

Edge AI: Deployment of AI/ML Models Via Compression of Machine Learning Models


Table of Contents
- Introduction
- Challenges in the Deployment of ML Models over Edge Devices
- Technology Behind Models Compression
- Conclusion
- Frequently Asked Questions (FAQ)
Introduction
Are you confident that maximum potential is being achieved in neural networks? It's possible that untapped opportunities are being overlooked!
Most AI developers utilize various optimization techniques for their neural networks. Some developers rely on built-in features of frameworks like PyTorch, while others invest significant time integrating with tools like TensorRT.
In some instances, developers manually explore different architectures through trial and error. Although pruning is a commonly known method, there are numerous aspects to consider in neural network optimization.
But why go through the effort of optimizing neural networks? Optimization involves achieving the same results with fewer computational resources. Depending on the specific use case, several benefits can be obtained through optimization:
- Improved computational efficiency: Optimization techniques can accelerate neural networks on existing hardware by 2-5 times, resulting in faster inference times. (Source: NVIDIA)
- Resource utilization: Optimization allows for accommodating more features or neural networks on current hardware, leading to better utilization of computational resources. (Source: NVIDIA)
- Cost reduction: Target hardware costs can be reduced by up to 80% by optimizing neural networks, and cloud computing costs can be decreased by around 70%. This translates to significant cost savings in deploying AI models. (Source: Intel)
- Power efficiency: Optimized neural networks minimize power consumption on hardware, which is crucial for edge devices with limited power budgets. This improves the overall energy efficiency of AI systems. (Source: Intel)
- Streamlined development process: Optimization techniques can reduce development time and costs by up to 90% by automating the exploration of optimal neural network architectures. This saves valuable time for AI developers. (Source: Enot.ai)
While these benefits appeal, optimizing neural networks to their full potential can be challenging and time-consuming. It requires modifying the architecture of neural networks to find the optimal combination of numerous input parameters. Manually exploring thousands of potential parameter variations can be a daunting task.
A novel solution has been developed to overcome the challenges in optimizing neural network architectures, focusing on achieving high compression and acceleration rates while maintaining accuracy.
Developers can benefit from valuable time savings by integrating advanced tools into neural network training pipelines.
These tools automate exploring optimal neural network architectures, considering factors such as latency, accuracy, RAM, model size constraints, and hardware/software platforms. The solution enables users to find the most suitable architecture that fulfills their needs and requirements.
