

Benchmark datasets from CVPR 2022 worth your time-Part 1


Are you someone who deals with datasets every new day and are always looking for a new variety of datasets? If you are a data enthusiast, then CVPR (IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR)) is something that is extremely important for you. Recently, they have published a list of worth reading benchmark datasets that might be of your interest if you are related to the Computer Vision industry.
Here we have listed some of the top computer vision datasets that might be of use to you.
1. Focal Loss for Dense Object Detection
Author: Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, Piotr Dollár
In a two-stage process popularised by R-CNN, a classifier is applied to a sparse set of potential object locations to create the highest accuracy object detectors to date. One-stage detectors, on the other hand, have the ability to be faster and simpler but have so far lagged behind the precision of two-stage detectors when used across a regular, dense sampling of putative object locations. In this essay, they look into the reasons for this. They have found that the primary culprit is the severe foreground-background class imbalance experienced during the training of dense detectors.
By altering the conventional cross-entropy loss so that it devalues the loss attributed to examples with clear classifications, we propose to correct this class imbalance. Their innovative Focal Loss method protects the detector from being overloaded with easy negatives during training by concentrating training on a small number of hard examples. They have created and trained a straightforward dense detector we call RetinaNet to assess the efficacy of our loss. Their findings demonstrate that RetinaNet can match the speed of earlier one-stage detectors while outperforming all current state-of-the-art two-stage detectors in terms of accuracy when trained with the focus loss.
The dataset:
Extended GTEA Gaze+, EGTEA Gaze+ is a large-scale dataset for FPV actions and gaze. It subsumes GTEA Gaze+ and comes with HD videos (1280x960), audio, gaze tracking data, frame-level action annotations, and pixel-level hand masks at sampled frames. Specifically, EGTEA Gaze+ contains 28 hours (de-identified) of cooking activities from 86 unique sessions of 32 subjects. These videos come with audio and gaze tracking (30Hz). We have further provided human annotations of actions (human-object interactions) and hand masks.
The action annotations include 10325 instances of fine-grained actions, such as "Cut bell pepper" or "Pour condiment (from) condiment container into salad".
The hand annotations consist of 15,176 hand masks from 13,847 frames from the videos.
The Car Parking Lot Dataset (CARPK) contains nearly 90,000 cars from 4 different parking lots collected by means of drones (PHANTOM 3 PROFESSIONAL). The images are collected with the drone view at approximately 40 meters in height. The image set is annotated by a bounding box per car. All labeled bounding boxes have been well recorded with the top-left points and the bottom-right points. It is supporting object counting, object localizing, and further investigations with the annotation format in bounding boxes.
The Sku110k dataset provides 11,762 images with more than 1.7 million annotated bounding boxes captured in densely packed scenarios, including 8,233 images for training, 588 images for validation, and 2,941 images for testing. There are around 1,733,678 instances in total. The images are collected from thousands of supermarket stores and are of various scales, viewing angles, lighting conditions, and noise levels. All the images are resized to a resolution of one megapixel. Most of the instances in the dataset are tightly packed and typically of a certain orientation in the range of [−15∘, 15∘].
TJU-DHD is a high-resolution dataset for object detection and pedestrian detection. The dataset contains 115,354 high-resolution images (52% of images have a resolution of 1624×1200 pixels and 48% of images have a resolution of at least 2,560×1,440 pixels) and 709,330 labelled objects in total with a large variance in scale and appearance.
