

EgoControl: Why First-Person Video Generation Needs the Whole Body, Not Just the Camera
EgoControl reframes egocentric video generation as embodied simulation. By conditioning diffusion models on future 3D full-body poses, it enables controllable, physically grounded first-person video prediction aligned with intended human motion.

Egocentric video generation sounds simple. Put a camera on a person’s head, model what they see, and generate the future. In practice, it is one of the hardest problems in generative vision.
The camera is not free-floating. It is rigidly attached to a human body that walks, turns, bends, reaches, and interacts with objects. Every movement of the torso or arm reshapes the visual field. This tight coupling between action and perception is exactly what most video generation models fail to capture.
Existing text-to-video or trajectory-conditioned models can synthesize beautiful sequences, but they struggle when asked to behave like an embodied agent. They do not know what it means to move through the world with a body.
As a result, their outputs look good but are not controllable in the way robotics, AR, or embodied AI systems require. EgoControl is designed to address this gap head-on.
The core of EgoControl is simple and ambitious, given a short history of egocentric video and a planned sequence of 3D full-body poses, generate the future video that would result if that motion were actually executed.
This framing turns video generation into visual simulation. Instead of guessing what might happen next, the model predicts what should happen, given an intended action.
Gaps in Existing Egocentric Video Models
To understand why EgoControl matters, it helps to look at what prior approaches actually control.
Many video diffusion models condition on:
- Text prompts
- Image context
- Camera trajectories or head pose
For third-person video, this is often sufficient. The subject is visible. The camera moves independently. But egocentric video is different. The “actor” and the “camera” are the same entity.
Head-pose-only control captures global camera motion translation and rotation of the viewpoint but ignores articulation. Arms and hands are not optional details in first-person video.
They are dominant visual elements. They create occlusions, enable object interaction, and define the semantics of actions like reaching, grabbing, or placing.
The EgoControl paper demonstrates that when only head motion is provided, models tend to hallucinate arm motion. The camera may turn correctly, but the body does not reliably follow. This makes head-only control fundamentally insufficient for embodied reasoning.
The missing ingredient is full-body understanding.
What EgoControl Actually Does
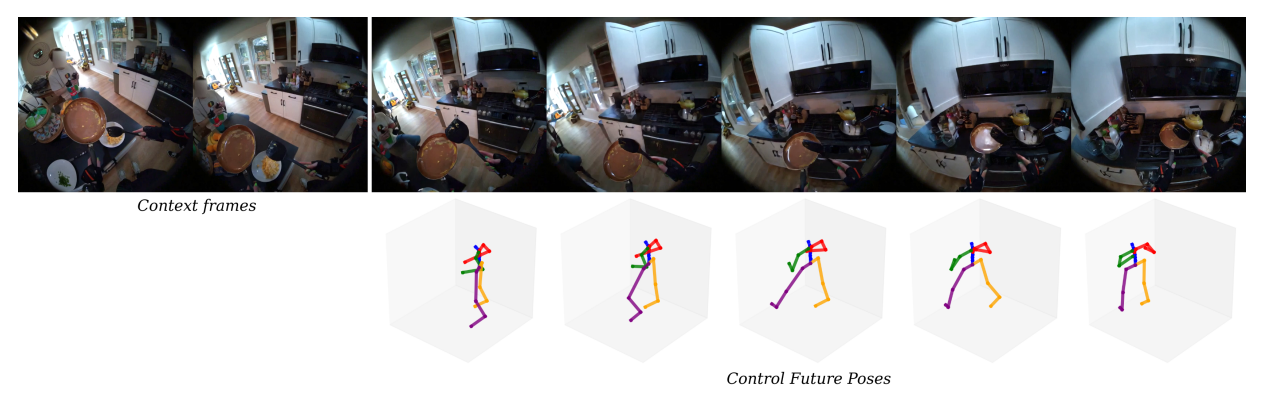
Pose Driven Egocentric View
EgoControl is framed as a conditional video prediction problem.
The model receives two inputs:
- Past visual context
A short sequence of observed egocentric frames
x = (x1, x2, …, xN)
- Future motion intent
A sequence of target 3D human poses
P = (p1, p2, …, pM)
The goal is to generate future frames that are visually realistic and aligned with the provided pose sequence.
