

How to develop AI and machine learning products with ease


Working on developing new AI and Machine learning products? Developing a product that is based on AI and machine learning is quite a task. If you think that just coding is enough for developing an AI and Machine Learning product, then you are wrong. You need to follow various other steps in order to develop a product. In this blog, we are going to discuss some of the ways by which you can develop Ai and Machine Learning products.
AI and Machine learning products must be built using systems that can learn and adapt things like a human does. Aside from cognitive models of humans, artificial intelligence will also require the capacity to learn from the past and interact with the real environment (otherwise known as robotics). It takes a lot of research and resources to develop a system that can think like a human in order to generate this kind of AI and Machine learning products.
Table of Contents
- Problem Detection
- Data Preparation
- Selecting an Algorithm
- Preparing the Algorithms
- Evaluate Your Model
The following are the steps for creating an AI and Machine learning product:
Problem detection
Finding the issue at hand is the first step in developing a reliable AI system. Ask questions like, "What is the desired outcome?" and "What is the issue that this attempt is trying to address?" The fact that AI and Machine Learning are not a cure-all must also be borne in mind. It is only a means by which the issues might be resolved. A specific AI problem may be solved using a variety of methods.
Data Preparation
One might believe that the several lines of code that correspond to the employed algorithm form the basis of any reliable AI and Machine learning system. It's not, in fact. Any AI toolset must include data as a core component. Before writing a single byte of code, the data scientist typically spends more than 80% of their time organizing, cleaning, and preparing the data for usage.
Therefore, the data must be reviewed for consistency before the model is run. Labels must also be added, and a sequential order must be established, among other things. It is common knowledge that the more inputs one sends to the dataset, the more probable it is to find a solution to the current issue.
There are primarily two types of data: structured data and unstructured data.
- Data that has a set format in order to maintain consistency is referred to as structured data.
- Unstructured data is any type of data that does not have a set format, such as photos, audio files, and other types of files.
Selecting an Algorithm
The hardest or finest phase of creating an AI system is now upon us. Without becoming too technical, there are still very few essential concepts that must be understood in order to construct an AI system. The algorithm's form can alter depending on the kind of learning that is occurring. There are primarily two approaches to learning, as follows:
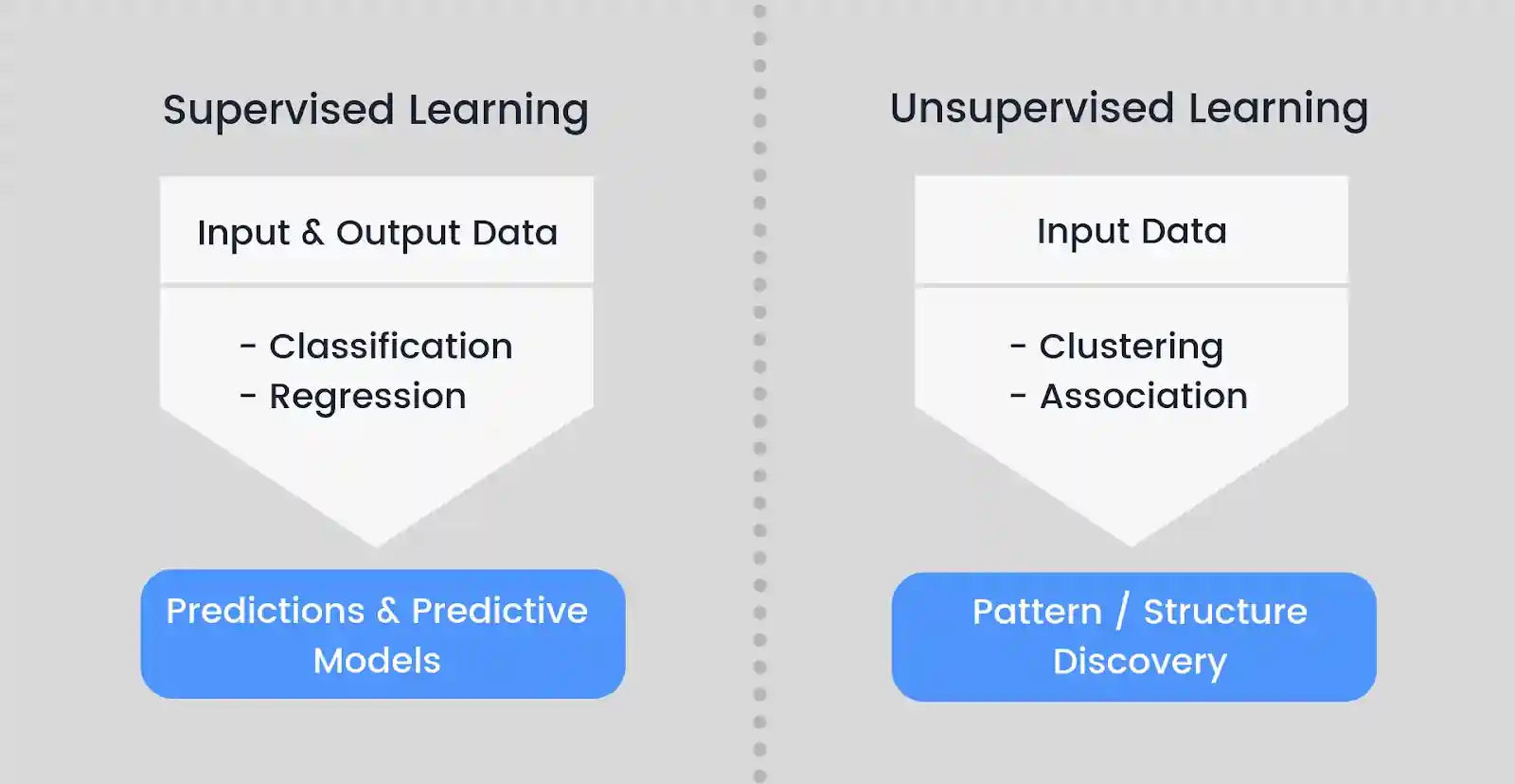
