

How to Efficiently Organize Data Labeling for Machine Learning: A Comprehensive Guide


Even if labeling doesn't involve firing a rocket into outer space, it's nevertheless a serious endeavor. In supervised learning, labeling is a crucial step in the data pre-processing process.
This model training style uses historical data with predetermined goal attributes (values). Only if the target properties were mapped by a human, can an algorithm find them.
Labelers must pay close attention because every error or inaccuracy degrades the quality of a dataset and a predictive model's overall performance.
How can one obtain a well-labeled dataset without going grey? Determining who will be in charge of labeling, how long it will take, and which tools to employ are the primary challenges.
Here we have discussed how you can organize Data Labeling for Machine Learning: Approaches and which is the best tool.
Table of Contents
- Importance of Data Labeling
- How Can You Perform Data Labeling Efficiently?
- Best Practices for Data Labeling
- Data Labeling Approaches
- What to Look for in the Data Labeling Tool for Best Performance?
- Popular Tools for Data Labeling: Labellerr
- FAQs
Importance of Data Labeling

Data labeling in machine learning is the procedure of classifying unlabeled data (such as images, text files, videos, etc.) and putting one or more insightful labels to give the data perspective so that a machine-learning model may learn from it.
For instance, if an image shows a bird or an automobile, which words were spoken in a voice recording, or whether a tumor is visible on an x-ray. For several use cases, such as natural language processing (NLP), computer vision, as well as speech recognition, data labeling is necessary.
Data labeling is an important step in machine learning that includes annotating data to teach algorithms to see patterns and make predictions. Here are some reasons why data labeling is crucial:
Accurate Predictions: Accurate data labeling promotes improved quality control in machine learning algorithms, enabling the model to be trained and produce the most accurate predictions.
Reliable Models: The performance of your model is directly related to the correctness of your data. Your ML/AI model won't be accurate without accurate data labeling, and the entire procedure will be time-consuming.
Discriminative Machine Learning Models: Discriminative machine learning models categorize a data sample into one or more categories. To create these models, labeled data is required. A machine learning model can predict the label of a fresh, unknown sample of data once it has been trained using data and the associated labels.
Training Supervised Machine Learning Models: Data labeling aids in the training of supervised machine learning models, which study data and the labels that correlate to it.
Highlights Data Features: Labelled data emphasizes data aspects, or qualities, traits, or categories, that may be examined for trends that aid in the prediction of the goal
How can you perform data labeling efficiently?
Building effective machine learning algorithms requires a lot of good training data. However, it can be expensive, complex, and time-consuming to produce the data for training required to develop these models.
Most models used today require data to be manually classified so that the model knows how to draw appropriate conclusions. This problem might be solved by proactively organizing data using a machine-learning model, which would make labeling more effective.
In this process, a subset of your real data which has been labeled by humans is used to train a machine learning algorithm for categorizing data. When the labeling model is certain of its conclusions depending on what others have discovered thus far, it will automatically apply labels to the raw data.
The labeling model will forward the data to the humans for labeling in cases when it has less confidence in its results. The labeling model is then given the human-generated tags once more so that it can learn from them and become more adept at automatically identifying the following batch of raw data.
Best practices for data labeling
A development hurdle that becomes more critical when complicated models must be created is acquiring high-quality labeled data. However, there are numerous ways to organize data labeling for machine learning and enhance the efficiency and precision of the data labeling process.
- Clear labeling guidelines: To obtain the desired precision of findings, you should interact with the labelers as well as provide them with detailed labeling instructions.
- Consensus: To guarantee high label quality, there must be a specific rate of agreement between human and machine reviewers. This entails distributing each dataset to various labelers for review before combining the annotations.
- Label verification: It's crucial to audit the labels, confirm their accuracy, and make any necessary corrections.
- Active learning: The use of automatic data labeling is advised when working with huge datasets. Active learning, a machine learning technique, can be used to accomplish this by automatically identifying data that requires human labeling.
- Transfer of knowledge: Utilizing previously completed labeling tasks to generate hierarchical labels is another method to increase the effectiveness of data labeling. In essence, you feed the output of one trained model into another.
You can use these procedures to optimize your data labeling operations regardless of your strategy.
Selecting the appropriate approach is also quite a task. Here you can analyze the best approach for data labeling for your project.
Data labeling approaches
There are numerous approaches to accomplishing data labeling work. A company's ability to dedicate the necessary time and money for a project relies on the difficulty of the issue and training dataset, the size of the data science team, and the choice of approach.