This formulation turns egocentric video generation into a controllable process: given an intended body motion, the model predicts what the agent will see if that motion is executed.
EgoControl is built on a latent video diffusion model using a Diffusion Transformer (DiT). Frames are encoded into a compact latent space, diffusion noise is added, and a denoiser learns to reconstruct the clean latent representation conditioned on both visual history and pose.
The diffusion objective follows the EDM formulation used in the paper:
z = z0 + σε, ε ∼ N(0, I)
Here:
- z0 is the clean latent representation of video frames
- σ is a continuous noise level
- ε is Gaussian noise
The model learns a denoiser zθ by minimizing:
L(θ) = E[ w(σ) ‖ zθ(z, σ, c) − z0 ‖22 ]
Where:
- c is the conditioning context (past frames and pose)
- w(σ) weights different noise levels
- zθ is the denoising network, implemented as a DiT
The novelty is not the diffusion framework itself but how pose is represented and injected.
How EgoControl Represents Pose
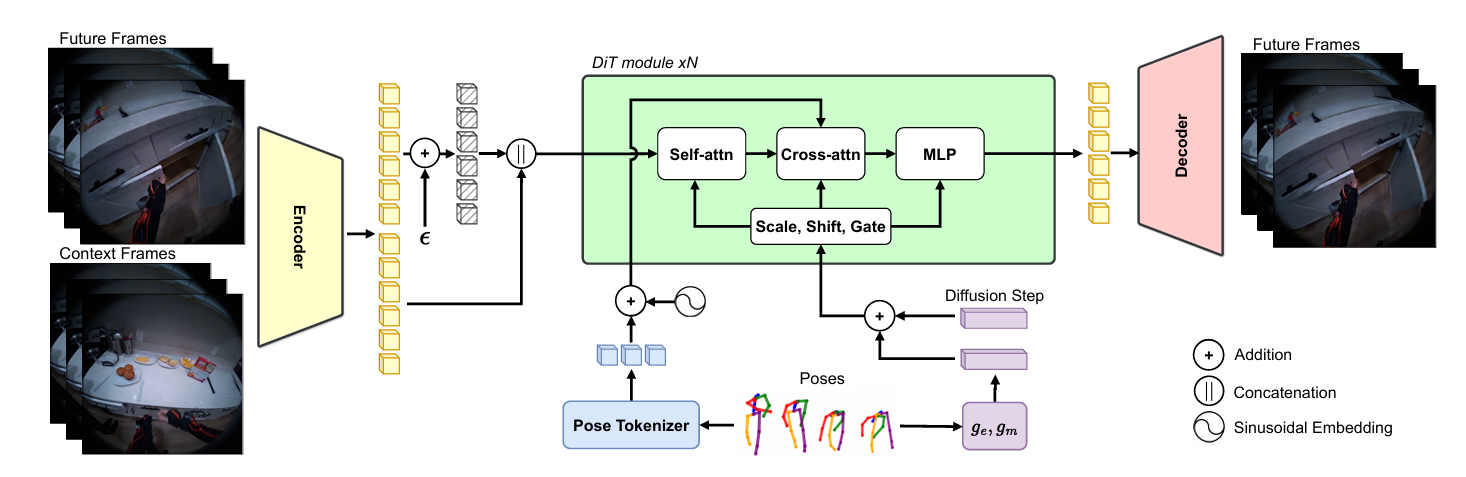
Overview of Architecture
Raw global poses are not ideal for egocentric generation. They grow unbounded over time and do not reflect the agent’s own motion. EgoControl instead uses a differential, egocentric pose representation.
Each future pose sequence is represented using 23 body joints. Every joint is encoded as a 6D vector consisting of 3D translation and 3D rotation parameters. For a sequence of M future frames, the full pose tensor is defined as:
P ∈ R(M × 23 × 6)
Here:
- M is the number of future timesteps to be generated
- 23 is the total number of joints (including head and pelvis)
- 6 corresponds to three translation and three rotation values per joint
This pose representation is composed of three complementary components.
