

Benchmark datasets from CVPR 2022 worth your time-Part 2


Are you someone who deals with datasets every new day and are always looking for a new variety of datasets? If you are a data enthusiast, then CVPR ( IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR)) is something that is extremely important for you. Recently, they have published a list of worth reading benchmark datasets that might be of your interest if you are related to the Computer Vision industry.
Here we have listed some of the top computer vision datasets that might be of use to you.
(To read the part 1 of this list click here)
6. Object Localization Under Single Coarse Point Supervision
Author: Xuehui Yu, Pengfei Chen, Di wu, Najmul Hassan, Guorong Li, Junchi Yan, Humphrey Shi, Qixiang Ye, Zhenjun Han
The increased interest has been shown in point-based object localization (POL), which seeks to combine low-cost data annotation with high-performance object sensing. However, due to the inconsistent nature of the annotated points, the point annotation mode inevitably produces semantic variance. Existing POL techniques rely significantly on precise but challenging-to-define key-point annotations. In this article, we provide a POL approach that relaxes the supervision signals from precise key points to freely spotted points while employing coarse point annotations.
To achieve this, we suggest a coarse point refinement (CPR) method, which, to the best of our knowledge, is the first effort to reduce semantic variance from an algorithmic standpoint. Through multiple-instance learning, CPR builds point bags, chooses semantically linked points, and generates semantic center points (MIL). By defining a weakly supervised evolution technique in this manner, CPR ensures that a high-performance object localizer may be trained with only coarse point supervision. The effectiveness of the CPR technique has been validated by experimental findings on the COCO, DOTA, and our planned SeaPerson dataset.
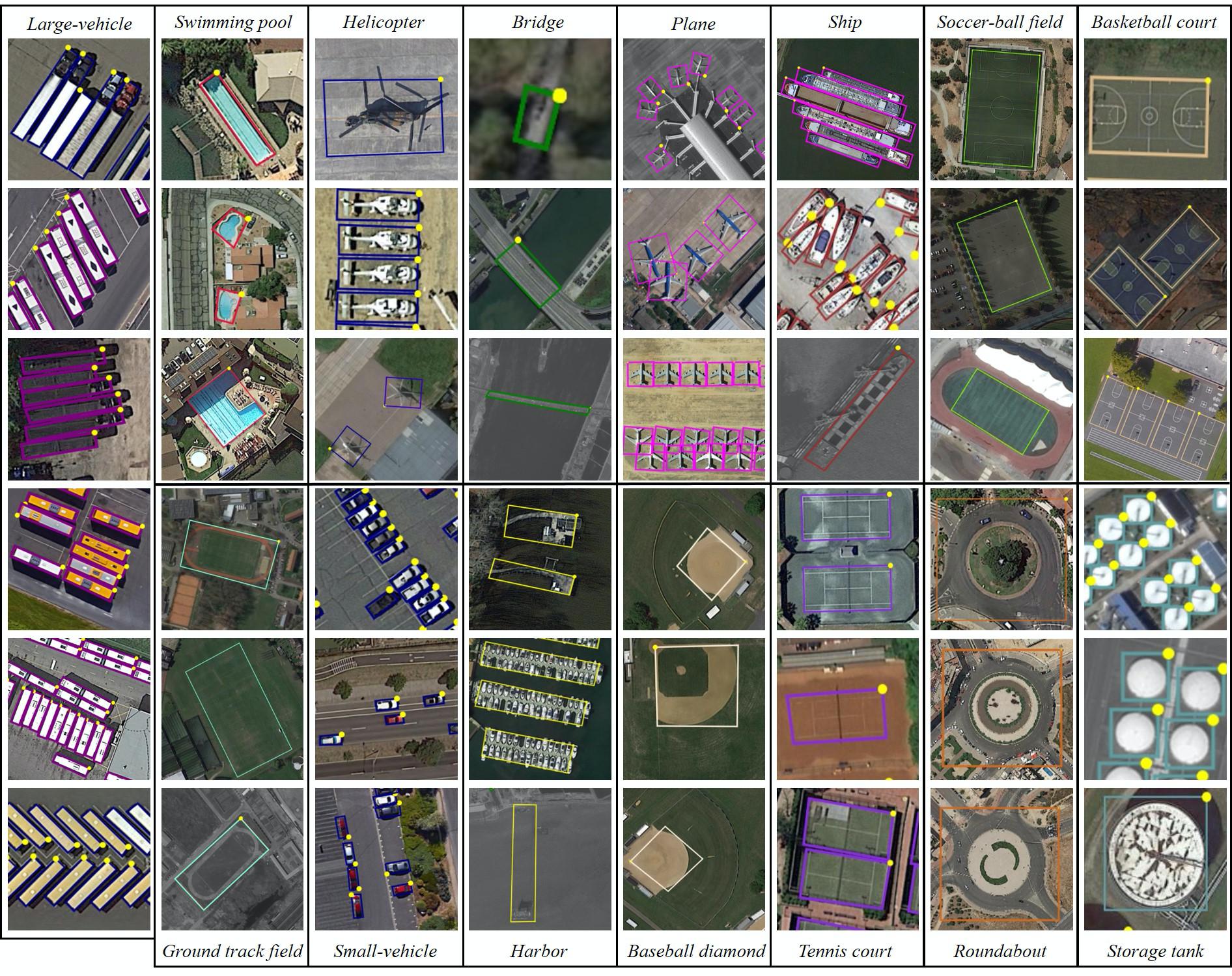
The dataset:
The dataset has annotations for
- object detection: bounding boxes and per-instance segmentation masks with 80 object categories,
- captioning: natural language descriptions of the images (see MS COCO Captions),
- keypoints detection: containing more than 200,000 images and 250,000 person instances labeled with key points (17 possible key points, such as left eye, nose, right hip, right ankle),
- stuff image segmentation – per-pixel segmentation masks with 91 stuff categories, such as grass, wall, sky (see MS COCO Stuff),
- panoptic: full scene segmentation, with 80 thing categories (such as a person, bicycle, elephant) and a subset of 91 stuff categories (grass, sky, road),
