

How To Make Large Language Models Helpful, Harmless, and Honest


Table of Contents
- Introduction
- Alignment Criteria
- Helpfulness
- Honesty
- Harmless
- Collecting Human Feedback
- Human Labeler Selection
- Human Feedback Collection
- Question-based Approach
- Rule Based Approach
- Reinforcement Learning from Human Feedback
- Conclusion
Introduction
LLMs have demonstrated impressive capabilities across various NLP tasks. However, there are instances where these models exhibit unintended behaviors, such as generating false information, pursuing inaccurate objectives, and producing harmful or biased expressions.
The language modeling objective used in pre-training LLMs focuses on word prediction without considering human values or preferences.
Human alignment has been introduced to address these unexpected behaviors to ensure that LLMs align with human expectations.
However, unlike the original pre-training and adaptation tuning approaches, alignment requires considering different criteria, such as helpfulness, honesty, and harmlessness.
It has been observed that alignment may hurt the overall abilities of LLMs, referred to as alignment tax in the literature.
This Blog provides an 0verview of alignment, including its definition and criteria. It then delves into collecting human feedback data to align LLMs.
Finally, it explores the important reinforcement learning technique from human feedback for alignment tuning.
Alignment Criteria
There is growing interest in defining various criteria to regulate the behavior of LLMs. In this context, we discuss three commonly used alignment criteria: helpfulness, honesty, and harmlessness.
These criteria have received significant attention in the literature and are widely adopted. Additionally, other alignment criteria for LLMs, such as behavior, intent, incentive, and inner aspects, share similarities with the aforementioned criteria regarding alignment techniques.
It is also possible to modify or customize the criteria based on specific requirements, such as substituting honesty with correctness or focusing on specific criteria.
The following sections briefly explain each of the three representative alignment criteria.
Helpfulness
Helpfulness is an important alignment criterion for LLMs, which involves the model's ability to assist users concisely and efficiently.
The LLM should strive to solve tasks and answer questions while demonstrating sensitivity, perceptiveness, and prudence. LLMs need to elicit additional relevant information when necessary and understand users' intentions to be aligned with helpful behavior.
However, achieving alignment in helpfulness can be challenging due to the difficulty in precisely defining and measuring user intention.
Honesty
Honesty is another important alignment criterion for LLMs, focusing on the accuracy and transparency of the model's output. An LLM aligned with honesty should provide users with truthful information and avoid fabricating content.
Furthermore, the model should appropriately express uncertainty and acknowledge its limitations to prevent deception or misrepresentation. Understanding its capabilities and recognizing areas of unknown knowledge ("know unknowns") is crucial for achieving alignment in honesty.
Compared to helpfulness and harmlessness, honesty is considered a more objective criterion, and there may be potential for developing alignment techniques with less reliance on human efforts.
Harmless
Harmlessness is an essential criterion for alignment in LLMs, emphasizing that the language generated by the model should not contain offensive or discriminatory content.
The model should also be able to detect covert attempts to manipulate it for malicious purposes. Ideally, if the model is prompted to engage in harmful actions, such as committing a crime, it should politely refuse.
However, determining what behaviors are considered harmful and to what extent can vary among individuals and societies.
The perception of harm depends on factors such as the user, the nature of the question asked, and the specific context in which the LLM is being used.
Collecting Human Feedback
In the pre-training phase, language models (LLMs) are trained using a large corpus, primarily focused on language modeling objectives.
However, this approach overlooks the subjective and qualitative assessments of LLM outputs by humans, known as human feedback. Collecting high-quality human feedback is crucial to align LLMs with human preferences and values.
This section explores the process of selecting a team of human labelers for data collection, specifically for providing feedback on LLM outputs.

Figure: Collecting Human Feedback
Our platform makes it easy to gather high-quality input on things like helpfulness, honesty, and harmlessness. With our user-friendly tools and support for managing labelers, you can tune your LLMs to match human values effortlessly. Signup free Researcher Plan.
Human Labeler Selection
Human annotation has been the dominant method for generating human feedback data in existing research.
The selection of suitable human labelers is crucial for providing high-quality feedback. Typically, human labelers are required to have a qualified level of education and excellent proficiency in English.
For instance, Sparrow mandates that labelers be native English speakers from the UK with at least an undergraduate-level educational qualification.
In other studies, about half of the labelers recruited for high-priority tasks were US-based Amazon Mechanical Turk workers holding a master's qualification.
However, there can still be a disconnect between researchers' intentions and human labelers, leading to low-quality feedback and unexpected LLM outputs.
InstructGPT implements a screening process to filter labelers based on agreement with researchers to address this issue.
Researchers initially label a small amount of data and assess the agreement between themselves and human labelers. The labelers with the highest agreement are selected for further annotation work.