Relative head motion
Let Hi ∈ R(4 × 4) denote the global rigid-body transformation matrix of the head at frame i, encoding both its position and orientation in the world. EgoControl computes frame-to-frame head motion using the relative transformation:
ΔHi = Hi Hi−1−1
Here:
- Hi−1−1 is the inverse transformation of the previous frame
- ΔHi captures how the head moves between consecutive frames rather than where it is globally
Each relative transformation ΔHi is then converted into a 6D vector Δhi, representing relative translation and rotation. This sequence models the camera motion experienced by the wearer.
Pelvis root motion
The pelvis is treated as the root of the articulated body. Its frame-to-frame motion delta R is computed using the same relative formulation as the head. This captures global body movement such as walking, turning, or bending, independently of camera orientation.
Pelvis-centric joint positions
All remaining joints (excluding head and pelvis) are represented relative to the pelvis at each frame. Instead of encoding joint motion across time, EgoControl encodes their spatial configuration with respect to the body’s root.
This local coordinate system stabilizes learning and preserves body coherence and these components are concatenated to form the final control signal:
P = [ Δh, Δr, J ]
Where:
- Δh represents relative head motion
- Δr represents relative pelvis motion
- J contains pelvis-relative joint transformations for the remaining joints
Ablation studies show that this design choice is critical. Using cumulative pose representations where motion is encoded relative to the initial frame nearly doubles translation error due to numerical drift.
Similarly, encoding joints via frame-to-frame differences reduces body coherence. In contrast, pelvis-centric joint representations improve arm alignment by over 5 mIoU points, and differential motion remains stable over long horizons. This makes the pose signal both physically meaningful and easier for the model to learn.
Dual-Path Pose Conditioning: Global and Local Control
Dual path pose
Injecting pose into a diffusion transformer is non-trivial. EgoControl uses two complementary mechanisms, each solving a different control problem.
Global modulation with Adaptive Layer Normalization
The entire pose tensor P is first flattened across time, joints, and dimensions into a single global vector Pflat. This vector summarizes the full-body motion intent over the prediction horizon.
Two small multi-layer perceptrons (MLPs) then process Pflat. One produces a global pose embedding eP, while the other outputs modulation parameters (βm, γm, g) that are used to control the network.
These modulation parameters govern shift, scale, and gating inside every transformer block through Adaptive Layer Normalization, allowing the pose information to directly influence the internal feature transformations of the diffusion model.
These parameters control shift, scale, and gating inside every transformer block using Adaptive Layer Normalization:
AdaLN(u) = LN(u) ⊙ (1 + γ) + β
Where:
- u: input feature vector to a transformer block
- "LN"(·): layer normalization operation
- γ: scale parameter predicted from pose (controls feature amplification)
- β: shift parameter predicted from pose (controls feature bias)
This mechanism lets pose and diffusion timestep jointly influence the global behavior of the network camera motion, scene dynamics, and overall styling.
Fine-grained control with cross-attention
Global modulation alone is not enough for precise articulation. EgoControl therefore adds a second pathway.
Each frame’s pose Pm ∈ R(23 × 6) is projected into a pose token:
Pm′ = LayerNorm(GELU(Wp Pm))
Where:
- Pm: pose matrix for frame m, containing 23 joints with 6D representations
- Wp: learnable projection matrix mapping pose to model feature space
- "GELU"(·): Gaussian Error Linear Unit activation
- "LayerNorm"(·): normalization applied to stabilize pose embeddings
- Pm′: pose token corresponding to frame m
Temporal order is preserved using sinusoidal positional encoding. These pose tokens are then used as cross-attention context inside the transformer.
This gives the model localized, frame-specific signals needed to place arms and body parts accurately over time.