- dense pose: more than 39,000 images and 56,000 person instances labeled with DensePose annotations – each labeled person is annotated with an instance id and a mapping between image pixels that belong to that person's body and a template 3D model. The annotations are publicly available only for training and validation images.
DOTA is a large-scale dataset for object detection in aerial images. It can be used to develop and evaluate object detectors in aerial images. The images are collected from different sensors and platforms. Each image is of size in the range from 800 × 800 to 20,000 × 20,000 pixels and contains objects exhibiting a wide variety of scales, orientations, and shapes. The instances in DOTA images are annotated by experts in aerial image interpretation by arbitrary (8 d.o.f.) quadrilateral. We will continue to update DOTA, to grow in size and scope to reflect evolving real-world conditions. Now it has three versions:
DOTA-v1.0 contains 15 common categories, 2,806 images and 188, 282 instances. The proportions of the training set, validation set, and testing set in DOTA-v1.0 are 1/2, 1/6, and 1/3, respectively.
DOTA-v1.5 uses the same images as DOTA-v1.0, but the extremely small instances (less than 10 pixels) are also annotated. Moreover, a new category, ”container crane” is added. It contains 403,318 instances in total. The number of images and dataset splits are the same as DOTA-v1.0. This version was released for the DOAI Challenge 2019 on Object Detection in Aerial Images in conjunction with IEEE CVPR 2019.
DOTA-v2.0 collects more Google Earth, GF-2 Satellite, and aerial images. There are 18 common categories, 11,268 images and 1,793,658 instances in DOTA-v2.0. Compared to DOTA-v1.5, it further adds the new categories of ”airport” and ”helipad”. The 11,268 images of DOTA are split into training, validation, test-dev, and test-challenge sets. To avoid the problem of overfitting, the proportion of the training and validation set is smaller than the test set. Furthermore, we have two test sets, namely test-dev and test-challenge. Training contains 1,830 images and 268,627 instances. Validation contains 593 images and 81,048 instances. We released the images and ground truths for training and validation sets. Test-dev contains 2,792 images and 353,346 instances. We released the images but not the ground truths. Test-challenge contains 6,053 images and 1,090,637 instances.
TinyPerson is a benchmark for tiny object detection in a long distance and with massive backgrounds. The images in TinyPerson are collected from the Internet. First, videos with high resolution are collected from different websites. Second, images from the video are sampled every 50 frames. Then images with a certain repetition (homogeneity) are deleted, and the resulting images are annotated with 72,651 objects with bounding boxes by hand.
