

Fine-Tuning Tutorial: Falcon-7b LLM To A General Purpose Chatbot
Learn to fine-tune the Falcon-7b LLM into a versatile chatbot using techniques like PEFT and QLoRA. This guide walks through adapting large models for specific tasks, enhancing chatbot performance while optimizing resource use with tools like Hugging Face.


Salesforce recently found that 77% of customers believe chatbots will revolutionize their expectations of companies in the next five years.
Imagine having a chatbot that not only meets but exceeds those rising expectations by understanding and responding like a real person.
While large language models like Falcon-7b are already good at grasping human language from vast text data, they can often miss the mark when it comes to specific needs.
If you’ve ever struggled with chatbots that seem out of touch or too robotic, you’re not alone.
Fine-tuning Falcon-7b could be the game-changer you need, making it a more intuitive and effective tool tailored precisely to your needs.
In this article, we will delve into the necessity of fine-tuning, explore the array of LLMs available, and provide an illustrative example where we try to fine-tune Falcon-7b LLM to act as a general-purpose chatbot.
Table of Contents
- Understanding Fine-Tuning
- Falcon -7b
- Fine-Tuning with PEFT (Parameter Efficient Fine Tuning)
- Hands-on With Code
- Conclusion
- Frequently Asked Questions
Understanding Fine-Tuning
While a pre-trained LLM possesses general knowledge, it might need help with specific domain questions and comprehend medical terminology and abbreviations.
This is where fine-tuning comes into play.
But what exactly is fine-tuning?
In simple terms, fine-tuning is like transferring knowledge to a model. These expansive language models undergo training on a smaller, targeted data set using substantial computational resources and boast millions of parameters.
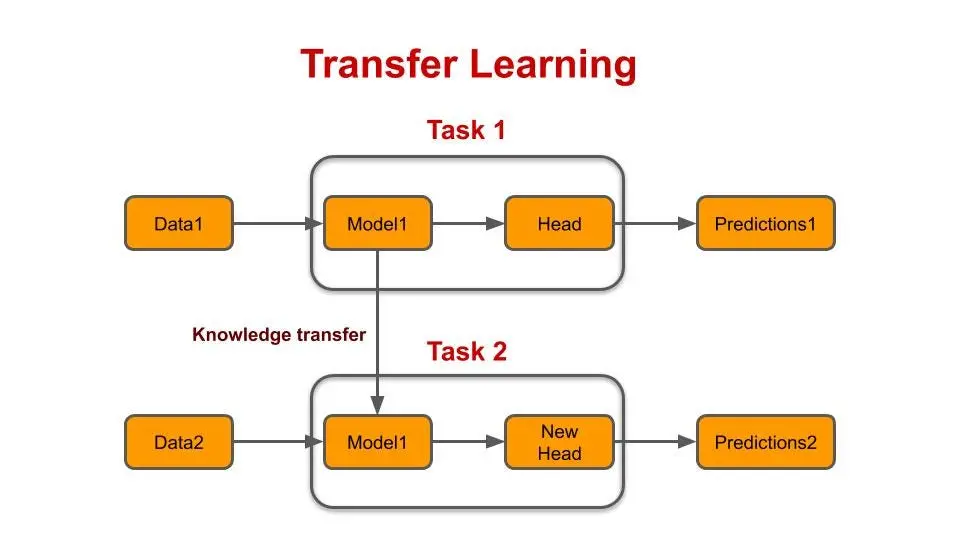
Figure: Transfer Learning
The linguistic patterns and representations acquired by LLM during its initial training are transferred to your current task. In technical terms, you begin with a model that's initialized using pre-trained weights.
Next, it undergoes training using data relevant to your specific task, refining the parameters to be more aligned with the task's requirements.
You also have the flexibility to adjust the model's architecture and modify its layers to suit your specific needs.
Falcon -7b
Falcon LLM stands as a foundational large language model with a staggering 40 billion parameters, developed through training on an extensive corpus of one trillion tokens.
The Technology Innovation Institute (TII) has recently introduced Falcon LLM, showcasing this impressive 40B model.
Notably, Falcon LLM's training process was conducted with remarkable efficiency, utilizing only 75% of the training compute employed by GPT-3, 40% of Chinchilla's, and 80% of PaLM-62B's.
Falcon firmly secures the top position when assessed on the OpenLLM Leaderboard within the HuggingFace platform, effectively surpassing META's LLaMA-65B model.