The goal is to achieve the highest compression/acceleration rates without sacrificing accuracy. By leveraging this solution, developers can streamline their AI development process and benefit from efficient and effective neural network architectures.
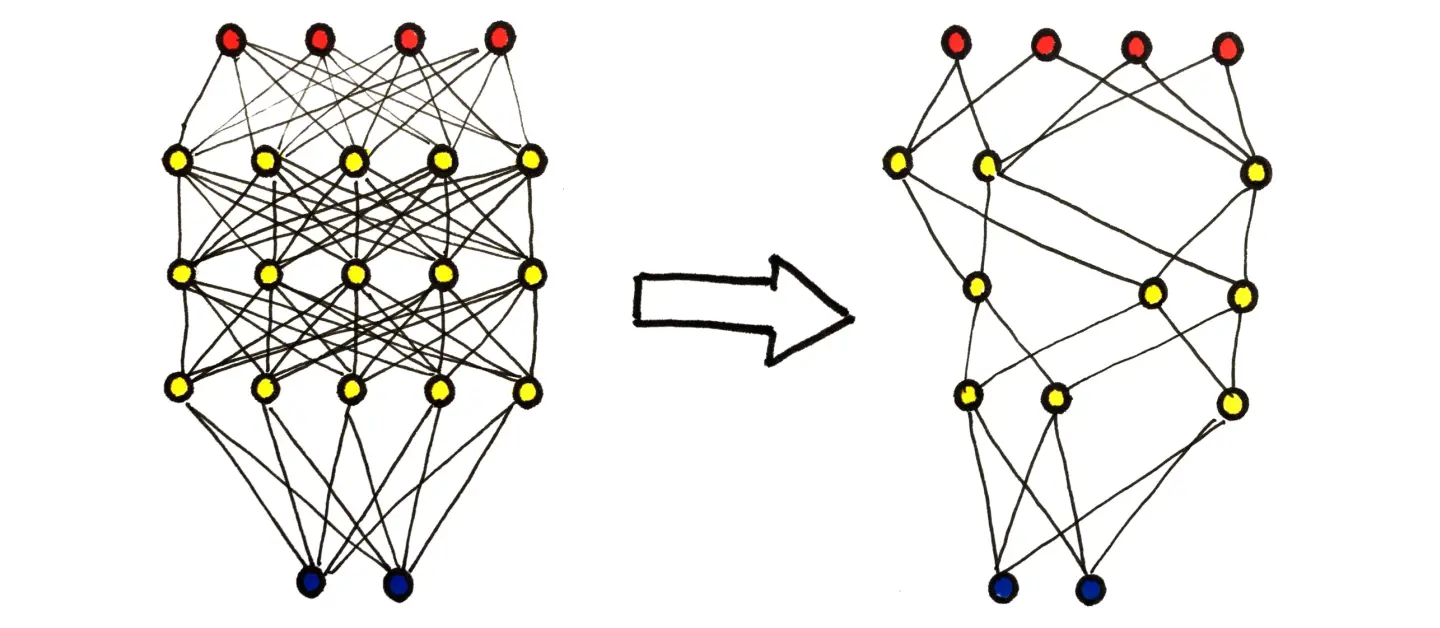
Figure: Compressing Neural Network
Challenges in the Deployment of ML Models over Edge Devices
Deploying machine learning (ML) models over edge devices, such as mobile phones, Internet of Things (IoT) devices, and embedded systems, presents several unique challenges.
While edge deployment offers advantages like low latency, improved privacy, and reduced dependence on cloud connectivity, it also introduces certain obstacles that must be addressed. Here are some of the critical challenges in deploying ML models over edge devices:
- Limited Computing Resources
Edge devices often have limited computational power, memory, and energy resources compared to cloud servers.
ML models, especially complex deep learning models, require significant computational resources, making deploying them directly on edge devices challenging. Optimizing and compressing ML models to fit within these constraints becomes crucial.
2. Model Size and Complexity
Modern ML models can be large and complex, making it difficult to deploy them on edge devices with limited storage capacity. Reducing the size of ML models without compromising their performance is essential for efficient edge deployment.
3. Energy Efficiency
Batteries typically power edge devices or have limited power budgets. ML models with high computational requirements can quickly drain the battery and impact the device's energy efficiency. Balancing the accuracy of ML models with their energy consumption is critical for edge deployment.
4. Real-Time Inference
Some applications require real-time or near-real-time inference on edge devices. However, performing complex computations within tight time constraints can be challenging, mainly when dealing with resource-constrained devices.
Achieving low-latency inference while maintaining accuracy is a significant challenge in edge deployment.
5. Model Updates and Maintenance
Deploying ML models on edge devices also brings challenges related to model updates and maintenance. Edge devices may have limited connectivity or intermittent network access, making it challenging to deploy model updates seamlessly. Also, managing different model versions across edge devices can be complex and time-consuming.
To address this challenge, enot.ai was established. The tools provided by enot.ai enable the achievement of the highest compression/acceleration rates with minimal or no loss in accuracy, resulting in valuable time savings.
The search engine facilitates the automated exploration of optimal neural network architectures, considering latency, accuracy, RAM, model size constraints, various hardware and software platforms, and other parameters. Various benefits and Advantages are offered by utilizing Enot.AI, which include:
- Neural networks can be accelerated on existing hardware by 2-5 times.