You can download the data from here
Related Paper for your Reference
MnasFPN: Learning Latency-aware Pyramid Architecture for Object Detection on Mobile Devices published on CVPR 2020 by Bo Chen, Golnaz Ghiasi, Hanxiao Liu, Tsung-Yi Lin, Dmitry Kalenichenko, Hartwig Adams, Quoc V. Le
Gliding vertex on the horizontal bounding box for multi-oriented object detection Published by Yongchao Xu, Mingtao Fu, Qimeng Wang, Yukang Wang, Kai Chen, Gui-Song Xia, Xiang Bai
Object Localization under Single Coarse Point Supervision published on CVPR 2022 by Xuehui Yu, Pengfei Chen, Di wu, Najmul Hassan, Guorong Li, Junchi Yan, Humphrey Shi, Qixiang Ye, Zhenjun Han
RFLA: Gaussian Receptive Field based Label Assignment for Tiny Object Detection Published by Chang Xu, Jinwang Wang, Wen Yang, Huai Yu, Lei Yu, Gui-Song Xia
7. Learning Program Representations for Food Images and Cooking Recipes
Author: Dim P. Papadopoulos, Enrique Mora, Nadiia Chepurko, Kuan Wei Huang, Ferda Ofili, Antonio Torralba
In this research, they were interested in modelling a cooking recipe or any how-to instructional technique with a rich and relevant high-level representation. In particular, they suggested presenting food pictures and cooking instructions as cookery programmes. Programs offer a systematic representation of the task, graphing the semantics of cooking and the orderly linkages between operations. This makes it simple for users to control them and for agents to carry them out. In order to achieve this, they developed a model trained to jointly construct a programme from a succession of recipes and food images embedded together.
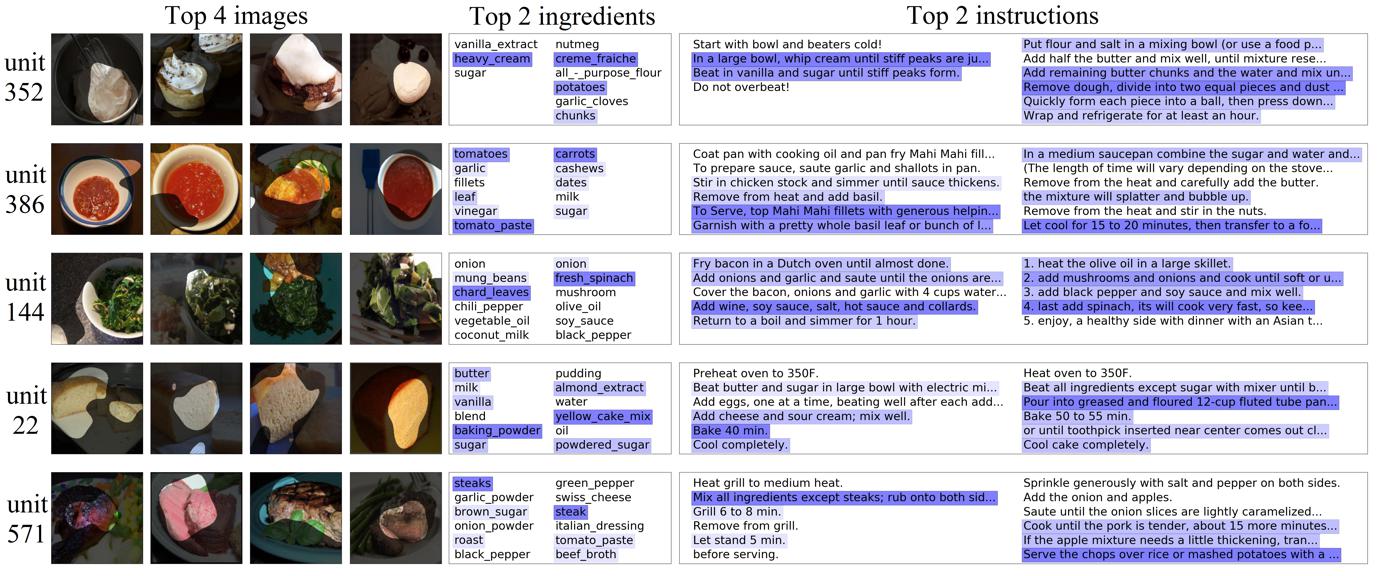
The dataset:
Recipe1M+ is a dataset which contains one million structured cooking recipes with 13M associated images.
