

How EgoX Converts Third-Person to First-Person Video
EgoX transforms a single third-person video into a realistic first-person experience by grounding video diffusion models in 3D geometry, enabling accurate egocentric perception without extra sensors or ground-truth data.


Imagine watching the hospital explosion scene in The Dark Knight. In the original film, the camera stands across the street. You observe the Joker from the outside as chaos unfolds behind him.
Now imagine the same scene, but this time you see it through the Joker’s eyes. The hospital looms directly in front of you. Your head turns. The explosion fills your entire field of view. The experience changes completely.
This shift in perspective captures the motivation behind EgoX (Official Paper Link).
Most videos are captured from an exocentric perspective, where the camera observes a person from the outside. In contrast, egocentric video shows the world from a first-person viewpoint, aligned with what the person actually sees. The camera is no longer an observer. It becomes the actor.
EgoX tackles a difficult and precise question. Can we generate a realistic first-person video using only a single third-person video? There is no extra camera, no depth sensor, and no ground-truth egocentric footage. The system must infer an entire viewpoint transformation from one source.
This problem matters because first-person perception is central to how humans and robots interact with the world. In computer vision, it tests whether models can reason beyond pixel alignment.
In robotics, it enables learning embodied behavior from third-person demonstrations. In immersive media, it offers a path to re-experiencing existing footage as if you were inside the scene.