A decoder-only autoregressive model with 40 billion parameters, Falcon was trained on a massive dataset of 1 trillion tokens. This intricate training process spanned two months and involved the use of 384 GPUs hosted on AWS.
To create its pre-training dataset, Falcon gathered a wide range of text data from public web crawls.
Through rigorous filtration procedures that removed machine-generated content and adult material, the resulting pretraining dataset emerged from dumps provided by CommonCrawl. This meticulous curation yielded a dataset of nearly five trillion tokens.
Fine-Tuning with PEFT (Parameter Efficient Fine Tuning)
The process of training models with a size exceeding 10 billion parameters can present significant technical and computational challenges.
This section focuses on the tools available within the Hugging Face ecosystem to efficiently train these extremely large models using basic hardware.
It also demonstrates the fine-tuning process of Falcon-7b on a single NVIDIA T4 (16GB) within Google Colab.
The approach involves training Falcon using the Guanaco dataset, which is a high-quality subset extracted from the Open Assistant dataset. This subset comprises approximately 10,000 dialogues.
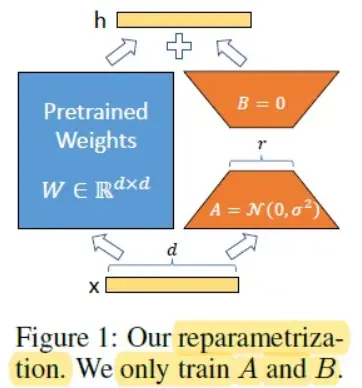
Figure: Parameter Efficient Fine Tuning
Leveraging the PEFT library, the fine-tuning process employs the QLoRA approach, which involves fine-tuning adapters placed on top of the frozen 4-bit model. You can find more details about integrating 4-bit quantized models in the related blog post.
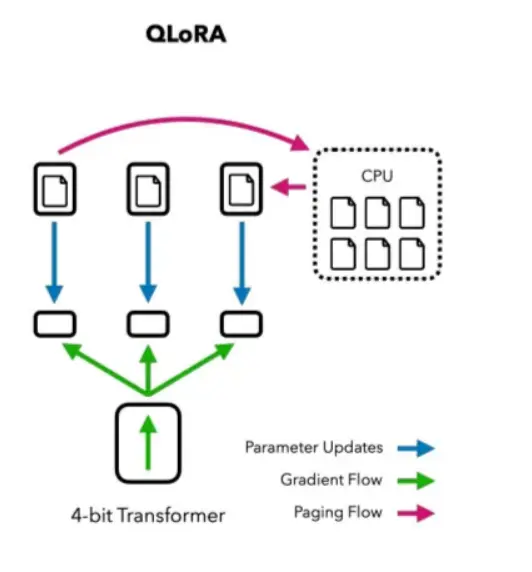
Figure: Fine-Tuning with QLora
Utilizing Low-Rank Adapters (LoRA) for fine-tuning allows only a small portion of the model to be trainable. This substantially reduces the number of learned parameters and the size of the final trained model artifact.
For instance, the saved model occupies a mere 65MB for the 7B parameters model, whereas the original model is around 15GB in half precision.
To explain further, the process involves choosing specific modules for adaptation, typically the query and key layers of the attention mechanism. Small, trainable linear layers are then added close to these modules.
The hidden states produced by these adapters are combined with the original states to derive the ultimate hidden state.
After the training is completed, there is no necessity to save the entire model, as the base model remains frozen.
Additionally, you can store the model in any preferred data type (such as int8, fp4, or fp16), as long as the output hidden states from these modules match the data type used by the adapters.
This holds true for bitsandbytes modules, specifically, Linear8bitLt and Linear4bit, which generate hidden states with the same data type as the original unquantized module.
Hands-on With Code
In this section, we try to fine-tune a Falcon-7 b foundational model using the Parameters efficient fine-tuning approach.
Prerequisite
To understand the below tutorial, one should be familiar with the following:
- Python: Language we use for hands-on.
- Large Language Models: Foundational models train on a large corpus of data.
- Pytorch: Python framework used for working with Machine-learning/Deep learning projects.
Dataset
We're going to make use of the PEFT library from Hugging Face's collection and also utilize QLoRA to make the process of fine-tuning more memory-friendly.