Another approach involves using "super raters" to ensure high-quality feedback. Researchers evaluate the performance of human labelers and choose a group of well-performing labelers (e.g., those with high agreement) as super raters who collaborate closely with the researchers in subsequent studies.
Providing detailed instructions and instant guidance to human labelers during annotation is also beneficial in regulating their annotations.
Human Feedback Collection
Existing research employs three primary approaches for collecting feedback and preference data from human labelers. These methods include:
Ranking Based Approach
The ranking-based approach is used in early research to evaluate and align model-generated outputs. Initially, human labelers would select the best output without considering more nuanced alignment criteria.
However, this approach had limitations as different labelers may have varying opinions on the best candidate, and unselected samples were disregarded, resulting in incomplete feedback. To overcome these challenges, subsequent studies introduced the Elo rating system.
This system compares candidate outputs and establishes a preference ranking. The ranking of outputs serves as a training signal, guiding the model to favor certain outputs over others.
This approach aims to induce more reliable and safer outputs by considering the collective ranking preferences of human labelers.
Question-based approach
The question-based approach involves collecting more detailed feedback from human labelers by having them answer specific questions designed by researchers. These questions cover the alignment criteria and additional constraints for LLMs.
For example, in the WebGPT system, human labelers are asked to answer questions with multiple options to determine whether the retrieved documents are useful for answering a given input.
This approach allows for a more targeted assessment of the model's performance and helps improve its ability to filter and utilize relevant information from retrieved documents.
Rule Based Approach
The rule-based approach involves developing methods that utilize predefined rules to provide more detailed human feedback.
For example, in the Sparrow system, a series of rules is used to assess whether the model-generated responses align with helpful, correct, and harmless criteria.
This approach allows for obtaining two types of human feedback data:
- response preference feedback, which is obtained by comparing the quality of model-generated outputs in pairs
- rule violation feedback is collected by assessing the extent to which the generated output violates the predefined rules.
Another example is GPT-4, which uses zero-shot classifiers as rule-based reward models to automatically determine whether the model-generated outputs violate a set of human-written rules.
These rule-based approaches provide a more detailed and objective assessment of the model's performance and alignment with desired criteria.
In the upcoming discussion, we will primarily examine a popular technique called reinforcement learning from human feedback (RLHF), which has found extensive application in advanced language models like ChatGPT.
Reinforcement Learning from Human Feedback
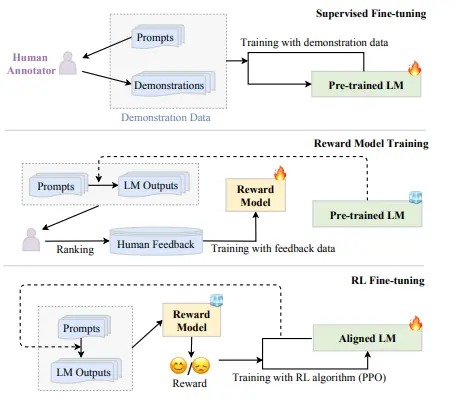
Figure: Workflow of the RLHF algorithm.
To ensure that LLMs are aligned with human values, reinforcement learning from human feedback (RLHF) has been introduced.
This approach involves fine-tuning LLMs using human feedback data to improve alignment criteria such as helpfulness, honesty, and harmlessness.
RLHF utilizes reinforcement learning algorithms like Proximal Policy Optimization (PPO) to adjust LLMs based on a learned reward model.
By incorporating humans into the training process, RLHF enables the development of well-aligned LLMs, as demonstrated by projects like InstructGPT.
RLHF System
The RLHF system consists of three main components: a pre-trained language model (LM) to be aligned, a reward model that learns from human feedback, and an RL algorithm to train the LM.
The pre-trained LM is a generative model initialized with existing pre-trained parameters, such as GPT-3 or Gopher models.
The second step of the process involves training the reward model (RM) using human feedback data. To do this, we utilize the language model (LM) to generate a set number of output texts by providing it with prompts sampled from either the supervised dataset or prompts generated by humans.
We then ask human labelers to annotate their preference for these pairs. One common approach is to have labelers rank the generated candidate texts, which helps to reduce inconsistencies among annotators.
The reward model is then trained to predict the output that humans prefer. In the case of InstructGPT, labelers rank the model-generated outputs from best to worst, and the reward model (specifically, the 6B GPT-3 model) is trained to predict this ranking.
A specific RL algorithm optimizes the pre-trained LM based on the reward model's signal. Proximal Policy Optimization (PPO) is a commonly employed algorithm in existing work.
Key Steps for RLHF
The above figure provides an overview of the three-step process of reinforcement learning from human feedback (RLHF) as follows:
- Supervised Fine-tuning: The pre-trained language model (LM) uses human demonstrations or examples to guide its output toward a desired behavior. This step involves training the LM with supervised learning using human-provided reference outputs.