You can download the dataset from here
Related Paper for your Reference
A Large-Scale Benchmark for Food Image Segmentation published by Xiongwei Wu, Xin Fu, Ying Liu, Ee-Peng Lim, Steven C. H. Hoi, Qianru Sun
Revamping Cross-Modal Recipe Retrieval with Hierarchical Transformers and Self-supervised Learning published on CVPR 2021 by Amaia Salvador, Erhan Gundogdu, Loris Bazzani, Michael Donoser
KitcheNette: Predicting and Recommending Food Ingredient Pairings using Siamese Neural Networks published by Donghyeon Park, Keonwoo Kim, Yonggyu Park, Jungwoon Shin, Jaewoo Kang
Cross-Modal Retrieval in the Cooking Context: Learning Semantic Text-Image Embeddings published by Micael Carvalho, Rémi Cadène, David Picard, Laure Soulier, Nicolas Thome, Matthieu Cord ·
8. Exploring Endogenous Shift for Cross-Domain Detection: A Large-Scale Benchmark and Perturbation Suppression Network
Author: Renshuai Tao, Hainan Li, Tianbo Wang, Yanlu Wei, Yifu Ding, Bowie Jin, Hongping Zhi, Xianglong Liu, Aishan Liu
Cross-domain detection techniques currently in use mainly focus on domain shifts, where variations between domains are frequently brought about by the external environment and are therefore perceptible to humans. However, there is still a sort of shift known as the endogenous shift that occurs in real-world situations (such as MRI medical diagnosis and X-ray security inspection), when the variations between domains are mainly brought on by internal causes and are typically subtle.
Although it hasn't been extensively researched, this shift can also seriously impair cross-domain detection performance. We provide the first Endogenous Domain Shift (EDS) benchmark, X-ray security inspection, as a contribution to this work. The endogenous shifts among the domains are mainly brought on by various X-ray machine types with various hardware characteristics, wear levels, etc. With bounding-box annotations from 10 categories, EDS consists of 14,219 images, containing 31,654 common cases from three domains (X-ray machines). We also introduce the Perturbation Suppression Network (PSN), which was inspired by the fact that the category-dependent and category-independent perturbations are the main causes of the endogenous shift.
You can download the dataset from here
9. DanceTrack: Multi-Object Tracking in Uniform Appearance and Diverse Motion
Author: Peize Sun, Jinkun Cao, Yi Jiang, Zehuan Yuan, Song Bai, Kris Kitani, Ping Luo
A detector is typically used for object localisation in a multi-object tracking (MOT) pipeline, with re-identification (re-ID) coming next for object association. This pipeline is largely inspired by recent developments in object detection and re-ID as well as biases in the tracking datasets that are currently in use, where the majority of objects tend to have distinctive appearances and re-ID models are sufficient for building connections. In response to this prejudice, we would want to underline once more that multi-object tracking techniques should be effective even in the absence of strong object discrimination. In order to achieve this, we suggest a sizable dataset for tracking multiple people who have similar appearances, varied motions, and severe articulation. We call the dataset "DanceTrack" because it primarily consists of group dance footage.
They have anticipated that DanceTrack will offer a better framework for the creation of additional MOT algorithms that rely more on motion analysis and less on visual discrimination. They have assessed the performance of many cutting-edge trackers against current benchmarks using our dataset, and we find that DanceTrack suffers noticeably.