Why Full-Body Pose Beats Head Pose
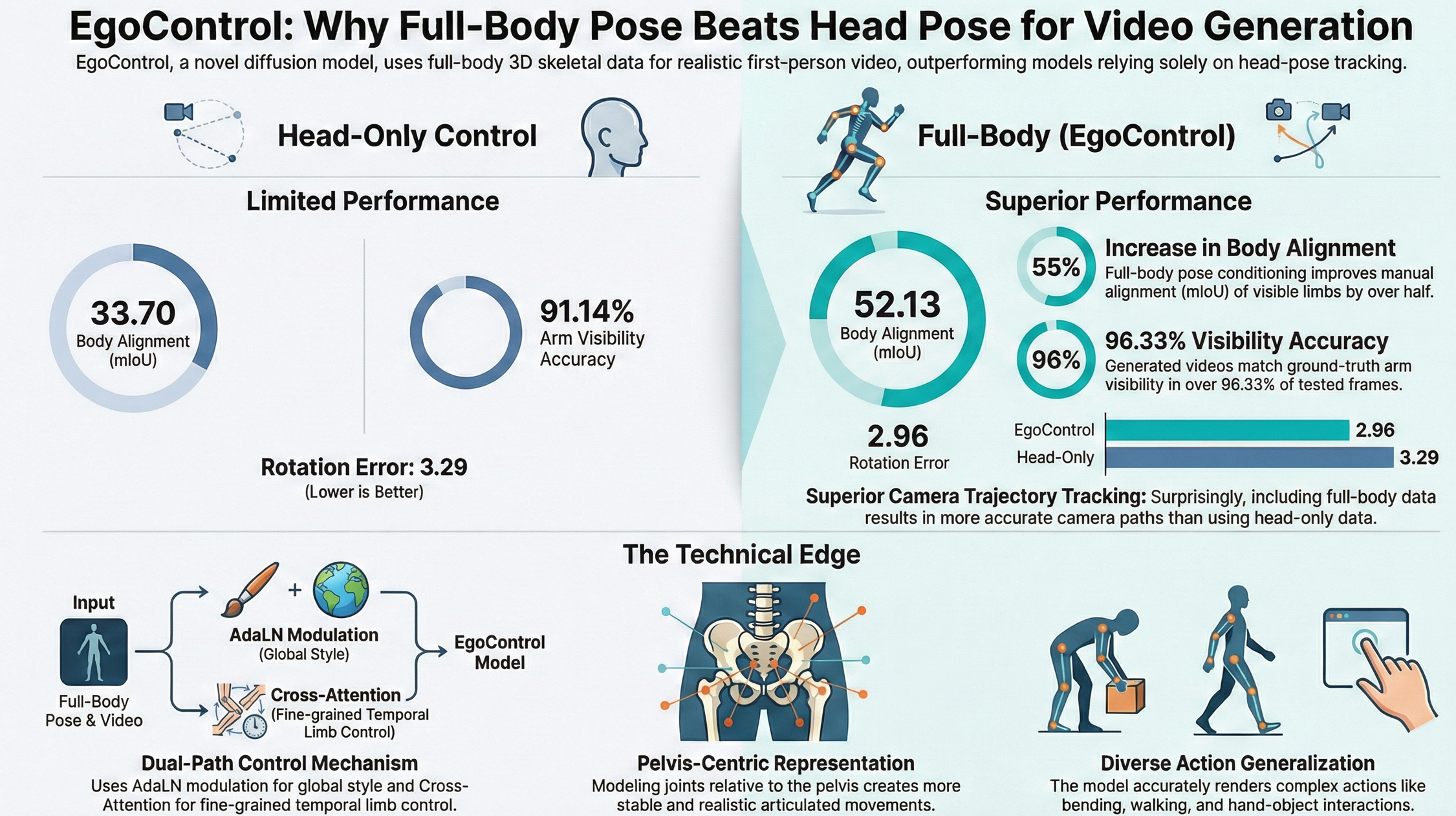
Pelvis Motion Dynamics
A key insight of EgoControl is that egocentric perception is governed by body configuration, not just camera orientation.
Consider a person bending down to pick up an object from the floor. The head tilts downward, but the dominant visual changes come from the body: arms enter the frame, hands occlude the scene, and the torso shifts the viewpoint relative to nearby objects.
The moment the hand reaches forward, it partially blocks the camera and reshapes the visual field before any object contact occurs. None of these effects can be inferred reliably from head motion alone.
The paper quantifies this gap using explicit body-control metrics. When comparing head-only conditioning to full-body conditioning, EgoControl reports:
- Mean Intersection-over-Union (mIoU) for visible arms
- Head-only: 33.70
- Full-body: 52.13
- Arm visibility accuracy
- Head-only: 91.14%
- Full-body: 96.33%
This corresponds to a 55% relative improvement in body alignment accuracy when full-body pose is used. Notably, full-body conditioning also improves camera motion accuracy, reducing both translation and rotation error. Knowing how the body moves provides additional constraints that help the model render egocentric camera motion more faithfully.
These results directly challenge the assumption that egocentric video generation can be reduced to camera control alone.
