

Different Methods To Employ Data Labelling In Machine Learning Tasks

Often, data labeling goes hand in hand with data acquisition. When compiling information from the Web to create a knowledge base, each fact is considered accurate and is therefore implicitly labeled as true. In the context of data labeling literature, it's useful to separate it from data acquisition due to the distinct techniques involved.
After obtaining sufficient data, the next phase involves assigning labels to individual instances. For example, in a scenario where an image dataset of industrial components is collected for a smart factory application, workers can begin annotating any defects in the components.
We propose the following categories to offer a comprehensive view of the data labeling landscape:
- Leveraging existing labels: One early concept in data labeling involves making use of any pre-existing labels. This is seen in semi-supervised learning, where the existing labels are utilized to predict the remaining labels.
- Crowd-based approaches: The subsequent set of techniques revolves around crowdsourcing. A basic method involves labeling individual examples. A more sophisticated approach is active learning, which carefully selects questions to ask.
- Weak labels: While aiming for perfect labels is ideal, it can be costly. An alternative approach is to generate less-than-perfect labels (known as weak labels) in larger quantities to compensate for their lower quality.
Table of Contents
- Utilizing Existing Datasets
- Crowd Based Techniques
- Weak Supervision
- Conclusion
- Frequently Asked Questions
Utilizing Existing Datasets
In the field of machine learning, a common scenario involves having a limited amount of labeled data, which can be costly and time-consuming to gather through human efforts. Alongside this labeled data, a significantly larger pool of unlabeled data exists.
Semi-supervised learning methods capitalize on both labeled and unlabeled data to make predictions. This approach can be employed in two learning settings: Transductive learning, where all the unlabeled data is accessible, and Inductive learning, where only a portion of the unlabeled data is available, and predictions are required for unseen data.
Within the realm of semi-supervised learning, there's a specific subset we're focusing on known as self-labeled techniques. In this subset, the primary objective is to generate more labels by relying on the model's own predictions.
While a comprehensive discussion is provided in the paper, we'll offer a brief overview here. Beyond the general techniques, there are also specialized graph-based label propagation methods tailored for data structured as graphs.
Classification
Semi-supervised learning techniques for classification aim to develop models that can assign one of multiple possible classes to each example using labeled and unlabeled datasets.
Figure: Classification Tasks Machine Learning
The techniques involved above can be categorized as follows:
Simple Approach
The simplest category involves training a single model using one learning algorithm on a specific set of features. For instance, Self-training initially trains a model on labeled examples and then utilizes it to predict unlabeled data.
Predictions are ranked by their confidence levels, and the most confident predictions are incorporated into the labeled examples. This process repeats iteratively until all unlabeled examples are labeled.
Multiple Classifiers
Another category trains multiple classifiers by sampling the training data multiple times. For example, Tri-training trains three models using ensemble learning and iteratively updates them.
Two models predict unlabeled examples and only the ones with matching predictions are used to re-train the model. Unlabeled examples are labeled using majority voting.
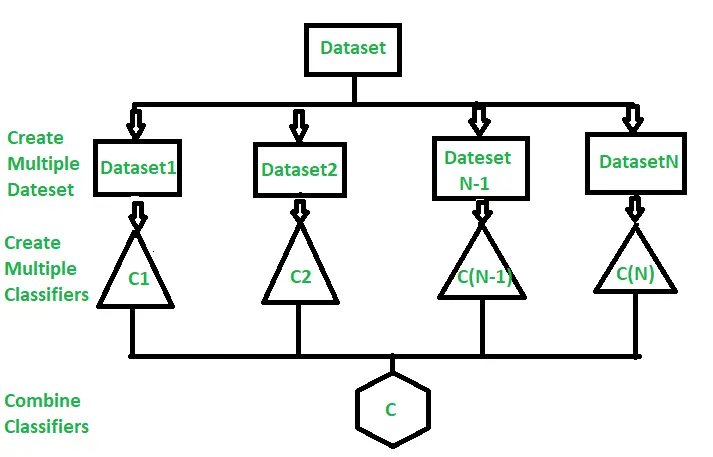
Figure: Learning Using Multiple Classifiers
Multiple Learning Algorithms
In this category, multiple learning algorithms are employed. Democratic Co-learning uses different algorithms (such as Naive Bayes, C4.5, and 3-nearest neighbor) to train separate classifiers on the same data.
