Claude Mythos Preview Claude Mythos: Benchmark-Dominating AI with Real Risks Claude Mythos Preview is Anthropic’s most powerful AI yet, outperforming benchmarks and uncovering critical vulnerabilities. But its release is restricted due to potential risks, making it a groundbreaking yet tightly controlled system.
muse spark Meta Muse Spark : Features, Benchmarks and Reality Meta’s Muse Spark is a new multimodal reasoning model built for speed, efficiency, and real-world AI applications. With multi-agent reasoning and advanced capabilities, it marks Meta’s major comeback in the AI race.
ROSClaw How ROSClaw Connects Large Language Models to Robots ROSClaw connects LLMs to robots through a standardized executive layer, revealing how different AI models produce drastically different behaviors, safety risks, and execution styles under identical conditions.
Gemma 4 Google Gemma 4: A Technical Overview Gemma 4 is a powerful open-weight AI model from Google DeepMind, offering multimodal capabilities, high efficiency, and strong benchmark performance across text, code, and reasoning tasks, all with full commercial freedom.
yolo model training 5 Best YOLO Model Training Service Providers in 2026 Discover how to train high-performance YOLO models using optimized datasets and workflows tailored for real-world use cases in India, including traffic, agriculture, and surveillance applications.
AI model training 7 Top AI Model Training Service Providers in 2026 Training AI models is complex, but managed platforms simplify everything from annotation to deployment. Discover the top AI model training service providers in 2026 and find the right platform for your computer vision, LLM, or multimodal workflows.
SAM 3.1 SAM 3.1 vs SAM 3 Faster Video Tracking SAM 3.1 introduces Object Multiplex to eliminate multi-object tracking bottlenecks. By processing multiple objects in a single pass, it delivers up to 7x faster inference and real-time performance without changing the model architecture.
egocentric datasets 7 Top Egocentric Data Service Providers for Robotics 2026 Egocentric data is transforming robotics by capturing the world from a robot’s perspective. This guide covers the top 7 providers in 2026 helping teams build accurate, real-world-ready models with high-quality first-person datasets.
robot manipulation 8 Best Video Labeling Tools for Robotics Manipulation 2026 Explore the best video annotation tools for robot manipulation in 2026. Learn how labeling data powers robotics, and compare top platforms for tracking, 3D data, and AI-assisted workflows.
synthetic data for robotics 7 Top Synthetic Data Platforms for Robotics in 2026 Synthetic data is transforming robotics by enabling scalable, safe, and fully labeled training environments. Discover top platforms powering simulation-driven robot learning in 2026.
human in the loop data labeling 6 Top Human-in-the-Loop Data Services for Robotics 2026 Human-in-the-loop data services help robotics teams train smarter AI by combining automation with human expertise. Discover the top HITL platforms used to label LiDAR, video, and sensor data for warehouse robots, autonomous systems, and humanoid robotics.
teleoperation robotics 7 Top Teleoperation Service Providers for Robotics in 2026 Teleoperation is powering the next generation of humanoid robots. Discover seven companies building the infrastructure for robot training, data pipelines, and human-guided control systems used by leading robotics programs in 2026.
AI cricket analytics AI-Powered Cricket Bowling Analyzer Using Yolo Build an AI-powered cricket bowling biomechanics system using YOLOv8x-Pose. Track shoulder, elbow, and wrist keypoints, calculate elbow angle, measure wrist speed, and visualize the bowling arm arc directly from standard broadcast video.
data annotation 7 Top Data Labeling Companies in Robotics 2026 Discover the top data annotation companies for robotics and physical AI in 2026. Compare platforms for egocentric video, LiDAR, and multimodal datasets that help robots learn faster with high-quality training data.
robot world model DreamDojo Platform for Scalable Robot Training DreamDojo is a generalist robot world model trained on 44,711 hours of human video. It learns interaction dynamics, enables zero-shot generalization, and supports model-based planning for scalable embodied AI.
Gemini 3.1 Pro Google Gemini 3.1 Pro Review and Analysis Gemini 3.1 Pro is Google’s most advanced reasoning model yet, built for deep agentic workflows, large-scale code generation, and multimodal tasks. With 65K output tokens and major benchmark gains, it shifts AI from conversation to autonomous execution.
SAM 3 Benchmarking SAM and SAM 3 on Aerial Data Compare SAM and SAM 3 for aerial image segmentation. See zero-shot benchmark results across satellite datasets, performance differences, and how to use both models inside Labellerr for faster geospatial annotation workflows.
humanoid robot learning VideoMimic: How Robots Learn Human Motion VideoMimic turns monocular human videos into deployable humanoid robot policies. By combining 4D reconstruction, scene geometry, and reinforcement learning, it enables context-aware robot control without motion capture or handcrafted rewards.
Spatial Reasoning How Think3D Gives Vision Models a Real Sense of Space Think3D enables AI models to reason directly in 3D space instead of flat images. By combining 3D reconstruction, camera geometry, and reinforcement learning, it transforms how vision-language models understand depth, occlusion, and viewpoint change.
egocentric video generation EgoControl: Controllable First Person Video Simulation EgoControl reframes egocentric video generation as embodied simulation. By conditioning diffusion models on future 3D full-body poses, it enables controllable, physically grounded first-person video prediction aligned with intended human motion.
SemanticGen Why SemanticGen Is a Leap for Long-Form Video AI SemanticGen redefines video generation by separating semantic planning from pixel synthesis. Using a two-stage diffusion process, it enables long-form, coherent videos while avoiding the computational limits of traditional diffusion models.
Genie 3 Genie 3 Doesn't Make Videos, It Builds Worlds Genie 3 by Google DeepMind is a real-time 3D world model that creates interactive, persistent environments. It enables scalable egocentric data for robotics training, helping embodied AI learn navigation, perception, and long-horizon reasoning.
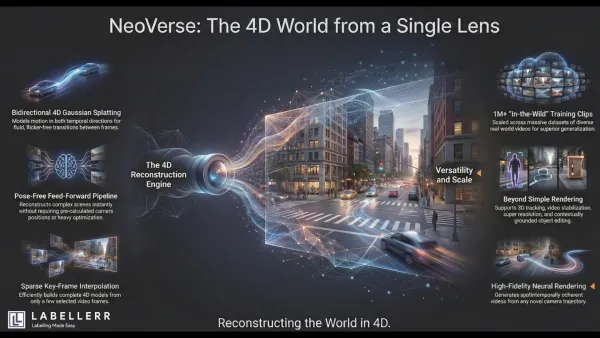
NeoVerse NeoVerse 4D World Model: Escaping the 4D Data Bottleneck NeoVerse is a scalable 4D world model that reconstructs dynamic scenes directly from in-the-wild monocular videos. Using a pose-free, feed-forward design, it eliminates multi-view capture and heavy preprocessing while enabling fast, high-quality 4D reconstruction and video generation.
egocentric datasets How EgoX Converts Third-Person to First-Person Video EgoX transforms a single third-person video into a realistic first-person experience by grounding video diffusion models in 3D geometry, enabling accurate egocentric perception without extra sensors or ground-truth data.
LTX-2 Generate Video and Audio Together with LTX-2 LTX-2 is the first open-source model that generates synchronized audio and video together using a joint diffusion process, enabling realistic speech, sound effects, and motion alignment in a single system.