The dataset:
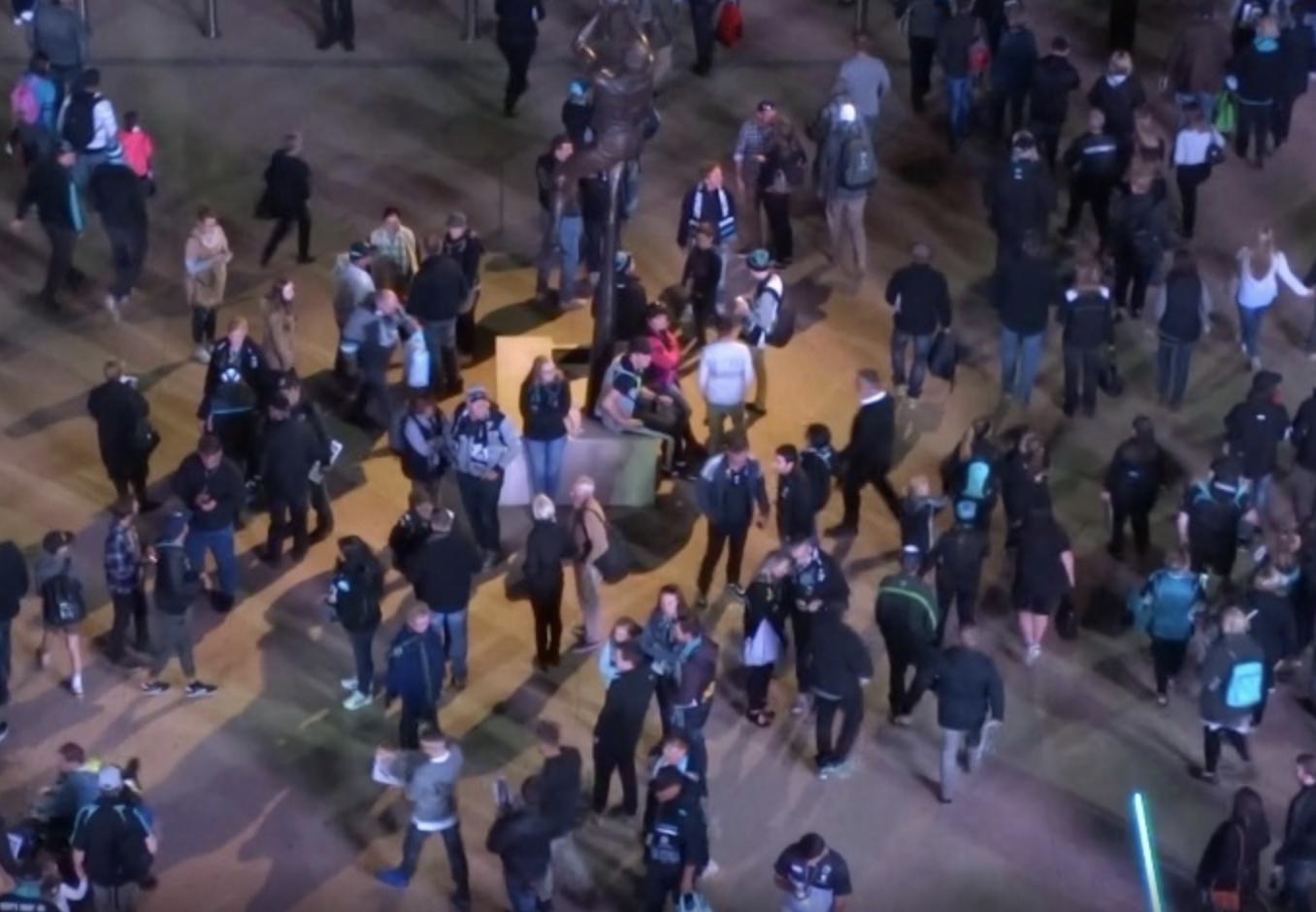
A large-scale multi-object tracking dataset for human tracking in occlusion, frequent crossover, uniform appearance and diverse body gestures. It is proposed to emphasize the importance of motion analysis in multi-object tracking instead of the mainly appearance-matching-based diagrams.
The MOTChallenge datasets are designed for the task of multiple object tracking. There are several variants of the dataset released each year, such as MOT15, MOT17, and MOT20.
You can download the dataset from here
Related Paper for your Reference
FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking Published by Yifu Zhang, Chunyu Wang, Xinggang Wang, Wen-Jun Zeng, Wenyu Liu
ByteTrack: Multi-Object Tracking by Associating Every Detection Box Published on arXiv 2021 by Yifu Zhang, Peize Sun, Yi Jiang, Dongdong Yu, Fucheng Weng, Zehuan Yuan, Ping Luo, Wenyu Liu, Xinggang Wang
MOT16: A Benchmark for Multi-Object Tracking published by Anton Milan, Laura Leal-Taixe, Ian Reid, Stefan Roth, Konrad Schindler
Simple Online and Realtime Tracking with a Deep Association Metric published by Nicolai Wojke, Alex Bewley, Dietrich Paulus
10. Bongard-HOI: Benchmarking Few-Shot Visual Reasoning for Human-Object Interactions
Author: Jiang et al.