Predictions from the classifiers are combined using weighted voting, and new labels are added to classifiers that deviate from majority predictions. This process continues until no more data is added to the classifier's training set.
Multiple Views
The final category uses multiple views or subsets of conditionally independent features given the class. For instance, Co-training divides features into two views, each sufficient for learning given the label. Models are trained on each view and then used to teach models trained on the other view.
Survey results show that these techniques yield similar accuracy when averaged across datasets. Accuracy measures the proportion of correct classifications made by the trained model.
However, not all techniques are universally applicable, as they may depend on specific conditions. For example, Co-training requires features that can be divided into two subsets, and Democratic Co-learning relies on three different learning algorithms.
Regression
There has been relatively less exploration of semi-supervised learning methods for regression, which involves training a model to predict real numbers based on an example. Coregularized least squares regression is an algorithm for least squares regression that follows the co-learning approach.
Figure: Predicting Best fit line using Regression
Another co-regularized framework employs sufficient and redundant views, similar to Co-training. Co-training regressors involve two k-nearest neighbor regressors using different distance metrics.
In each iteration, one regressor labels unlabeled data confidently predicted by the other. After iterations, the final prediction averages regression estimates from both regressors. These Co-training regressors can be extended using different base regressors.
Graph-based Label Propagation
Graph-based label propagation techniques also begin with a limited number of labeled examples, but they exploit the graph structure to infer labels for remaining examples based on their similarities.
For instance, if an image is labeled as a dog, similar images down the graph might also be labeled as dogs with some likelihood. The probability of label propagation decreases as the distance increases along the graph.
Graph-based label propagation finds applications in computer vision, information retrieval, social networks, and natural language processing. Zhu et al. introduced a semi-supervised learning approach based on a Gaussian random field model, forming a weighted graph from labeled and unlabeled examples.
The field's mean is described using harmonic functions and can be computed efficiently through matrix methods or belief propagation.
The MAD-Sketch algorithm was developed to reduce further the complexity of graph-based SSL algorithms using count-min sketching. This reduces the space and time complexities per node from O(m) to O(log m) under certain conditions, where m is the number of distinct labels.
Crowd Based Techniques
The most precise method for labeling examples involves manual efforts. An illustrative instance is the ImageNet image classification dataset, where Amazon Mechanical Turk was employed to categorize millions of images into a semantic hierarchy defined by WordNet.
Figure: Crowd-Sourced Data Labelling
However, creating datasets like ImageNet is a substantial undertaking that spans years, making it an impractical option for most machine learning applications. Historically, active learning has played a crucial role in the machine learning community by selecting specific examples for labeling, thus minimizing costs.
In recent times, crowdsourcing approaches for labeling have emerged, involving multiple workers who may not necessarily be experts in labeling.
This shift places greater importance on tasks assigned to workers, interface design, and ensuring high-quality labels. Contemporary commercial tools offer varied labeling services.
For instance, Amazon SageMaker supports active learning-based labeling, Google Cloud AutoML provides manual labeling, and Microsoft Custom Vision relies on user-provided labels.
While crowdsourced data labeling shares similarities with crowdsourced data acquisition, the techniques employed for each are distinct.
Active Learning
Active learning focuses on selecting the most intriguing unlabeled examples to present to workers for labeling. In this context, the workers are expected to be highly accurate, reducing the emphasis on interacting with those possessing less expertise.