EgoX proposes that this is possible, but only by tightly coupling geometry with generative models.
The Bottleneck - Why Is This Problem So Hard?
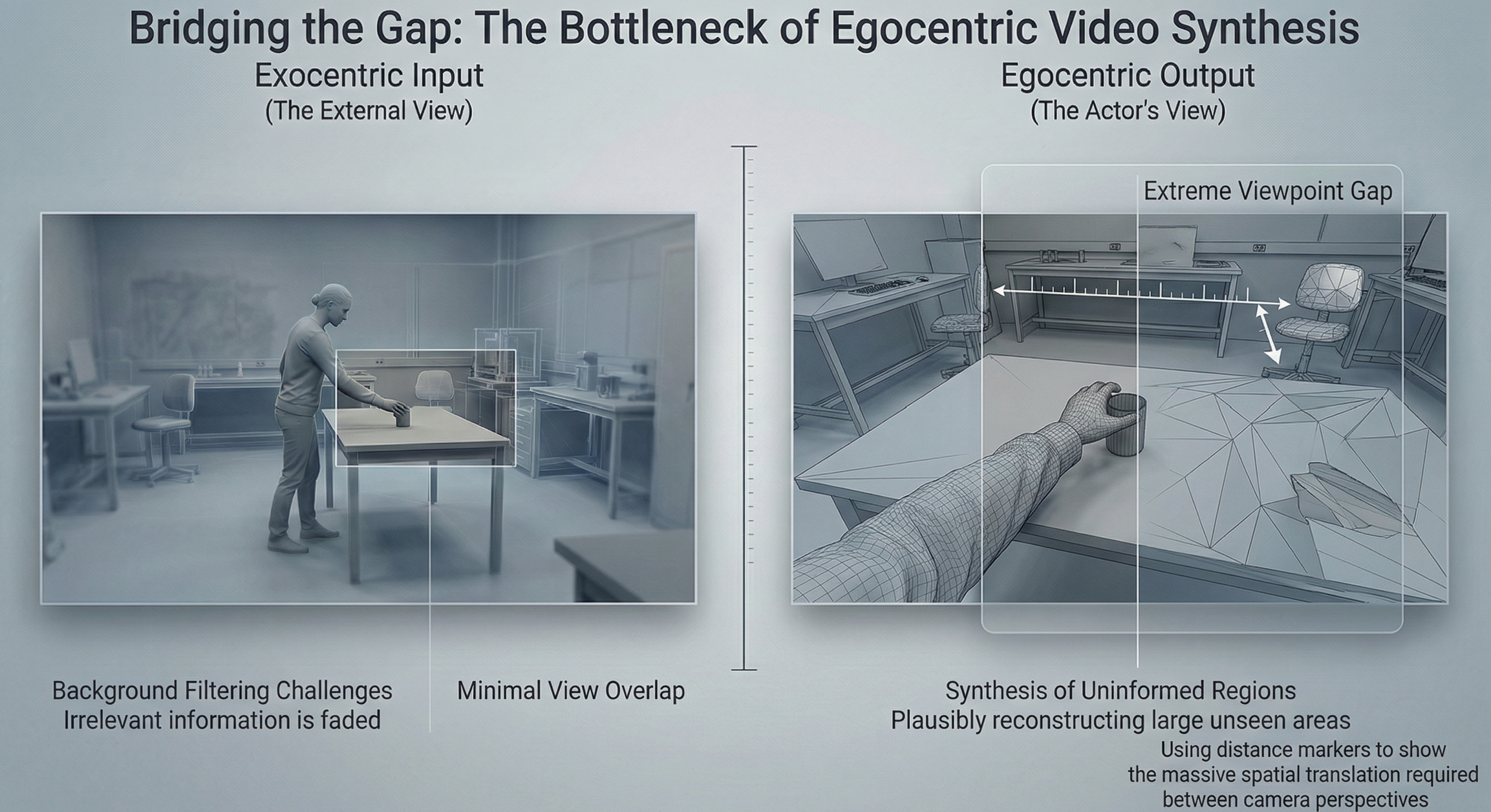
EgoX Bridging the gap
At a glance, egocentric generation may seem related to camera control or novel view synthesis. In practice, it is far more difficult.
The first challenge is the extreme viewpoint gap. Most view synthesis models are designed for small changes in camera pose. They interpolate between nearby viewpoints.
EgoX must bridge a gap that spans meters, not centimetres. The actor’s eyes may be far from the third-person camera, facing a completely different direction. The visible world changes drastically.
The second challenge is synthesizing unseen regions. Large portions of the egocentric view are never visible in the input video. Objects in front of the actor may be off-screen or occluded in the third-person view. The model must hallucinate these regions in a way that is consistent with the scene geometry.
The third challenge is filtering irrelevant information. A wide third-person shot contains many objects that the actor cannot see at all. If the model attends to everything equally, the generated egocentric video becomes cluttered and incorrect.
These challenges make egocentric generation fundamentally harder than standard video editing or viewpoint adjustment. EgoX addresses them by grounding generation in 3D structure and using geometry to control attention.
EgoX Architecture
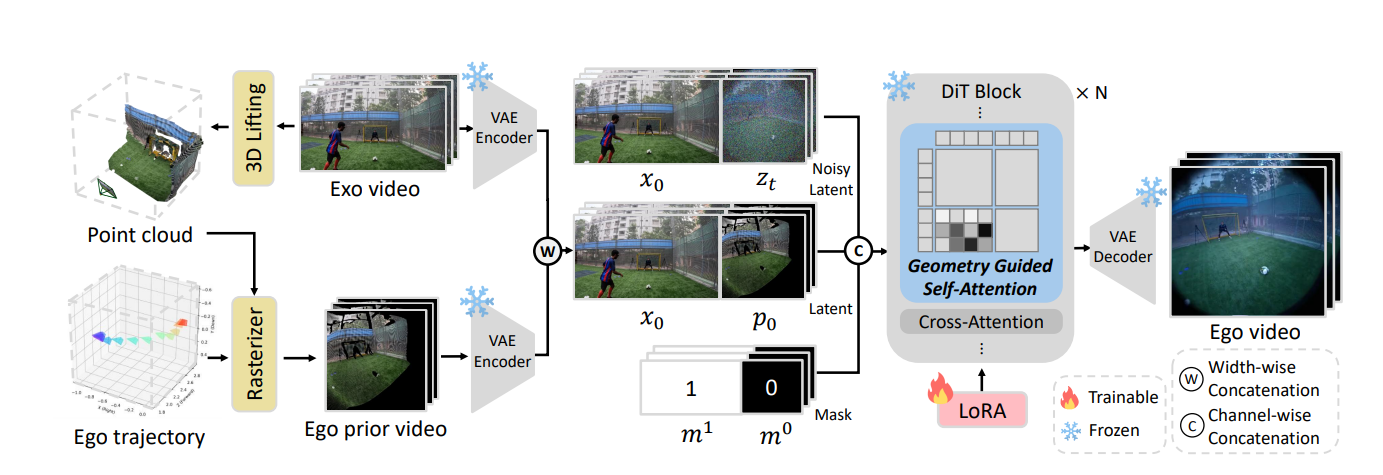
Egox Pipeline
Image Source
EgoX combines two components that are often treated separately. The first is explicit 3D reconstruction. The second is a large-scale pretrained video diffusion model. The system is designed so that geometry provides structure while diffusion provides realism.