- Supervised Learning: As the name implies, supervised learning entails giving the machine a dataset on which to train so that it can produce the necessary outcomes on the test dataset. SVM (Support Vector Machine), Naive Bayes Classification, Random Forest generation, Logistic Regression, and more supervised learning techniques are now accessible.
Knowing if our ultimate objective was to obtain insight on a specific loan would be a great method to comprehend supervised learning of classification, especially if the knowledge we want is the likelihood for the loan to default.
On the other hand, if our objective was to obtain a value, one will utilize the regression form of supervised learning. In this instance, the value might be the sum that would have been forfeited if the loan had defaulted.
- Unsupervised learning: The sorts of algorithms used in this type of learning make it different from supervised learning. These subcategories can be divided into clustering where the algorithm strives to categorize things in an association where it enjoys discovering connections between the objects and dimensionality reduction where it reduces the number of variables to lessen noise.
Preparing the algorithms
The chosen method must be trained as a necessary step to guarantee the model's accuracy. Therefore, the next natural step in developing the AI system is algorithm training after choosing an algorithm. The chosen framework must be kept at a certain level of accuracy even though there are no universal criteria or standards for model fidelity.
The key to creating a functioning AI system is training and retraining since it makes sense that the algorithm might need to be retrained if the target accuracy is not achieved.
Evaluate your Model
Now, evaluate the quality of your model with fresh data. Add some new users, for instance, to generate and handle data. The more fresh data you test against, the better. The original data is useful, but more substantial collections of high-quality data are usually preferable. But, Extrapolating test data is not a smart idea in this situation; your model should perform well with actual users, not on created or projected data.
Before moving on to the training the algorithm stage, the stage of data collection, training data comes into play. This stage is quite hectic and time-consuming but you can reduce your time, and enhance your efficiency by using a data training platform.
We are a training data platform that helps data science teams to simplify the manual mechanisms involved in the AI and Machine learning product lifecycle.
A variety of data graphs are available on Labellerr's platform for data analysis. The chart displays outliers in the event that any labels are incorrect or to distinguish between advertisements.
We accurately extract the most relevant information possible from data—more than 95% of the time—and present the data in an organized style. having the ability to validate organized data by looking over screens.
If you find the blog interesting, then do share it with your team and keep visiting!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