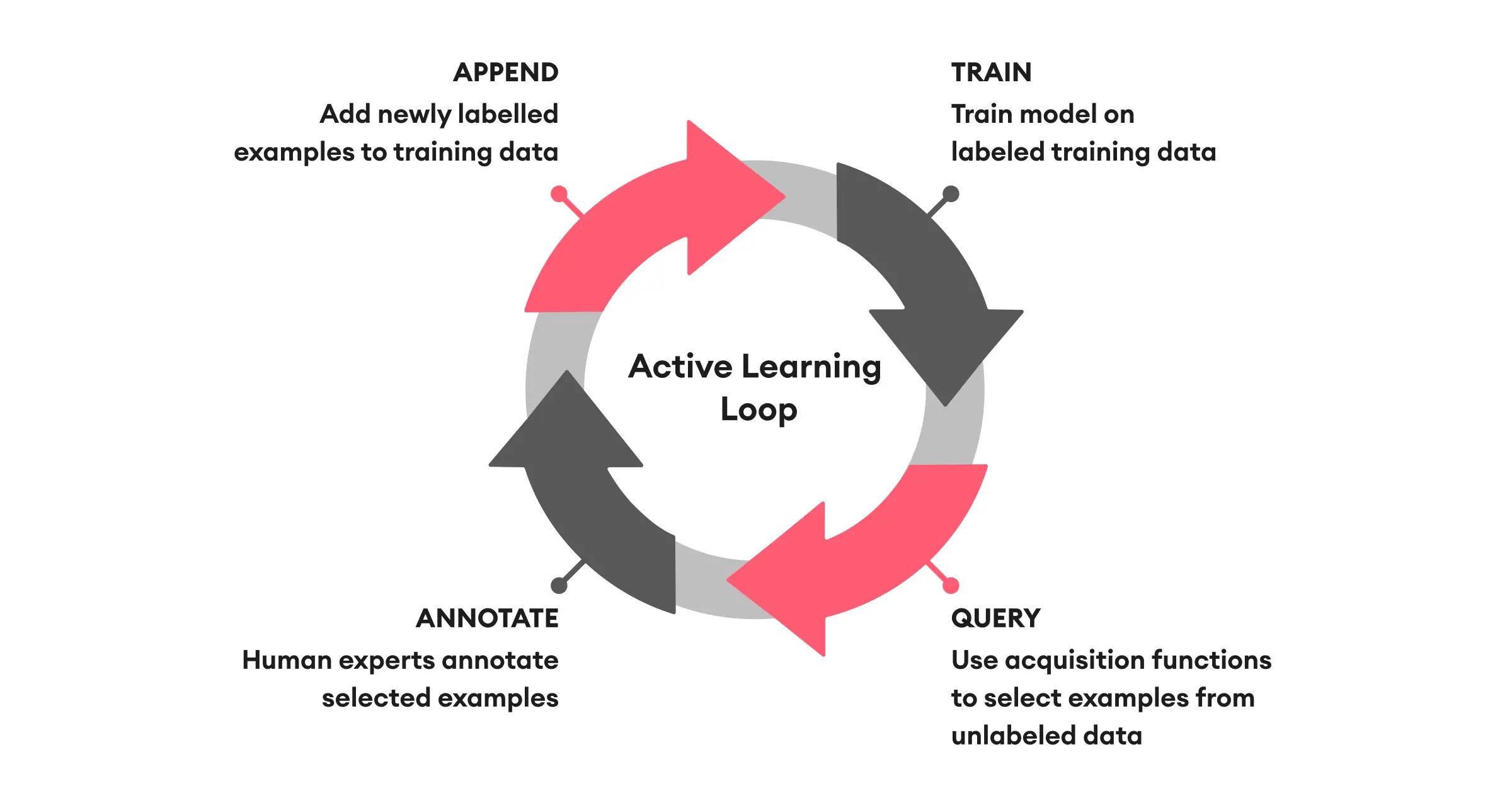
Figure: Active Learning Cycle
While some consider active learning as a subset of semi-supervised learning, the core distinction lies in the human involvement.