- Reward Model Training: A reward model is trained to evaluate the quality of the LM's generated text. The reward model learns from human feedback and assigns reward values (e.g., positive or negative) to the LM's outputs based on alignment criteria (e.g., helpfulness, correctness, harmlessness).
- RL Fine-tuning: The pre-trained LM is further fine-tuned using reinforcement learning (RL) algorithms, such as Proximal Policy Optimization (PPO).
The RL algorithm maximizes the expected cumulative reward signal provided by the reward model, thereby improving the alignment of the LM with human preferences.
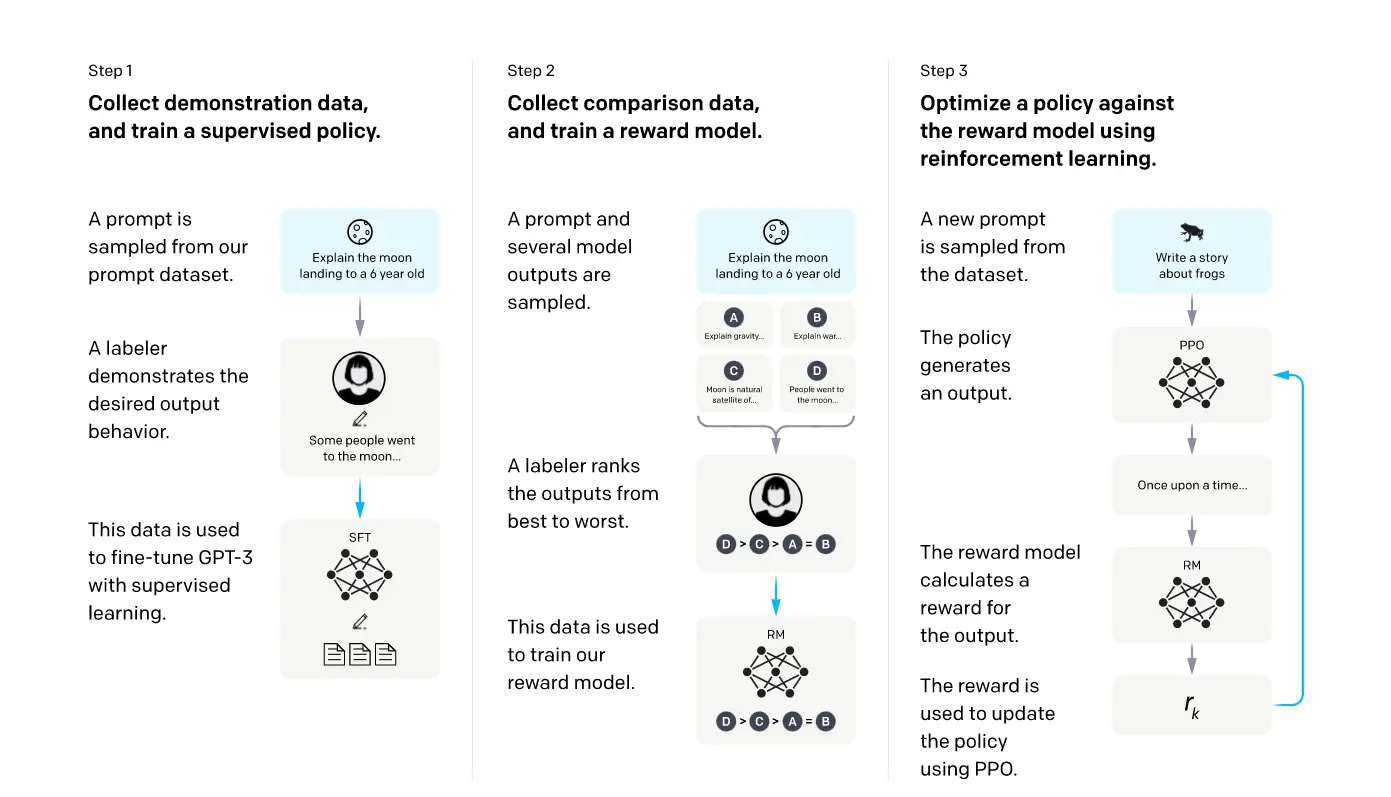
Figure: 3 Key steps involved in Reinforcement Learning from Human Feedback
Conclusion
In conclusion, alignment tuning ensures language models (LLMs) align with human expectations and preferences. Alignment criteria such as helpfulness, honesty, and harmlessness are important for guiding LLM behavior.
Collecting high-quality human feedback is essential for aligning LLMs, and the selection of human labelers plays a significant role in this process.
Different approaches, such as the ranking, question, and rule-based approaches, are used for collecting human feedback data.
Reinforcement learning from human feedback (RLHF) is a popular technique for fine-tuning LLMs based on human preferences and values.
RLHF involves a three-step process of supervised fine-tuning, reward model training, and RL fine-tuning. By incorporating humans into the training process, RLHF enables the development of well-aligned LLMs.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