Step 1: 3D Point Cloud Rendering
The process begins by lifting the 2D exocentric video into 3D space. This is done by estimating depth for each frame and reconstructing a point cloud representation of the scene.
A direct approach using per-frame monocular depth fails in practice. Monocular depth estimation produces sharp depth maps, but they fluctuate over time. When these depths are used to render video, the result flickers.
EgoX solves this using depth alignment. It combines two depth sources. One source is per-frame monocular depth, which preserves fine details.
The other source is video-based depth, which is smoother across time but less detailed. EgoX aligns these depths using a per-frame affine transformation.
The aligned depth is computed as:
Df = 1 α̂ / Dv + β̂
This equation merges temporal stability with spatial detail. The video-based depth Dv provides smoothness, while the learned parameters α̂ and β̂ restore scale and structure from monocular depth. The result is a depth map that is both stable and detailed.
This equation merges temporal stability with spatial detail. The video-based depth
Once aligned depth is available, EgoX reconstructs a 3D point cloud of the scene. This point cloud is then rendered from the actor’s head pose ϕ to produce a rough egocentric view:
P = render(X, Df, ϕ)
This output, called the egocentric prior, is not a final result. It contains holes, artifacts, and missing details. However, it is geometrically correct. It provides a spatial scaffold for the generative model.
Step 2: Dual-Path Conditioning in the Video Diffusion Model
The egocentric prior alone is not visually realistic. EgoX refines it using a pretrained video diffusion model. The key innovation lies in how conditioning information is injected into the diffusion process.
EgoX uses a dual-path conditioning strategy.
The first path is a channel-wise stack of the egocentric prior with the noisy latent. Because the egocentric prior is already aligned with the target viewpoint, it provides explicit spatial guidance. It tells the model where objects should appear.
The second path is a width-wise stack of the original exocentric video. The third-person video is placed side-by-side with the latent. This preserves high-frequency visual details such as texture and color. It allows the model to implicitly learn cross-view correspondences without explicit warping.
The diffusion denoising step is defined as:
zt−1 = fθ(x0, zt ∣ x0, p0 ∣ m1, m0)
Here, zt is the noisy latent at timestep t, x0 is the clean exocentric latent, and p0 is the egocentric prior. The masks m1 and m0 control which regions are visible.
Through iterative denoising, the model removes noise while respecting both geometric constraints and visual appearance.
The Secret Sauce Geometry-Guided Self-Attention (GGA)
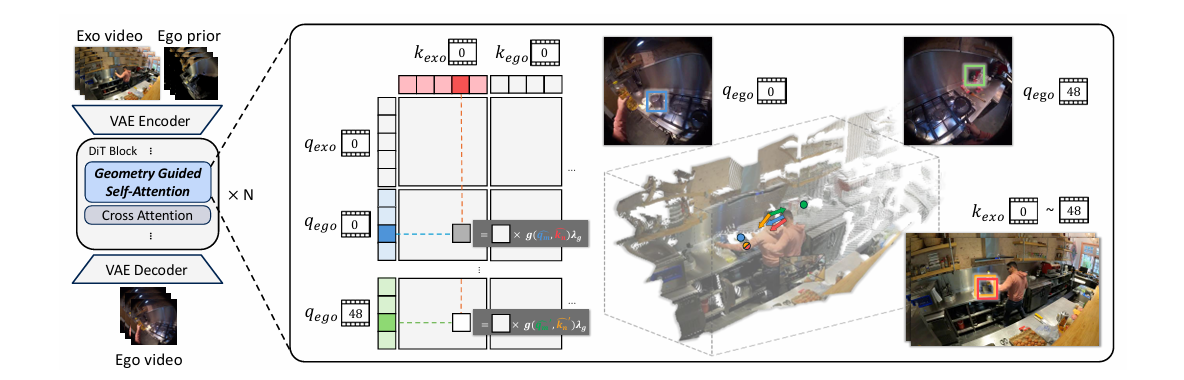
Geometry-Guided Self-Attention Overview
Image Source
Even with careful conditioning, a diffusion model can still attend to irrelevant regions of the input. EgoX introduces Geometry-Guided Self-Attention (GGA) to explicitly control where attention is allowed to flow.