We'll use the Guanaco dataset, a refined part of the OpenAssistant dataset designed specifically to train versatile chatbots. The dataset contains various questions that require generative outputs.
The data is like a question along with its answer. Further, its multi-lingual, i.e., we have questions in English and in Spanish. The dataset contains about 9.85K training instances along with 518 test instances.
Setup
Execute the code cells provided below to establish and deploy the necessary libraries.
Our experimentation necessitates the utilization of accelerate, peft, transformers, datasets, and TRL, which will allow us to harness the capabilities of the newly introduced SFTTrainer.
We'll incorporate the bits and bytes module to quantify the base model into 4 bits. Additionally, the installation of Einops is imperative, given its role in loading Falcon models.
Tutorial
We begin by installing all the required dependencies.
pip install -q -U trl transformers accelerate git+https://github.com/huggingface/peft.git
!pip install -q datasets bitsandbytes einops wandbIn our tutorial, we will use the Guanaco dataset, which constitutes a refined segment of the OpenAssistant dataset designed specifically for the training of versatile chatbots. You can access the dataset through this link.
# Import the necessary library for loading datasets
from datasets import load_dataset
# Specify the name of the dataset
dataset_name = "timdettmers/openassistant-guanaco"
# Load the dataset from the specified name and select the "train" split
dataset = load_dataset(dataset_name, split="train")Next, we load our model. We will be loading the Falcon 7B model, applying 4bit quantization to it, and then adding LoRA adapters to the model.
# Importing the required libraries
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# Defining the name of the Falcon model
model_name = "ybelkada/falcon-7b-sharded-bf16"
# Configuring the BitsAndBytes quantization
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
# Loading the Falcon model with quantization configuration
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
trust_remote_code=True
)
# Disabling cache usage in the model configuration
model.config.use_cache = FalseNext, we load the Tokenizer.
# Load the tokenizer for the Falcon 7B model with remote code trust
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# Set the padding token to be the same as the end-of-sequence token
tokenizer.pad_token = tokenizer.eos_tokenNext, we will import the configuration file to construct the LoRA model. It's crucial to incorporate all linear layers within the transformer block for optimal results.
For this reason, we will include the dense, dense_h_to_4_h, and dense_4h_to_h layers as target modules alongside the mixed query key value layer. This comprehensive approach aims to achieve the highest level of performance.
# Import the necessary module for LoRA configuration
from peft import LoraConfig
# Define the parameters for LoRA configuration
lora_alpha = 16
lora_dropout = 0.1
lora_r = 64
# Create the LoRA configuration object
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM",
target_modules=[
"query_key_value",
"dense",
"dense_h_to_4h",
"dense_4h_to_h",
]
)
We now utilize the SFTTrainer provided by the TRL library, which offers a convenient interface around the Transformers Trainer.
This enables straightforward fine-tuning of models on instruction-based datasets using PEFT adapters. To begin, we'll load the training arguments as shown below.
from transformers import TrainingArguments
# Define the directory to save training results
output_dir = "./results"
# Set the batch size per device during training
per_device_train_batch_size = 4
# Number of steps to accumulate gradients before updating the model
gradient_accumulation_steps = 4
# Choose the optimizer type (e.g., "paged_adamw_32bit")
optim = "paged_adamw_32bit"
# Interval to save model checkpoints (every 10 steps)
save_steps = 10
# Interval to log training metrics (every 10 steps)
logging_steps = 10
# Learning rate for optimization
learning_rate = 2e-4
# Maximum gradient norm for gradient clipping
max_grad_norm = 0.3
# Maximum number of training steps
max_steps = 50
# Warmup ratio for learning rate scheduling
warmup_ratio = 0.03
# Type of learning rate scheduler (e.g., "constant")
lr_scheduler_type = "constant"
# Create a TrainingArguments object to configure the training process
training_arguments = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
fp16=True, # Use mixed precision training (16-bit)
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=True,
lr_scheduler_type=lr_scheduler_type,
)Pass all the configured components to the trainer.
# Import the SFTTrainer from the TRL library
from trl import SFTTrainer
# Set the maximum sequence length
max_seq_length = 512
# Create a trainer instance using SFTTrainer
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="text",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
)We will perform pre-processing on the model by converting the layer norms to float 32. This step is taken to ensure more stable training. Following this, we will proceed with training the model.