A significant gap remains between today's visual pattern recognition models and human-level visual cognition especially when it comes to few-shot learning and compositional reasoning of novel concepts. They have introduced Bongard-HOI, a new visual reasoning benchmark that focuses on compositional learning of human-object interactions (HOIs) from natural images. It is inspired by two desirable characteristics from the classical Bongard problems (BPs): 1) few-shot concept learning, and 2) context-dependent reasoning. They have carefully curated the few-shot instances with hard negatives, where positive and negative images only disagree on action labels, making mere recognition of object categories insufficient to complete our benchmarks.
They have also designed multiple test sets to systematically study the generalization of visual learning models, where we vary the overlap of the HOI concepts between the training and test sets of few-shot instances, from partial to no overlaps. Bongard-HOI presents a substantial challenge to today's visual recognition models. The state-of-the-art HOI detection model achieves only 62% accuracy on few-shot binary prediction while even amateur human testers on MTurk have 91% accuracy. With the Bongard-HOI benchmark, we hope to further advance research efforts in visual reasoning, especially in holistic perception-reasoning systems and better representation learning.
The dataset:
Bongard-HOI testifies to which extent your few-shot visual learner can quickly induce the true HOI concept from a handful of images and perform reasoning with it. Further, the learner is also expected to transfer the learned few-shot skills to novel HOI concepts compositionally.
The ImageNet dataset contains 14,197,122 annotated images according to the WordNet hierarchy. Since 2010 the dataset is used in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), a benchmark in image classification and object detection.
The MS COCO (Microsoft Common Objects in Context) dataset is a large-scale object detection, segmentation, key-point detection, and captioning dataset. The dataset consists of 328K images.
Splits: The first version of the MS COCO dataset was released in 2014. It contains 164K images split into training (83K), validation (41K) and test (41K) sets. In 2015 additional test set of 81K images was released, including all the previous test images and 40K new images.
Based on community feedback, in 2017 the training/validation split was changed from 83K/41K to 118K/5K. The new split uses the same images and annotations. The 2017 test set is a subset of 41K images of the 2015 test set. Additionally, the 2017 release contains a new unannotated dataset of 123K images.
mini-Imagenet is proposed by Matching Networks for One Shot Learning. In NeurIPS, 2016. This dataset consists of 50000 training images and 10000 testing images, evenly distributed across 100 classes.
Verbs in COCO (V-COCO) is a dataset that builds off COCO for human-object interaction detection. V-COCO provides 10,346 images (2,533 for training, 2,867 for validating and 4,946 for testing) and 16,199 person instances. Each person has annotations for 29 action categories and there are no interaction labels including objects.
The Meta-Dataset benchmark is a large few-shot learning benchmark and consists of multiple datasets of different data distributions. It does not restrict few-shot tasks to have fixed ways and shots, thus representing a more realistic scenario. It consists of 10 datasets from diverse domains:
ILSVRC-2012 (the ImageNet dataset, consisting of natural images with 1000 categories)
- Omniglot (hand-written characters, 1623 classes)
- Aircraft (dataset of aircraft images, 100 classes)
- CUB-200-2011 (dataset of Birds, 200 classes)
- Describable Textures (different kinds of texture images with 43 categories)
- Quick Draw (black and white sketches of 345 different categories)
- Fungi (a large dataset of mushrooms with 1500 categories)
- VGG Flower (dataset of flower images with 102 categories),
- Traffic Signs (German traffic sign images with 43 classes)
- MSCOCO (images collected from Flickr, 80 classes).
You can download this dataset from here
Related Paper for your Reference
Bongard-HOI: Benchmarking Few-Shot Visual Reasoning for Human-Object Interactions published on CVPR 2022 by Huaizu Jiang, Xiaojian Ma, Weili Nie, Zhiding Yu, Yuke Zhu, Anima Anandkumar
Torchmeta: A Meta-Learning library for PyTorch published by Tristan Deleu, Tobias Würfl, Mandana Samiei, Joseph Paul Cohen, Yoshua Bengio
HAKE: Human Activity Knowledge Engine published by Yong-Lu Li, Liang Xu, Xinpeng Liu, Xijie Huang, Yue Xu, Mingyang Chen, Ze Ma, Shiyi Wang, Hao-Shu Fang, Cewu Lu
iCAN: Instance-Centric Attention Network for Human-Object Interaction Detection published by Chen Gao, Yuliang Zou, Jia-Bin Huang ·
Click here for the 1st part of benchmark datasets from CVPR 2022!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