GGA can be understood as a smart highlighter. Instead of allowing attention to spread freely across all pixels, it biases attention toward regions that are physically visible from the actor’s viewpoint.
To achieve this, EgoX uses the reconstructed 3D point cloud. For every spatial token in the attention layer, it computes a unit direction vector from the actor’s eye position to the corresponding 3D point. These direction vectors encode where each region lies relative to the actor’s gaze.
Let s(m,n) denote the original attention logit between query token m and key token n, as computed by standard dot-product attention. EgoX modifies this logit using geometric information:
s(m,n)′ = s(m,n) + log(g(q̂m, k̂n) · λg)
Here, s(m,n)′ is the geometry-adjusted attention logit.
The term q̂m denotes the unit direction vector from the actor’s eyes
to the 3D point corresponding to the query token m.
Similarly, k̂n is the unit direction vector associated with the key token n.
The scalar λg is a geometry strength coefficient that controls how strongly
geometric alignment influences attention.
The function g(·, ·) measures directional alignment and is defined as:
g(â, b̂) = cos(â, b̂) + 1
In this expression, cos(â, b̂) denotes cosine similarity between two unit vectors.
Cosine similarity is high when the two directions point in the same direction and low (or negative)
when they diverge.
Adding 1 shifts the range to ensure the value is non-negative, which is
necessary for stable log-space computation.
Intuitively, this means that if a region lies within or near the actor’s viewing direction, its corresponding attention logit is boosted. If it lies behind the actor or far outside the field of view, its contribution is suppressed.
This geometric bias is then incorporated into the final attention weights:
a(m,n) = exp(s(m,n)) · g(q̂m, k̂n)λg ∑j=1l exp(s(m,j)) · g(q̂m, k̂j)λg
Here, a(m,n) represents the final normalized attention weight between query m and key n. The index j runs over all l key tokens in the attention layer. The geometric term acts as a multiplicative prior inside the SoftMax normalization.
As a result, tokens corresponding to geometrically visible regions receive higher attention weights, while tokens associated with irrelevant background or occluded areas are systematically down-weighted.
In effect, geometry becomes a hard constraint on attention. The model is no longer free to attend to visually salient but physically impossible regions. It is forced to focus on what the actor can actually see, enforcing egocentric consistency at the level of the attention mechanism itself.
Evaluation Metrics
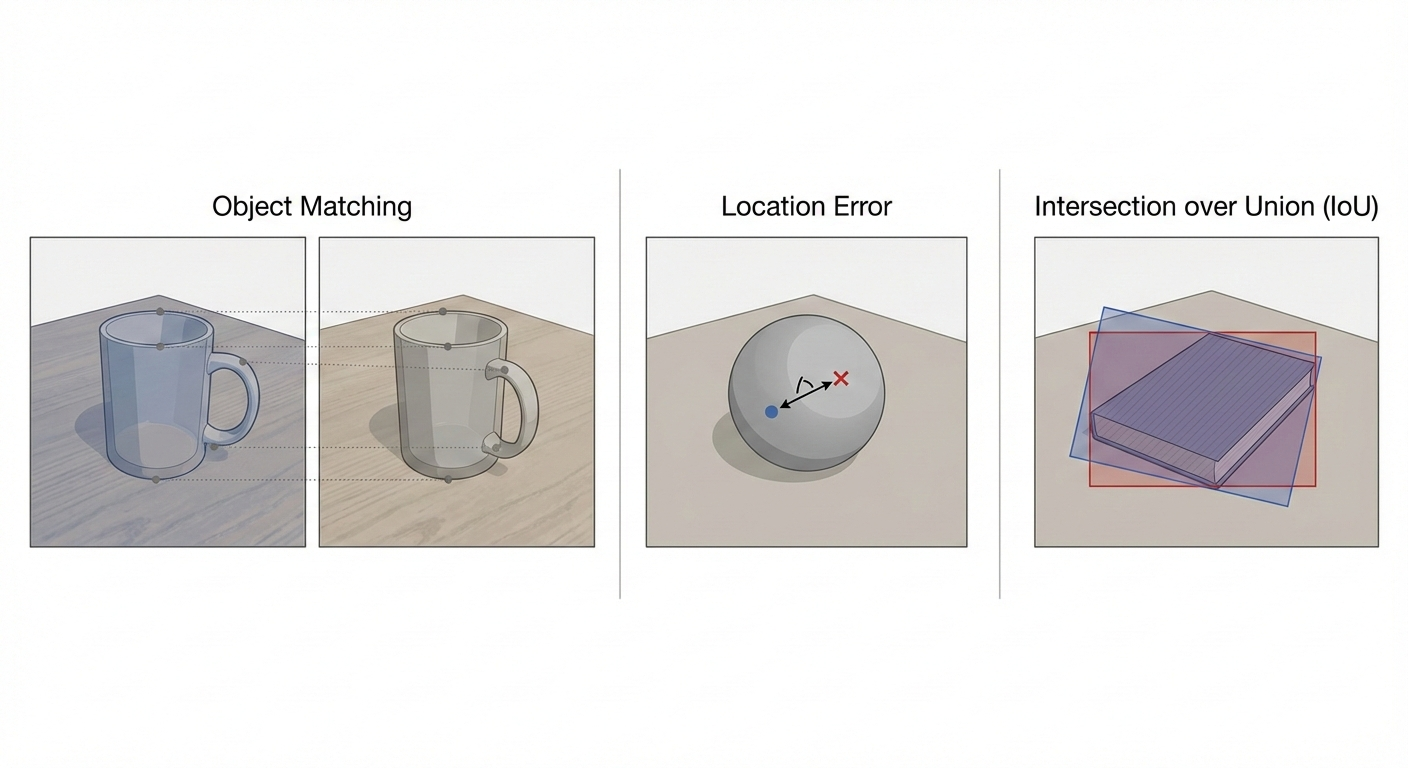
Metrics Used
Evaluating egocentric video generation cannot rely on visual inspection alone. EgoX uses objective metrics that measure whether objects appear in the correct place and shape.