# Iterate through the named modules of the trainer's model
for name, module in trainer.model.named_modules():
# Check if the name contains "norm"
if "norm" in name:
# Convert the module to use torch.float32 data type
module = module.to(torch.float32)
trainer.train()Output
In the above tutorial, we have fine-tuned a falcon-7b model on guanaco dataset, which contains questions regarding general-purpose chatbot.
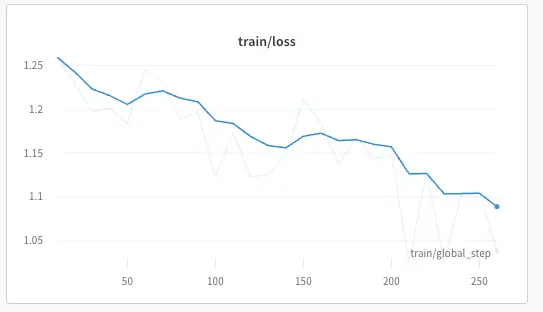
Figure: Loss Plot
From the above loss plot, we can see that the loss continuously decreases over the data. It means the model is learning how to predict output to queries that align with human preferences.
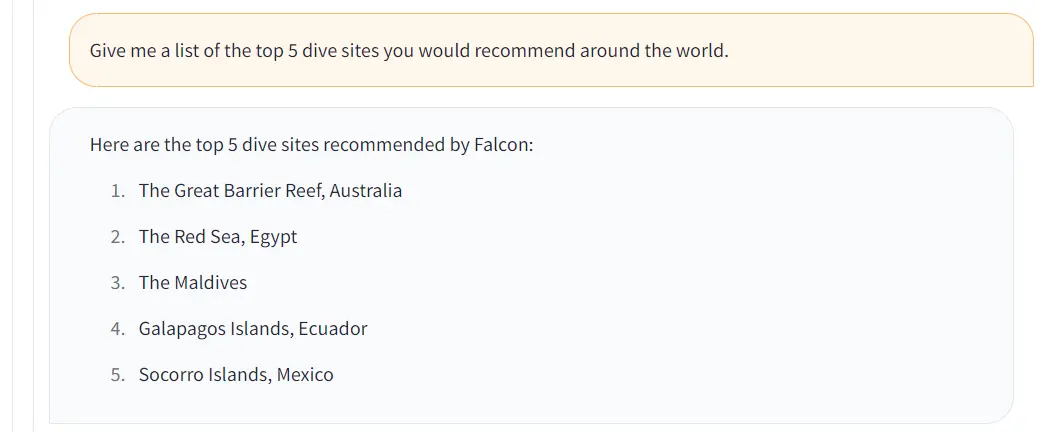
Figure: Output on the fine-tuned falcon-7b model
Conclusion
In this tutorial, we’ve walked through the process of fine-tuning the Falcon-7b model using the Guanaco dataset to create a more effective general-purpose chatbot.
By leveraging techniques like Parameter Efficient Fine-Tuning (PEFT) and tools like QLoRA, you’ve seen how to adapt a powerful pre-trained model to meet specific needs without requiring massive computational resources.
The fine-tuning process allowed the model to learn and improve its responses based on the data provided, leading to a better performance on tasks relevant to real-world applications.
Fine-tuning Falcon-7b has enhanced its ability to serve as a versatile and responsive chatbot.
Whether you're looking to improve customer interactions or need a chatbot that feels more natural, fine-tuning is a powerful tool to make your model work better for your specific needs.
Need help with incorporating Fine-tuning Falcon-7b into your projects?
Talk to our technical experts today!
Frequently Asked Questions
1. What is the Falcon 7B Model?
The Falcon 7B model, known as Falcon-7B-Instruct, is a causal decoder-only model with 7 billion parameters.
Developed by TII (Technology Innovation Institute), this model is built upon the Falcon-7B architecture and has been fine-tuned using a combination of chat and instructive datasets.
2. What is QLora?
QLoRA is a technique designed to enhance the efficiency of large language models (LLMs) by decreasing their memory requirements without compromising performance.
This is achieved through a series of methods, including implementing 4-bit quantization, introducing a novel data type referred to as 4-bit NormalFloat (NF4), double quantization, and utilizing paged optimizers.
3. What is PEFT Library Used For?
Parameter-Efficient Fine-Tuning (PEFT) is a toolkit developed for the efficient adjustment of pre-trained language models (PLMs) for different practical uses, all while avoiding the need to fine-tune every single parameter of the model

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