You can download the dataset from here
Related Paper for your Reference
Joint Hand Motion and Interaction Hotspots Prediction From Egocentric Videos by Author: Shaowei Liu, Subarna Tripathi, Somdeb Majumdar, Xiaolong Wang
Class-Balanced Loss Based on Effective Number of Samples published on CVPR 2019 by Yin Cui, Menglin Jia, Tsung-Yi Lin, Yang song, Serge Belongie ·
Large-scale weakly-supervised pre-training for video action recognition published on CVPR 2019 by Deepti Ghadiyaram, Matt Feiszli, Du Tran, Xueting Yan, Heng Wang, Dhruv Mahajan
Temporal Pyramid Network for Action Recognition published on CVPR 2020 by Ceyuan Yang, Yinghao Xu, Jianping Shi, Bo Dai, Bolei Zhou
2. Universal Photometric Stereo Network Using Global Lighting Contexts
Author: Satoshi Ikehata
This work addresses the universal photometric stereo problem, a novel photometric stereo task. The solution algorithm for this challenge is intended to operate for objects with a variety of shapes and substances under arbitrary lighting fluctuations without presuming any specific models, in contrast to earlier problems that relied on specific physical lighting models, severely limiting their usability. We describe a totally data-driven approach to tackle this exceedingly difficult issue, which replaces the restoration of physical lighting variables with the retrieval of the generic lighting depiction known as global lighting contexts, eliminating the previous assumption of lighting.
They wisely recovered surface normal vectors using them as lighting factors in a calibrated photometric stereo network. Our network is trained on a novel synthetic dataset that simulates the look of items in the wild in order to adapt it to a wide range of shapes, materials, and lighting. On the basis of our test results, their approach is contrasted with other cutting-edge uncalibrated photometric stereo approaches to show the value of our approach.
3. PTTR: Relational 3D Point Cloud Object Tracking With Transformer
Author: Changqing Zhou, Zhipeng Luo, Yueru Luo, Tianrui Liu, Liang Pan, Zhongang Cai, Haiyu Zhao, Shijian Lu
3D object tracking in a point cloud sequence seeks to forecast an object's position and orientation in the main search point cloud from a template point cloud. They have presented Point Tracking TRansformer (PTTR), which effectively anticipates high-quality 3D tracking outcomes in a coarse-to-fine way with the use of transformer operations, inspired by the success of transformers. There are three original designs in PTTR. 1) Relation-Aware Sampling is a design alternative to random sampling that preserves information pertinent to provided templates during subsampling. 2) In addition, we suggest a Point Relation Transformer (PRT) made up of cross- and self-attention modules.
The search region and the template, respectively, benefit from enhanced encoded point features due to the worldwide self-attention operation that captures long-range relationships. Then, using cross-attention, they matched the two sets of feature points to produce the coarse tracking results. 3) To get the final refined prediction, we use a unique Prediction Refinement Module based on the coarse tracking findings. Additionally, based on the Waymo Open Dataset, they have developed a large-scale point cloud-specific object tracking benchmark. Extensive testing demonstrates that PTTR outperforms point cloud monitoring in terms of accuracy and productivity.
The dataset:
One of the most used datasets for mobile robots and autonomous driving is KITTI (Karlsruhe Institute of Technology and Toyota Technological Institute). It is made up of hours' worth of traffic scenarios that were captured using a range of sensor modalities, such as high-resolution RGB, grayscale stereo, and 3D laser scanner cameras. The dataset itself does not provide ground truth for semantic segmentation, despite its widespread use. To suit their needs, many researchers have manually marked some dataset portions.
Three classes—road, vertical, and sky—were used to construct ground truth for 323 photos from the road detection challenge. For the tracking task, Zhang et al. annotated 252 RGB and Velodyne scan acquisitions (140 for training and 112 for testing) for the following 10 object categories: buildings, skies, roads, vegetation, sidewalks, cars, pedestrians, cyclists, sign/poles, and fences. From the visual odometry challenge, Ros et al. classified 170 training images and 46 testing images into 11 classes: building, tree, sky, car, sign, road, pedestrian, fence, pole, sidewalk, and bike.