- More features/neural networks can be accommodated on current hardware.
- Target hardware costs can be reduced by up to 80%.
- Cloud computing costs can be decreased by around 70%.
- Power consumption on hardware can be minimized.
- Development time and costs can be reduced by up to 90%.
Technology Behind Models Compression
During the optimization process, enot.ai's engine considers multiple parameters to achieve the highest compression and acceleration rates without compromising accuracy.
Their Neural Network Architecture Selection technology enables the automatic selection of a sub-network from a pre-trained neural network that offers increased speed while maintaining the same level of accuracy.
Additionally, enot.ai's engine automates the search for the optimal neural network architecture, considering various constraints such as latency, RAM usage, and model size for different hardware and software platforms.
The parameters considered include input resolution, depth of the neural network, number of filters at each layer, and latency of each operation on the target hardware.
Conclusion
In conclusion, optimizing neural networks to their maximum potential can be challenging but highly beneficial.
By achieving high compression and acceleration rates without sacrificing accuracy, developers can unlock several advantages such as accelerated performance, accommodating more features/neural networks on existing hardware, reducing target hardware costs, decreasing cloud computing costs, minimizing power consumption, and reducing development time and costs.
However, manually exploring neural network architectures and parameter variations can be time-consuming and daunting.
A novel solution provided by enot.ai has been developed to address this challenge. Their advanced tools automate exploring optimal neural network architectures, considering factors like latency, accuracy, RAM, model size constraints, and hardware/software platforms.
By leveraging this solution, developers can streamline their AI development process and benefit from efficient and effective neural network architectures.
Deploying ML models over edge devices introduces unique challenges such as limited computing resources, model size and complexity, energy efficiency, real-time inference requirements, and model updates and maintenance.
To address these challenges, enot.ai's tools offer valuable capabilities in achieving high compression/acceleration rates, making edge deployment more efficient and effective.
By optimizing and compressing ML models, balancing accuracy with energy consumption, and automating the selection of optimal architectures, enot.ai enables developers to overcome these obstacles and harness the potential of edge devices for ML model deployment.
Frequently Asked Questions (FAQ)
- What is edge deployment?
Edge deployment refers to deploying computing resources and services closer to the edge devices, such as smartphones and IoT devices, rather than relying solely on centralized cloud infrastructure.
It enables local data processing and analysis, reducing latency and improving real-time responsiveness. By bringing computation closer to the point of data generation and consumption, edge deployment offers benefits such as low latency, improved privacy and security, and reduced dependence on cloud connectivity.
2. What are the challenges in deploying ML models over edge devices?
Deploying ML models on edge devices presents several challenges, including:
- Limited computing resources (power, memory, and energy) compared to cloud servers.
- Model size and complexity, as modern models can be large and difficult to fit within storage constraints.
- Energy efficiency, as high computational requirements, can quickly drain the device's battery.
- Real-time inference within tight time constraints on resource-constrained devices.
- Model updates and maintenance, mainly when devices have limited connectivity or intermittent network access.
3. How does model compression benefit ML model deployment on edge devices?
Model compression reduces the size of ML models without compromising performance. This enables ML models to fit within the limited storage capacity of edge devices.
Compressed models require fewer computational resources, resulting in improved energy efficiency, reduced latency, and enhanced overall performance on edge devices.
4. What is the process of deployment of a model over edge devices?
The deployment process of machine learning models involves several steps. Here is a paraphrased version of the steps:
- Model Development and Training: This step involves developing and training a machine-learning model using existing data.
- Model Validation (Testing): After training the model, it is important to validate its performance using a separate dataset.
- Model Deployment: Once the model is validated, it is ready for deployment. This step involves making the model accessible for use in production environments.
- Monitoring the Model: After deployment, monitoring the model's performance and behavior in real-world scenarios is essential. This includes tracking metrics, detecting anomalies, and ensuring that the model provides accurate and reliable predictions.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