1. In-house
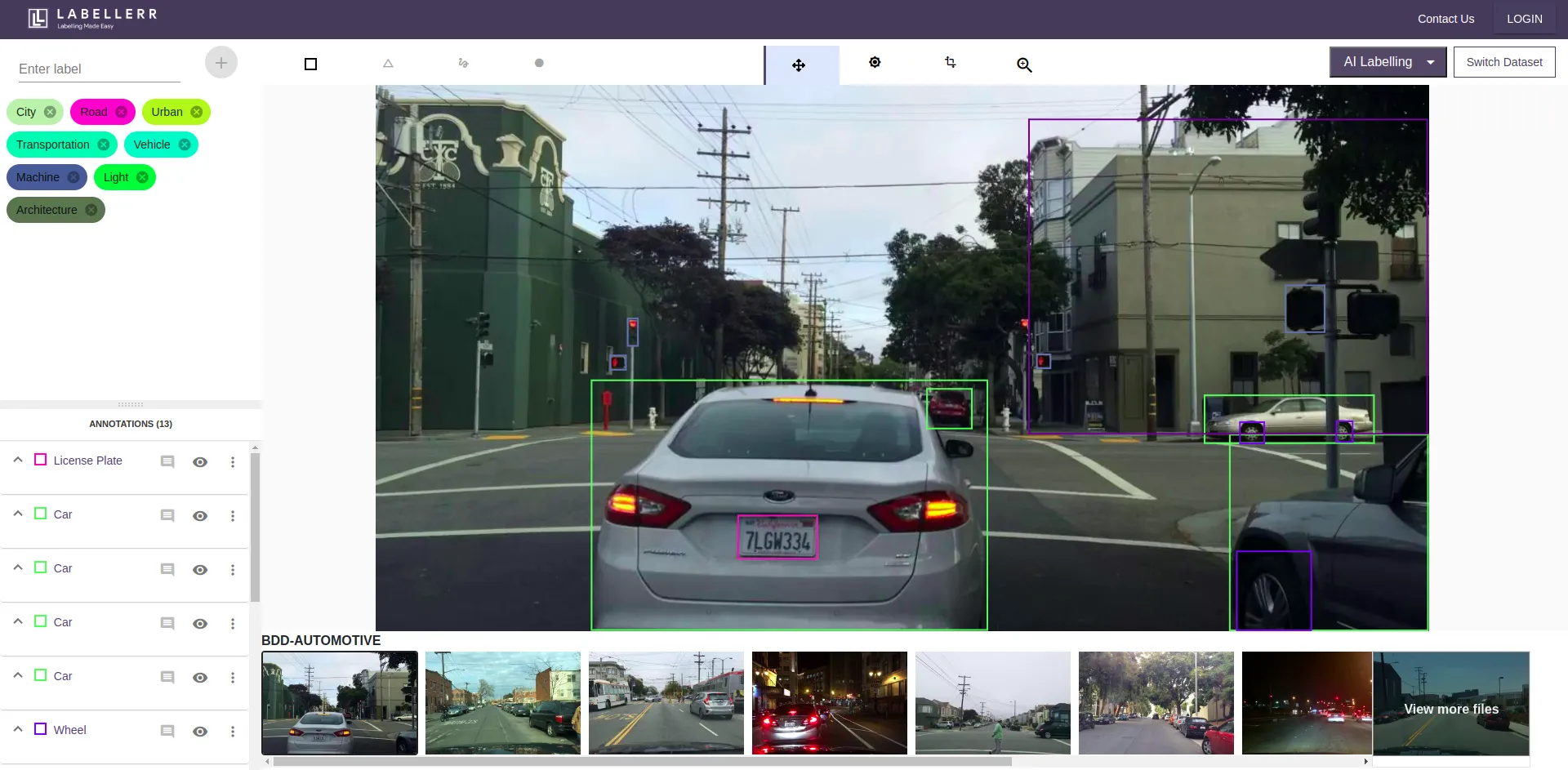
Within an organization, specialists perform in-house data labeling work, which guarantees the best possible level of labeling.
When you have sufficient time, human, and financial resources, it's the best option because it offers the highest level of labeling accuracy. On the other hand, it moves slowly.
For sectors like finance or healthcare, high-quality labeling is essential, and it frequently necessitates meetings with specialists in related professions.
Advantages
Good results can be predicted and controlled. You're not getting a pig in a poke if you depend on the community. Because they will be dealing with a labeled dataset, data scientists and other inside experts are motivated to perform well. To ensure that your team adheres to a project's deadline, you can also monitor its performance.
Disadvantages
It takes a while. The labeling process requires more time the higher the labeling quality. To categorize data correctly, the data experts will require more time, and time is typically a scarce resource.
2. Outsourcing

Outsource data to fasten your data annotation processes
For building a team to manage a project beyond a predetermined time frame, outsourcing is a smart choice. You can direct candidates to your project by promoting it on job boards or your business's social media pages.