The primary challenge is effectively choosing examples to query within a limited budget. A drawback of active learning is that the training algorithm influences the chosen examples and is not reusable. Active learning contains various techniques and here we cover the most notable techniques.
Uncertainty Sampling
The simplest approach, Uncertainty Sampling, selects the next unlabeled example where the model prediction is most uncertain. For binary classification, it chooses examples closest to a probability of 0.5.
Margin Sampling improves this by selecting the example with the largest difference between the most and second-most probable labels. Entropy can be used as a more generalized uncertainty measure, quantifying the information needed to encode a distribution.
Query-by-Committee
Uncertainty Sampling is extended by Query-by-Committee, which trains a committee of models on the same labeled data. Each model votes on labeling each example, and the most informative example is where the most models disagree.
This minimizes the "version space," encompassing all possible classifiers consistent with labeled data. Query-by-bagging is a variant employing bagging as an ensemble learning algorithm. The optimal number of models is application-specific and not universally agreed upon.
Decision-Theoretic Approaches
Another active learning approach uses decision theory, aiming to optimize specific objectives. These objectives include maximizing estimated model accuracy or reducing generalization error. Each example to label is chosen by minimizing the estimated error rate.
Regression
Active learning techniques can also be extended to regression problems. Uncertainty Sampling focuses on the output variance of predictions. Query-by-Committee in regression selects examples where the variance among committee predictions is highest, which is effective when model bias is low and resistant to overfitting.
Combining Self and Active Learning
Self-labeled and active learning techniques can be used together. They address opposing problems: self-labeled techniques find highly confident predictions and add them to labeled examples, while active learning identifies low-confidence predictions for manual labeling. The two techniques have been historically used together, with various methods for combining them.
For example, McCallum and Nigam improve Query-By-Committee and combine it with Expectation-Maximization (EM) for semi-supervised learning.
Tomanek and Hahn propose semi-supervised active learning (SeSAL) for sequence labeling tasks. Zhou et al. present semi-supervised active image retrieval (SSAIR) for image retrieval. Zhu et al. combine semi-supervised and active learning under a Gaussian random field model.
In this context, labeled and unlabeled examples are represented as vertices in a graph, and active learning is followed by semi-supervised learning.
Crowd Sourcing
Contrasting active learning, crowdsourcing techniques focus here on orchestrating tasks involving numerous workers who might not possess labeling expertise.
This approach acknowledges the potential for worker errors, resulting in an extensive body of literature addressing issues such as enhancing worker interaction, evaluating worker reliability, mitigating potential biases, and aggregating labeling results while resolving ambiguities.
User Interaction
Effective communication of labeling instructions to workers poses a significant challenge. The conventional method involves providing initial guidelines to workers and relying on their best efforts to adhere. Yet, these instructions often prove incomplete and do not encompass all potential scenarios, leaving workers uncertain.
Revolt tackles this by employing collaborative crowdsourcing. Workers progress through three phases: Voting, where workers cast votes akin to traditional labeling; Explaining, where workers justify their labeling rationale; and Categorizing, where workers assess explanations from peers and tag conflicting labels. This information can then inform post-hoc judgments on label decision boundaries.
Enhanced tools to aid workers in organizing evolving concepts have also been explored. Tailoring the labeling interface to each application is crucial for worker performance, though the challenge stems from different applications requiring distinct interfaces.
Quality Control
Maintaining the quality of crowd-contributed labeling is paramount due to the potential variance in worker abilities. While a straightforward approach involves multiple workers labeling the same example and employing majority voting, more sophisticated strategies exist.
Scalability
The challenge of scaling up crowdsourced labeling is significant. Though traditional active learning techniques initially addressed this, recent efforts have further applied systems techniques to scale algorithms for larger datasets. Mozafari et al. propose parallelizable active learning algorithms.
One algorithm (Uncertainty) selects the current classifier's most uncertain examples, while a more advanced algorithm (MinExpError) combines the model's accuracy with uncertainty. These algorithms employ bootstrap theory for wide applicability and support embarrassingly parallel processing.