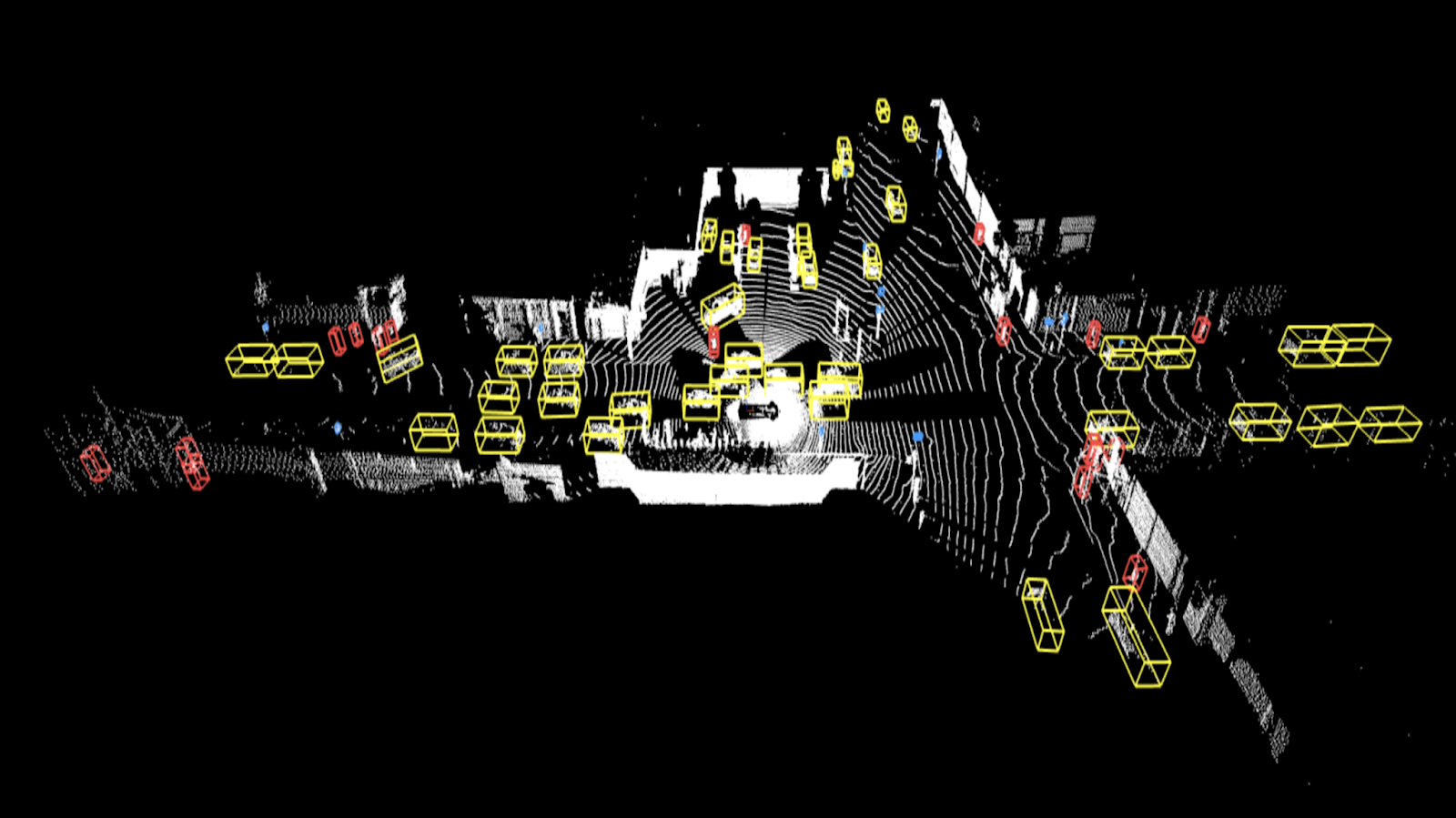
Autonomous vehicles are driven by Waymo Drivers in a variety of settings, generating high-quality sensor data, which is what makes up the Waymo Open Dataset.
There are 1,950 segments in the Waymo Open Dataset as of right now. This dataset will eventually grow, according to the authors.