Following that, the testing and interviewing procedure will guarantee that only people with the required skill set join your labeling team.
This is a fantastic approach to assembling a temporary workforce, but it also necessitates some planning and coordination because your new employees might need the training to be proficient at their new roles and carry them out according to your specifications.
Advantages
You are the one who hires. Tests can be used to determine whether applicants have the necessary abilities for the position. Since employing a small or moderate staff is required for outsourcing, you will have the chance to oversee their work.
Disadvantages
You must create a workflow. A task template needs to be made, and it needs to be user-friendly. For example, you might use a tool, which offers an interface for labeling tasks, if you have any visual data.
When several labels are necessary, this service enables the construction of tasks. To guarantee data security within a local network, developers advise utilizing a tool.
Provide an outsourced professional with a labeling tool of your choice if you don't want to design your own task interface.
Writing thorough and understandable directions is another duty of yours if you want outsourced workers to follow them and annotate appropriately. In addition, you'll need more time to complete and review the finished jobs.
3. Crowdsourcing
The method of gathering annotated data with the aid of a sizable number of independent contractors enrolled at the crowdsourcing platform is known as crowdsourcing.
The datasets that have been annotated are primarily made up of unimportant information like pictures of flora, animals, and the surroundings. Therefore, platforms with a large number of enrolled data annotators are frequently used to crowdsource the work of annotating a basic dataset.
Advantages
Provide rapid outcomes- For tasks requiring the use of robust labeling technologies and big, simple datasets with short deadlines, crowdsourcing is a viable choice.
For example, categorizing photographs of vehicles for computer vision tasks won't take long and can be completed by personnel with common knowledge, not specialized knowledge. Efficiency can also be gained by breaking down projects into smaller jobs that independent contractors can complete at once.
Affordability-You won't spend a fortune assigning labeling assignments on these sites. Employers have a variety of options thanks to services like Amazon Mechanical Turk, which permits setting up rewards for each assignment.
For instance, you could identify 2,000 photographs for $100 by offering a $0.05 bonus for every HIT and just requiring one submission per item. Given a 20% price for HITs with a maximum of nine assignments, the total cost for a small dataset would be $120.
Disadvantages
Crowdsourcing has various drawbacks, the biggest one being the possibility of receiving a dataset of poor quality, even while it might help you save time and money by asking others to label the data.
Inconsistent labeling of data of poor quality- People who depend on the number of tasks they do each day for their daily pay may disregard task recommendations in an effort to finish as much work as feasible. A linguistic barrier or a division of labor can occasionally cause errors in annotations.
Platforms for crowdsourcing employ quality control procedures to address this issue and ensure that their employees will deliver the highest quality work. Online marketplaces do this by verifying skills through training and testing, keeping track of reputation ratings, offering statistics, peer evaluations, and audits, and in advance outlining the desired results.
Additionally, clients can ask several individuals to work on a particular project and then review it before paying.
As an employer, it is your responsibility to ensure everything is in order. The platform reps advise using brief queries and bullet points, showing samples of well- and poorly-done activities, and providing clear and concise work instructions. You can include examples for each of the criteria you establish if your labeling activity involves drawing boundary boxes.
4. Synthetic data generation

The synthesis or generation of fresh data with the properties required for your project is known as synthetic labeling. Generative adversarial networks are one technique for synthetic labeling (GANs).
A GAN integrates various neural networks (a discriminator and a generator) that compete to discriminate between real and false data and produce fake data, respectively.
As a result, the new facts are very realistic. You can generate brand-new data from already existing datasets using GANs and other synthetic labeling techniques. They are hence good at creating high-quality data and are time-effective. Synthetic labeling techniques, however, currently demand a lot of computational power, which can render them quite expensive.
Advantages
Cost and time savings-This method speeds up and reduces the cost of labeling. It is simple to create unique synthetic data that is tailored for a particular purpose and may be altered to enhance both model training and the model itself.
Utilizing non-sensitive data-To use such data, data scientists are not required to obtain authorization.
Disadvantages
The demand for powerful computing. For graphics and additional model training, this method needs powerful computing. Renting cloud servers from platforms like Amazon Web Services (AWS), Google's Cloud Platform, Microsoft Azure, IBM Cloud, Oracle, or others is one of the choices. On decentralized platforms like SONM, you can take a different route and obtain more computational resources.
data integrity problems. Real historical data could not exactly resemble synthetic data. A model developed using these data may therefore need to be improved further by being trained using actual data as it becomes available.
What to look for in the data labeling tool for best performance?