How Well EgoControl Simulates Embodied Motion

EgoControl (row 4) shows notable improvements across all dimensions over the baseline and the head only control.
Table source
EgoControl is trained and evaluated on Nymeria, the largest in-the-wild egocentric dataset with synchronized 3D full-body motion capture. Nymeria contains over 1,100 high-resolution egocentric video sequences recorded at 30 FPS using head-mounted fisheye cameras, each aligned with full-body poses captured using Xsens motion capture suits. For training, videos are resampled to 16 FPS, resized to 480×480, and split into 45-frame clips, using 13 past frames as context to generate 32 future frames (2 seconds).
The evaluation protocol tests whether EgoControl can act as a reliable embodied visual simulator across three dimensions.
Visual quality.
Realism and temporal consistency are measured using FVD, SSIM, LPIPS, and DreamSim. EgoControl achieves an FVD of 20.18, a large improvement over the off-the-shelf Cosmos model (71.00) and the fine-tuned baseline (40.70). Perceptual metrics also consistently improve when conditioning on full-body pose.
Global motion accuracy.
Camera motion is evaluated by extracting trajectories from generated videos using Vipe. EgoControl reduces translation error to 4.90 and rotation error to 2.96, outperforming both head-only control (5.16 / 3.29) and the fine-tuned baseline (9.93 / 13.65). Full-body pose conditioning improves camera accuracy beyond head motion alone.
Body control fidelity.
Visible arms are segmented and tracked using SAM2. EgoControl achieves an mIoU of 52.13, compared to 33.70 for head-only control and 25.13 for the baseline. Arm visibility accuracy reaches 96.33%, indicating reliable and consistent body presence.
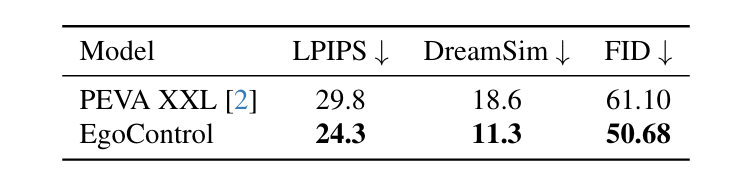
Comparison with PEVA XXL
Across all metrics, full-body pose conditioning clearly outperforms baselines. EgoControl also surpasses the concurrent PEVA method at a comparable 2-second prediction horizon, achieving a lower LPIPS (24.3 vs. 29.8) while generating full video sequences rather than a single frame.
Open Challenges in EgoControl
The current limitations of EgoControl, framing them as open research challenges rather than shortcomings of the approach.
Limited hand articulation
Nymeria does not include finger-level pose annotations. As a result, EgoControl models arm motion and coarse hand placement, but cannot represent fine-grained finger articulation or detailed manipulation.
Dataset bias
The training data is collected using head-mounted fisheye cameras and full-body motion-capture suits. This introduces bias toward a specific capture setup and may limit generalization to everyday clothing, alternative camera configurations, or different sensor rigs.
Long-horizon stability
While EgoControl can generate sequences autoregressively for up to 8 seconds, maintaining strict temporal consistency over longer horizons remains difficult, a challenge shared by diffusion-based video models in general.
Conclusion
EgoControl reframes egocentric video generation as embodied simulation. By conditioning on full-body pose, it aligns perception with action, allowing future visuals to emerge from intended movement rather than inferred camera motion.
This shift enables new capabilities in robotics, action-conditioned world models, and AR/VR systems that preview motion before execution. For teams working in this space, booking a call with Labellerr can help explore suitable robotics data needs.
More importantly, it establishes a key insight: egocentric vision is not governed by the camera alone. The body is the control signal, and recognizing this changes how controllable video generation should be built going forward.
What makes egocentric video generation difficult compared to third-person video?
Egocentric video tightly couples camera motion with full-body movement, making articulation, occlusion, and interaction harder to model than free-moving cameras.
Why is full-body pose important for egocentric video generation?
Full-body pose captures arm, torso, and pelvis motion that directly affects the visual field, enabling accurate, controllable, and embodied video prediction.
How does EgoControl improve controllability in video generation?
EgoControl conditions video diffusion on future 3D full-body poses, allowing the model to simulate what an agent will see when executing a planned motion.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