You can download the dataset from here
Related Paper for your Reference
Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints published on CVPR 2018 by Reza Mahjourian, Martin Wicke, Anelia Angelova
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos published by Vincent Casser, Soeren Pirk, Reza Mahjourian, Anelia Angelova
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection published on CVPR 2020 by Shaoshuai Shi, Chaoxu Guo, Li Jiang, Zhe Wang, Jianping Shi, Xiaogang Wang, Hongsheng Li
PV-RCNN++: Point-Voxel Feature Set Abstraction With Local Vector Representation for 3D Object Detection published by Shaoshuai Shi, Li Jiang, Jiajun Deng, Zhe Wang, Chaoxu Guo, Jianping Shi, Xiaogang Wang, Hongsheng Li
4. XNect: Real-time Multi-Person 3D Motion Capture with a Single RGB Camera
Author: Dushyant Mehta, Oleksandr Sotnychenko, Franziska Mueller, Weipeng Xu, Mohamed Elgharib, Pascal Fua, Hans-Peter Seidel, Helge Rhodin, Gerard Pons-Moll, Christian Theobalt
They have offered a real-time method for multi-person 3D motion capture using a single RGB camera at a frame rate of more than 30 fps. It works well in general-purpose situations that might have people and/or object occlusions. Their procedure functions in phases. A convolutional neural network (CNN) is used in the first step to estimate the 2D and 3D pose features as well as the identities of each individual's visible joints. We provide a brand-new design for this CNN dubbed SelecSLS Net that makes use of novel selective long and short-range skip connections to enhance information flow and enable a significantly quicker network without sacrificing accuracy.
The 2Dpose and 3Dpose features for each subject are converted into a comprehensive 3Dpose estimate for each person in the second step using a fully connected neural network. In order to further reconcile the projected 2D and 3D stance for each individual and impose temporal coherence, the third stage employs space-time skeleton model fitting. For each subject, their approach returns the entire skeletal position in joint angles. This is another significant improvement over earlier work, which did not give joint angle results of a coherent skeleton in real time for multi-person situations.
The datasets:
The Human3.6M dataset is one of the largest motion capture datasets, which consists of 3.6 million human poses and corresponding images captured by a high-speed motion capture system. There are 4 high-resolution progressive scan cameras to acquire video data at 50 Hz. The dataset contains activities by 11 professional actors in 17 scenarios: discussion, smoking, taking photos, talking on the phone, etc., as well as provides accurate 3D joint positions and high-resolution videos.
The MPII Human Pose Dataset for single-person pose estimation is composed of about 25K images of which 15K are training samples, 3K are validation samples and 7K are testing samples (which labels are withheld by the authors). The images are taken from YouTube videos covering 410 different human activities and the poses are manually annotated with up to 16 body joints.
The 3D Poses in the Wild dataset is the first dataset in the wild with accurate 3D poses for evaluation. While other datasets outdoors exist, they are all restricted to a small recording volume. 3DPW is the first one that includes video footage taken from a moving phone camera.
The dataset includes
- 60 video sequences.
- 2D pose annotations.
- 3D poses obtained with the method introduced in the paper.
- Camera poses for every frame in the sequences.
- 3D body scans and 3D people models (re-poseable and re-shapeable). Each sequence contains its corresponding models.
- 18 3D models in different clothing variations.
The Leeds Sports Pose (LSP) dataset is widely used as the benchmark for human pose estimation. The original LSP dataset contains 2,000 images of sportspersons gathered from Flickr, 1000 for training and 1000 for testing. Each image is annotated with 14 joint locations, where left and right joints are consistently labelled from a person-centric viewpoint. The extended LSP dataset contains additional 10,000 images labeled for training.
MPI-INF-3DHP is a 3D human body pose estimation dataset consisting of both constrained indoor and complex outdoor scenes. It records 8 actors performing 8 activities from 14 camera views. It consists of>1.3M frames captured from the 14 cameras.
CMU Panoptic is a large-scale dataset providing 3D pose annotations (1.5 million) for multiple people engaging in social activities. It contains 65 videos (5.5 hours) with multi-view annotations, but only 17 of them are in the multi-person scenario and have the camera parameters.
