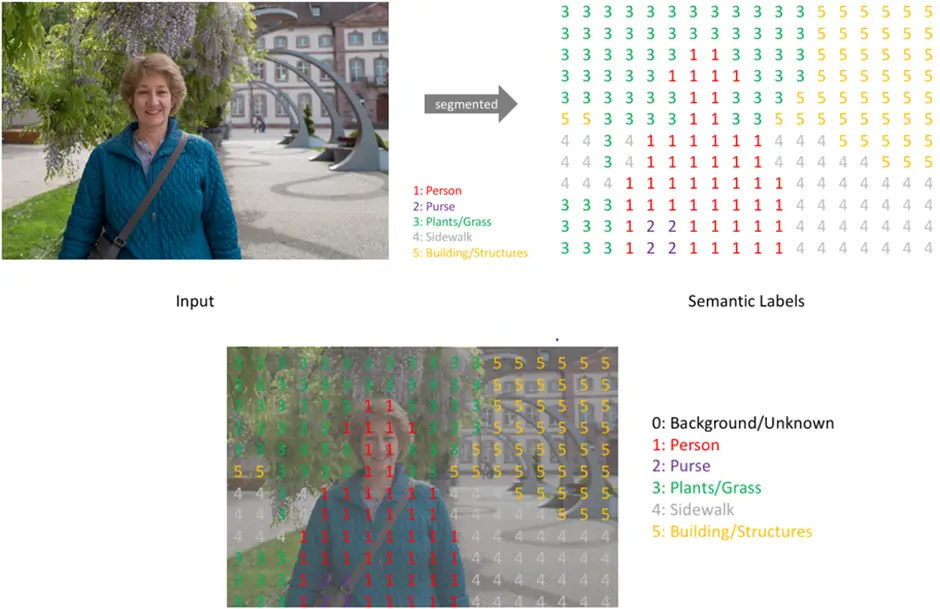
Image segmentation could involve separating foreground from background, or clustering regions of pixels (superpixels) belonging to the same class. The main benefit of image segmentation is situation understanding. It is therefore used in many fields such as autonomous driving, robotics, medical images, satellite images, precision agriculture, and facial images as a first step to achieving visual perception.
For example, a common application of image segmentation in medical imaging is to detect and label pixels in an image or voxels of a 3D volume that represent a tumor in a patient’s brain or other organs. Another example in terms of autonomous vehicles can be identifying and labeling pixels belonging to pedestrians, cars, etc. in a street image.
It can also be provided as input for object detection. Rather than processing the whole image, the detector can be inputted with a region selected by a segmentation algorithm. This will prevent the detector from processing the whole image thereby reducing inference time.
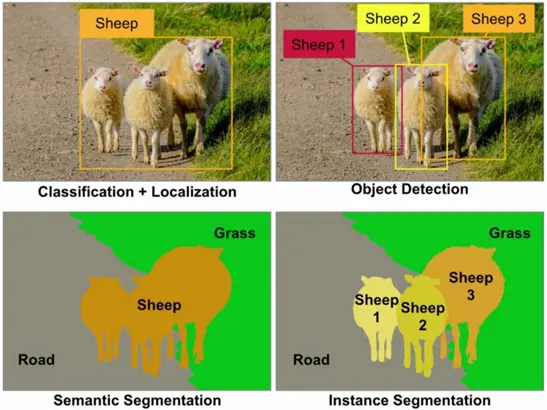
Image Segmentation is generally classified into two types:-
- Semantic Segmentation: Objects shown in an image are grouped based on defined categories. For instance, a street scene would be segmented by “pedestrians,” “bikes,” “vehicles,” “sidewalks,” and so on. But multiple objects belonging to the same category would be treated as a single entity. For example, multiple cars together would belong to the same segment and also have the same label/color.
- Instance Segmentation: A refined version of semantic segmentation. Categories like “vehicles” are split into individual objects. Each object, even of the same class, is treated as a different segment and has a different label/color.
In simple words, semantic segmentation treats multiple objects within a single category as one entity. Instance segmentation, on the other hand, identifies individual objects within these categories, so it is easier to identify individual objects belonging to the same class, like multiple cars in a street scene, with instance segmentation. The image below will help understand this better.
But why do we need Image Segmentation in Self-Driving Cars? Let us try to understand that.
Why is Image Segmentation Required in Self-Driving Cars?
Image segmentation plays a vital role in autonomous driving. Self-driving cars need appropriate pixel knowledge about the surroundings to drive without accidents. Therefore, image segmentation can assist in recognizing lanes, traffic lights, highways, street signs, cross marks, other cars, pedestrians, and other essential information.
Object detection through bounding boxes cannot provide the pixel-perfect recognition that is required. Image Segmentation allows us to perceive environments with more robust knowledge than just detection. For example, when we want to find out the safe path for the vehicle, image segmentation provides accurate information about free space and also where the road and curb are, especially when you don’t have clear lane markings.
With image segmentation, we are not only able to identify several object classes in the image but also to determine the location and shape of the objects very accurately.