Let's check out things to look for in the data labeling tool for best performance:
1. Be sure about data quality
The success of your artificial intelligence and machine learning models depends on the quality of the data. Additionally, tools for data annotation can help with validation and quality control (QC). You must ensure that the tool you are looking for includes quality control as a compulsory part of the data annotation procedure.
A quality dashboard will be a feature of many technologies, helping managers to identify and monitor quality issues. Additionally, many annotation software will have a function that returns QC responsibilities to the primary annotation team or even a separate QC team.
2. Pricing of the tool
The pricing of a tool is always a concern. It is seen that most programmers working in small/medium-sized teams look for free tools but free tools can never provide a list of benefits and your work will get stuck.
For a fair comparison, one should consider if paid options are worthwhile. You should examine the circumstances in which paying for a solution makes sense and adds value.
3. Check whether it provides the best annotators
Although data labeling is a crucial step in the process of creating AI/ML models, at its core, it is a human activity because decisions are being made behind each row of labeled data. This raises the question: What kind of people do you want to classify your data?
4. Look out for Speed and Performance
The data labeling platform you choose needs to be able to meet your speed and throughput demands. A wide range of images is now available to deep-learning programmers. The manual nature of annotations means that photo tagging may take a lot of time and effort. So, it is important to find a platform that can be efficient and speed up the project.
5. Ease of Use
It's essential to understand that you can incorporate your data labeling platform painlessly and without obstruction into your bigger production pipeline because it will become a crucial component of it.
Consider the following inquiries regarding each data labeling platform to understand its ease of use:
Is communication possible with my labelers? Can you put labelers to the test and only utilize the top ones for my task?
To ensure that everyone understands your objectives and specifications, bring these responses to your data labeling platform.
Popular Tools for Data Labeling: Labellerr
Labellerr is a data automation tool that helps data science teams to simplify the manual mechanisms involved in the AI-ML product lifecycle. We are highly skilled at providing training data for a variety of use cases with various domain authorities.
Labellerr provides a wholly on-premise solution for businesses that operate in settings without an internet connection. The software can be installed on your own hardware or in your cloud infrastructure.
You can simply optimize your process, reduce the extra cost associated with data labeling, organize data labeling for machine learning, and automate your processes with our tool. What else? There’s much more that you can get.
1. Get high data quality assurance
- Get privacy and data protection best practices with enhanced authentication
- We have Identity and access management (IAM) services from unaffiliated cloud providers
- We do not keep the client's original data within its own storage while imposing a policy for deleting sensitive metadata.
- Our tool supports PII that can be used to facilitate pseudonymization, redaction, and masking.
2. Get the best pricing

- Avail of the pricing structures that best meet your needs.
- There is no need for an extended contract.
- Use freely for modest proof-of-concept or sizable, long-term projects.
3. Enhance your productivity with our highly trained annotators
- Labellerr has access to the most skilled annotation crew in the world with years of experience
- We have the presence of subject matter experts from diverse businesses
- We offer the best results with less prejudice because of our internationally representative workforce across all continents
- We have More than 5000 skilled full-time annotators working in a secure facility under the supervision
4. Get Speed and performance with Labellerr
- Using models of machine learning to power auto-labeling will improve data annotation.
- We offer Quick implementation from the establishment of guidelines to annotation
- We also provide Pre-trained models and proprietary datasets to expedite project start
5. Get the ease of use with Labellerr
- We allow all types of data support for computer vision types of AI and annotation
- We are a one-stop shop for all of your tools and the person in the loop needs
- You will get a highly user-friendly UI with work templates for annotations and round-the-clock assistance
- We have Strong API connections to your current MLOPs infrastructure
If you want to organize your data labeling task more effectively, then reach out to us at Labellerr!
FAQs
- What does machine learning data labeling entail?
The practice of annotating or categorizing data to denote particular traits or categories is known as data labeling. Offering labeled examples for learning and inference, aids in the training of machine learning models.
2. Why is data labeling important for machine learning?
For efficient and successful model training, organizing data labels is essential. Clear and consistent annotations are ensured by well-organized data labels, allowing for accurate model predictions and minimizing any biases.
3. What methods exist for organizing data labels?
A number of strategies exist for organizing data labels, including crowdsourcing, active learning, semi-supervised learning, and human labeling. Depending on the particular project needs, each strategy offers advantages and things to keep in mind.
4. What is manual labeling?
Manual labeling means manually evaluating and annotating the data by human annotators. Although it guarantees excellent accuracy, it can be time- and money-consuming for big datasets.
5. What does active learning mean in data labeling?
A mechanism known as active learning chooses the most instructive data samples for human annotators to label. Focusing on the data that is most useful for model training seeks to decrease labeling effort.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