You can download the dataset from here
Related Paper for your Reference
Accurate 3D Body Shape Regression Using Metric and Semantic Attributes by Vasileios Choutas, Lea Muller, Chun-Hao P. Huang, Siyu Tang, Dimitrios Tzionas, Michael J. Black
FrankMocap: A Monocular 3D Whole-Body Pose Estimation System via Regression and Integration by Yu Rong, Takaaki Shiratori, Hanbyul Joo ·
End-to-end Recovery of Human Shape and Pose published on CVPR 2018 by Angjoo Kanazawa, Michael J. Black, David W. Jacobs, Jitendra Malik
Learning to Reconstruct 3D Human Pose and Shape via Model-fitting in the Loop published on ICCV 2019 by Nikos Kolotouros, Georgios Pavlakos, Michael J. Black, Kostas Daniilidis ·
5. Lifelong Unsupervised Domain Adaptive Person Re-Identification With Coordinated Anti-Forgetting and Adaptation
Author: Zhipeng Huang, Zhizheng Zhang, Cuiling Lan, Wenjun Zeng, Peng Chu, Quanzeng You, Jiang Wang, Zicheng Liu, Zheng-Jun Zha ·
In order to lessen the negative impacts of domain gaps, person re-identification (ReID) that is unsupervised domain adaptive has received substantial research. These works make the assumption that the target class data is all-accessible at once. However, this makes it more difficult for real-world streaming data to adequately utilise growing sample sizes and adjust in time to changing data statistics. In this study, we propose a novel challenge called Lifelong Unsupervised Domain Adaptive (LUDA) individual ReID to address more realistic settings.
This is difficult because, for a job as precise as person retrieval, the model must continuously adjust to unlabeled data in the target contexts while preventing catastrophic forgetting. With our CLUDA-ReID approach, which they have developed for this objective, the anti-forgetting and adaptation are harmoniously coordinated. To replay past data and upgrade the system with a synchronized optimization strategy for both adaptability and memorization, a meta-based Integrated Data Repeat technique is specifically presented. Additionally, in accordance with the goal of retrieval-based tasks, we suggest Relational Consistency Learning for the distillation and inheritance of previous information.
The dataset:

Market-1501 is a large-scale public benchmark dataset for person re-identification. It contains 1501 identities which are captured by six different cameras, and 32,668 pedestrian image bounding boxes obtained using the Deformable Part Models pedestrian detector. Each person has 3.6 images on average at each viewpoint. The dataset is split into two parts: 750 identities are utilized for training and the remaining 751 identities are used for testing. In the official testing protocol, 3,368 query images are selected as probe sets to find the correct match across 19,732 reference gallery images.
The CUKL-SYSY dataset is a large-scale benchmark for person search, containing 18,184 images and 8,432 identities. Different from previous re-id benchmarks, matching query persons with manually cropped pedestrians, this dataset is much closer to real application scenarios by searching persons from whole images in the gallery.
You can download the dataset from here
Related Paper for your Reference
Implicit Sample Extension for Unsupervised Person Re-Identification published on CVPR 2022 by Xinyu Zhang, Dongdong Li, Zhigang Wang, Jian Wang, Errui Ding, Javen Qinfeng Shi, Zhaoxiang Zhang, Jingdong Wang
Margin Sample Mining Loss: A Deep Learning Based Method for Person Re-identification by Qiqi Xiao, Hao Luo, Chi Zhang
Semi-Supervised Domain Generalizable Person Re-Identification published by Lingxiao He, Wu Liu, Jian Liang, Kecheng Zheng, Xingyu Liao, Peng Cheng, Tao Mei
Joint Detection and Identification Feature Learning for Person Search published on CVPR 2017 by Tong Xiao, Shuang Li, Bochao Wang, Liang Lin, Xiaogang Wang
Click here for the 2nd part of Worth reading benchmark datasets from CVPR 2022!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