A self-driving car needs to react to new events instantly to guarantee the safety of passengers and other traffic participants, which is not possible if the borders of objects are not recognized perfectly down to a pixel resolution. Hence, image segmentation is an important perception manner for self-driving cars and robotics, which classifies each pixel into a predetermined class.
Now let us try to understand how image segmentation is done.
How is Image Segmentation Done?
Segmentation in easy words is assigning labels to pixels. All picture elements or pixels belonging to the same category have a common label assigned to them.
Generally, there are 2 ways to approach the image segmentation problem:
1. Similarity approach:
- This approach is based on detecting similarity between image pixels to form a segment, based on a threshold. ML algorithms like clustering are based on this type of approach to segment an image.
- Threshold-based segmentation is a way to create a binary or multi-color image based on setting a threshold value on the pixel intensity of the original image.
- In this thresholding process, we will consider the intensity histogram of all the pixels in the image. Then we will set a threshold to divide the image into sections. For example, considering image pixels ranging from 0 to 255, we set a threshold of 60. So all the pixels with values less than or equal to 60 will be provided with a value of 0(black) and all the pixels with a value greater than 60 will be provided with a value of 255(white).
- Considering an image with a background and an object, we can divide an image into regions based on the intensity of the object and the background. But this threshold has to be perfectly set to segment an image into an object and a background.
- We can see an example of the same in the image below.

2. Discontinuity approach:
- This approach relies on the discontinuity of pixel intensity values of the image. Techniques like Edge Detection use this type of approach for obtaining intermediate segmentation results which can be later processed to obtain the final segmented image.
- Edge-based segmentation relies on edges found in an image using various edge detection operators. These edges mark image locations of discontinuity in gray levels, color, texture, etc. When we move from one region to another, the gray level may change. So if we can find that discontinuity, we can find that edge.
- A variety of edge detection operators are available but the resulting image is an intermediate segmentation result and should not be confused with the final segmented image. We have to perform further processing on the image to segment it.
- Additional steps include combining edges segments obtained into one segment in order to reduce the number of segments rather than chunks of small borders which might hinder the process of region filling. This is done to obtain a seamless border of the object.
- An example of edge detection can be seen in the image below.

With the success of deep learning methods like CNN, nowadays, CNN-based are very popular for tasks like image segmentation. Image Segmentation often requires the extraction of features and representations, which can derive a meaningful correlation of the input image, essentially removing the noise. Hence, several such methods like the U-Net, DeepLab, and PSPNet have been proposed for the task.
To achieve safe driving, tasks like semantic segmentation need to be done in real-time in autonomous vehicles. CNN-based methods are very fast and help achieve this goal.
However, it is not as easy as it sounds. Even after decades of research, the perception of autonomous vehicles is not even close to humans. In the next section, we’ll discuss a few challenges that arise while trying to achieve image segmentation.
Challenges
Semantic segmentation is challenging due to the complicated relationship between pixels in each image frame and also between successive frames. Even with the fast development of new technologies such as deep learning which have made the mission of semantic segmentation more efficient, doing accurate semantic segmentation in real-time is still a hot topic in current research.
The task is also difficult due to the complexity of the scene, complicated object boundaries, small objects, and the large size of the label space. Especially objects like pedestrians and vegetation are very difficult to segment accurately because of their complex shapes, complex motion, different sizes and the different types of clothing pedestrians can be wearing.
Furthermore, segmenting small, and possibly occluded objects is a challenging task. Image segmentation works well for instances covering large image areas but is still challenging for instances covering smaller regions which provide less information about the label and require context reasoning. which might benefit from accurate depth estimation.
The instance segmentation task is much harder than the semantic segmentation task. Each instance needs to be carefully labeled separately whereas in semantic segmentation groups of one semantic class can be labeled together when they occur next to each other.
In addition, the number and size of instances vary greatly between different images. In the autonomous driving context, often a wide view is present. Therefore, a large number of instances appear rather small in the image, making them challenging to detect.
In contrast to bounding box detection, the exact shape of each object instance needs to be inferred in this task. Thus, making it very difficult.
Also, lots of data is required to train deep learning models, but only a few datasets for image segmentation exist.
Our SaaS platform makes image segmentation annotation fast and accurate. Try it now.
Summary
Image segmentation is a very important process for the perception of autonomous vehicles. It plays a major role in the road scene understanding of the self-driving car.
It is a technique that enables us to differentiate different objects in an image.
It can be considered an image classification task at a pixel level.
The deep learning methods for image segmentation have fastened the development of algorithms that can be used in real-world scenarios with promising results.
These algorithms primarily use convolutional neural networks and their modified variants to get as accurate results as possible.
If technology continues to grow at this speed, we might see fully autonomous vehicles sooner than expected.
Did you like this article?
Follow us on Linkedin to get latest updates on our blogs, articles, events and more

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