Regression
In comparison to crowdsourcing for classification tasks, less attention has been given to regression tasks. Marcus et al. address selectivity estimation in crowdsourced databases, focusing on estimating the proportion of records satisfying specific properties by posing questions to workers.
Weak Supervision
As machine learning is used in more and more areas, there often isn't enough labeled data available for training. For instance, new products might not have labels to teach quality control systems in places like smart factories.
To tackle this, weak supervision methods have gained popularity. These methods help generate a lot of labels, even if they're not as precise as manual ones. They're still good enough for training models to do a decent job.
This is especially useful when there's a lot of data and labeling everything by hand is too hard. In the upcoming sections, we'll talk about the new idea of data programming and how to extract facts from data.
Data Programming
With the increasing importance of labeling large amounts of data, especially for deep learning applications, a solution called data programming has been introduced. Data programming aims to generate a lot of weak labels by using multiple labeling functions instead of individual ones.
Labeling functions are like computer programs that generate labels for data. For instance, a labeling function might check for positive words in a tweet to determine if it's positive. Since a single labeling function might not be very accurate on its own, multiple functions are combined into a generative model.
This model is then used to create weak labels that are reasonably good in quality. Snorkel is a popular system that implements data programming and is used in various industries.
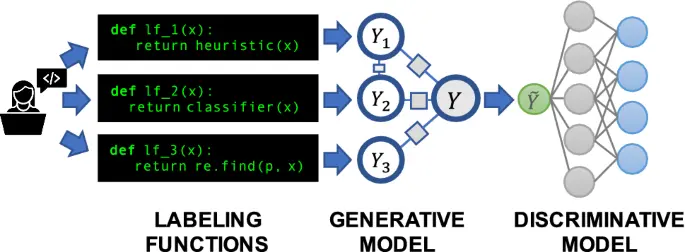
Figure: Snorkel-Based Learning with Weak Supervision
The power of data programming comes from its way of combining these labeling functions. Instead of simply majority voting, it uses a more advanced approach. Functions that are highly correlated with each other have less influence on the final label prediction. It also reduces the impact of outlier functions that don't work well.
Theoretically, if the labeling functions are fairly accurate, the generative model's predictions will become very close to the true labels.
Fact Extraction
Another way to create weak labels is through fact extraction. Knowledge bases contain facts that are extracted from various sources, including the Internet.
A fact could be information about an entity's attribute, like "Germany's capital is Berlin." These facts can be considered positive examples and used as starting points for generating weak labels.
Fact extraction is a part of information extraction, where the goal is to gather structured data from the web. This process has evolved over time from early efforts like RoadRunner and KnowItAll, which used techniques like comparison and extraction rules.
When it comes to knowledge bases, precision is crucial. If accuracy is very important, manual curation, like in Freebase and Google Knowledge Graph, is used. Otherwise, extraction methods vary based on the data source.
Systems like YAGO, Ollie, ReVerb, and ReNoun apply patterns to web text to extract facts. Knowledge Vault takes data from text, tables, page structure, and human annotations. Biperpedia focuses on extracting attributes of entities from queries and web text.
The Never-Ending Language Learner (NELL) is a system that continuously extracts structured information from the web to build a knowledge base of entities and relationships.
NELL starts with a seed ontology containing classes of entities (e.g., person, fruit) and their relationships (e.g., athlete plays on team). It scans millions of web pages, identifying new entities and relationships by matching patterns in surrounding phrases.
These newly gathered facts become training data to find even more patterns. NELL has been collecting facts since 2010, and its techniques are similar to distant supervision, creating weak labels for learning.
Conclusion
In conclusion, the process of data labeling plays a pivotal role in preparing datasets for machine learning tasks.
This becomes especially crucial when dealing with scenarios like the smart factory application, where accurate identification of industrial component defects requires meticulous labeling. While data labeling often goes hand in hand with data acquisition, it's important to distinguish between the two due to their distinct techniques.