object matching, Objects detected in the generated video are matched with ground-truth objects using feature similarity. This measures whether the generated object corresponds to the correct real-world object.
Location error, denoted Eloc, measures the Euclidean distance between predicted and ground-truth object centers. Lower error indicates more accurate spatial placement.
Intersection over Union (IoU) is computed both for bounding boxes and object contours. It measures how well the generated object overlaps with the ground truth in both position and shape.
Together, these metrics verify that EgoX does not just produce plausible images. It produces geometrically correct egocentric views.
What Problem EgoX Solves (and What It Doesn’t)
EgoX enables something that prior methods could not. It generates first-person video from a single third-person input while preserving spatial consistency and motion coherence. It generalizes to in-the-wild videos because it relies on geometry rather than dataset-specific cues.
However, EgoX is not without limitations. The system depends on accurate depth estimation. Errors in depth propagate into the 3D reconstruction and affect the egocentric prior.
Extreme occlusions remain challenging, especially when large portions of the egocentric view are completely unseen. Fast motion can also stress the depth alignment process.
These limitations are not ignored. They define clear directions for future work.
Conclusion
EgoX demonstrates a powerful idea. Large pretrained video diffusion models become far more capable when anchored in 3D geometry. Geometry provides structure, visibility, and attention control. Diffusion provides realism and detail.
By using LoRA-based fine-tuning with rank 256, EgoX adapts large models efficiently without full retraining. This makes the approach practical and scalable.
The broader insight is clear. Bridging third-person and first-person perception is not just a rendering problem. It is a step toward embodied AI, where models understand scenes as agents within them, not observers outside them.
FAQs
What problem does EgoX solve?
EgoX generates realistic first-person (egocentric) video from a single third-person video by combining 3D geometry with generative diffusion models.
How is EgoX different from standard view synthesis methods?
Unlike traditional view synthesis that handles small camera shifts, EgoX bridges large viewpoint gaps and hallucinated regions using explicit 3D reasoning.
Why is geometry important in EgoX?
Geometry ensures spatial correctness, visibility constraints, and attention control, preventing the model from generating physically impossible views.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