Our exploration of data labeling techniques reveals several categories that provide a comprehensive view of the landscape:
- Leveraging Existing Labels: One approach involves utilizing pre-existing labels in semi-supervised learning to predict remaining labels.
- Crowd-Based Approaches: Crowdsourcing has emerged as a way to label data, ranging from basic labeling by individuals to more advanced active learning strategies that carefully select questions to ask workers.
- Weak Labels: The challenge of acquiring perfect labels can be mitigated by generating weaker labels in larger quantities. This approach becomes crucial in situations where perfect labeling is costly or time-consuming.
The study of utilizing existing datasets delves into the realm of semi-supervised learning, specifically self-labeled techniques. The focus shifts to classification and regression tasks, with various methods categorized into simple approaches, multiple classifiers, multiple learning algorithms, and multiple views.
Graph-based label propagation techniques enable inferring labels for unlabeled examples by exploiting the graph structure's inherent similarities. This approach finds applications across various domains, including computer vision and natural language processing.
Crowd-based techniques, particularly active learning, have evolved as a method to efficiently label examples by selecting intriguing instances for human annotation. The challenge lies in optimal example selection within limited resources, where techniques like Uncertainty Sampling, Query-by-Committee, and decision-theoretic approaches have been developed.
Combining self-labeled and active learning techniques proves effective in addressing different labeling challenges. This approach, along with strategies for user interaction, quality control, and scalability, contributes to enhancing the efficiency and reliability of crowdsourced labeling.
Weak supervision emerges as a powerful solution to address the scarcity of manually labeled data. Methods such as data programming and fact extraction introduce innovative ways to generate weak labels using labeling functions and extracted facts from knowledge bases, significantly broadening the possibilities for training machine learning models even in scenarios with limited labeled data.
Data labeling techniques are essential for bridging the gap between raw data and meaningful insights, paving the way for the effective training of machine learning models across various domains and applications.
The diverse array of approaches discussed in this exploration highlights the dynamic nature of data labeling as researchers and practitioners continue to develop innovative strategies to tackle labeling challenges in an ever-evolving landscape of machine learning and data analysis.
Frequently Asked Questions
1. What is the significance of leveraging existing labels in data labeling?
Leveraging existing labels is crucial in scenarios where labeled data is limited. Semi-supervised learning techniques utilize pre-existing labels to predict the remaining labels, enhancing the efficiency of labeling efforts.
This approach helps in scenarios where labeling new data from scratch might be time-consuming or expensive. Methods like self-training and co-training fall under this category and involve iteratively incorporating model predictions into the labeled dataset.
2. How can crowdsourcing be used for data labeling, and what challenges does it pose?
Crowdsourcing involves outsourcing labeling tasks to multiple workers, often through platforms like Amazon Mechanical Turk.
While it is a cost-effective way to label data, it poses challenges like ensuring label quality, worker reliability, and task assignment. Techniques like active learning have emerged to select instances for human labeling intelligently, and tools like
Revolt has been developed to improve worker interaction and reduce uncertainty. Quality control methods like majority voting and identifying low-quality workers are crucial in addressing these challenges.
3. What are weak labels, and why are they gaining popularity?
Weak labels are labels that may not be perfect but are still useful for training machine learning models. They are gaining popularity because acquiring perfect labels can be time-consuming and expensive.
Weak supervision techniques, such as data programming and fact extraction, generate a large number of weak labels using multiple labeling functions or extracted facts from knowledge bases. These weak labels are effective for training models, especially when there's a scarcity of manually labeled data.
4. How does data programming work, and how is it beneficial for data labeling?
Data programming is a technique that aims to generate weak labels by combining multiple labeling functions. Instead of relying on individual labeling functions, data programming uses a generative model that considers correlations between labeling functions.
This approach reduces the impact of noisy or outlier functions, resulting in reasonably accurate weak labels. Data programming is beneficial for labeling large amounts of data quickly and efficiently, especially in scenarios where manually labeled data is limited.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
