

Advancing Performance in Automating Invoice Processing


Large companies dealing with a high volume of invoices daily show great interest in automatic invoice processing systems.
These systems are attractive not only because of their legal requirement to store invoices for years but also due to economic reasons.

Figure: Bills and Invoices
Cristani et al. compared manually processed invoices, which required 9 €, and automated processing, which required only 2 € per invoice, based on surveys conducted in 2004 and 2003, respectively.
According to a report by the Institute of Finance and Management 2016, the average cost to process an invoice was $12.90.
Recently, various challenges have focused on recognizing and extracting important text from scanned receipts and invoices.
Examples include the Robust Reading Challenge on Scanned Receipt OCR and Information Extraction (SROIE) at ICDAR 2019 and the Mobile-Captured Image Document Recognition for Vietnamese Receipts at RIVF2021.
However, more readily available benchmark datasets for annotated invoices must be available, primarily due to confidential information.
Furthermore, while receipts and invoices share some similarities, their analysis methods differ significantly due to the complex graphical layouts and the richer content found in invoices.
In this article, we discuss the recent progress in detecting and analyzing invoices, which focuses on automating the processing of structured business documents, including contracts and invoices. The project utilizes OCR (Optical Character Recognition) technology to analyze the document pages and extract relevant information.
A Novel Approach
Two steps are involved in humans' natural approach to extracting specific information from a document.
Firstly, the document is scanned to locate the desired information, and then extracted in the required format. Different types of information have distinct structures determined by human rules.
For example, a VAT number follows a specific format. Other types of information require context to differentiate them from similar or different types.
For instance, a date can be identified as the invoice or due date based on accompanying keywords.
Some information, like the seller's name or address, may require heuristic knowledge. The pipeline followed in the system is inspired by the human approach.
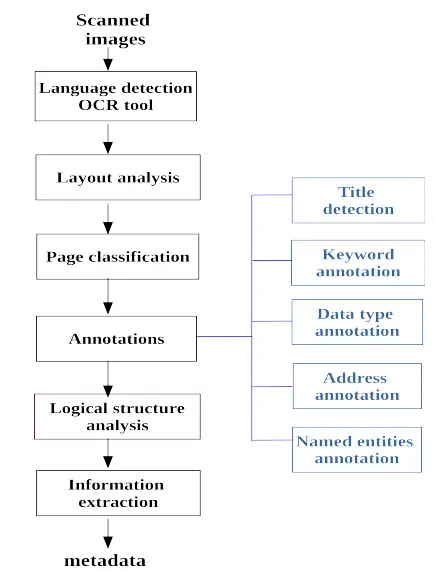
Figure: Pipeline followed
The processing pipeline, as shown in the above figure, consists of interconnected modules that allow the addition of partial annotations to the analyzed document.
Initially, the invoice image is processed using an OCR tool, which becomes crucial when dealing with multilingual documents. Detecting the languages used in the document is important for configuring the OCR tool and subsequent annotations.
The primary language of the document is determined by the language used in the title and data field names, such as "invoice," "date," "order number," and "payment method."
A dictionary of these terms is created for each possible language, and if the document contains terms from a specific language, it is assigned as the primary language.
Otherwise, the document's language is determined based on the text language distribution detected by the OCR tool in the initial run with multiple languages.
Next, the physical layout of the document is established using the positional information of words and characters obtained from OCR (Layout analysis module).
This step contributes to the page classification process. Various annotations using natural language processing (NLP) techniques are then applied to the content through XML tagging, including titles, keywords, data types, addresses, and named entities.
These annotations provide semantic information and, along with positional information, create the context for further analysis. Based on these annotations, a rule-based model extracts the logical structure where each text block is assigned an informational type.
Finally, the desired metadata information is extracted by the last module.
Document physical layout analysis
To begin with, the OCR engine processes the invoice image and determines the positions of each recognized word by calculating their bounding boxes.
The analysis involves grouping words into lines based on three criteria: alignment, style, and distance. If two words have similar alignment and style, and the distance between them is below a certain threshold, they are considered part of the same line.
Once the lines are identified, they form text blocks using a similar process. If two lines are vertically aligned, have similar font sizes, and the distance between them is below a threshold, they are grouped into a block.
However, unlike the consistent spacing between words in a line, the distances between lines within a block can vary significantly due to the graphical format. The threshold for grouping lines into blocks is twice the height of the last line in the block.
After establishing the physical layout of the document, each block is assigned identification in the form of block attributes.
These attributes include the absolute position of the block on the page and its relative position with other blocks.
The absolute position divides the page into vertical sections, such as the header, top, middle, bottom, and footer, and horizontal sections, such as left and right.
The relative position identifies the block's neighbors in the top, bottom, left, right, and bottom-right positions.
Page classification
The pipeline in the approach discussed incorporates two classification tasks to determine whether a document is an invoice and if a page is the first page.
This is particularly useful when processing batches of business documents, including invoices. The classification utilizes the available semantic content of the document and varies based on the module's position in the pipeline.
Typically, this classification step occurs between the layout and logical structure analyses.
The features used in this classification step include binary features for the most common words obtained from the document collection for each language, excluding entity names and stop words.
The identified page title (text, position, and size) and the page number are also considered. If the classification module progresses further in the pipeline, the features are expanded to include keyword and data type annotations and block types.
While the frequent words feature focuses on individual words, the annotations provide logical meaning information.

Figure: In the given context, the prefix "u" represents a frequent word, "K_" signifies a keyword annotation, and "D " indicates a data type annotation. The provided frequent words include "dodavatel - seller," "odběratel - buyer," "faktura - invoice," "doklad - document," "splatnosti - due date," and "zdanitelného - taxable."
The classification output assigns a label of 1 to indicate that a page is the first page of an invoice. Conversely, a label of 0 indicates that the page is either a second or subsequent page of an invoice or not an invoice.
Annotation Modules
The annotation modules are crucial in processing the enriched OCR document by incorporating valuable information through natural language processing tasks.
This process resembles how a human reader would identify important details like the name of a city throughout the document and utilize this information in global-level rules.
The initial three modules within the sequence of task-oriented annotators operate on the plain text of recognized block lines.
They aim to identify specific keywords and structured data such as dates, prices, VAT numbers, and IBAN (International Bank Account Number).
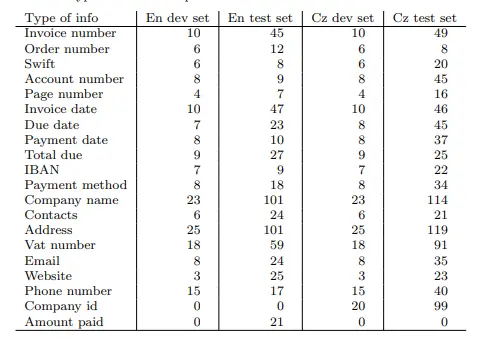
Figure: The most common item types in the development and test sets
Keywords serve as indicators to locate the desired information. For example, keywords for the invoice date could be "invoice date," "date issued," "issued date," "billed on," or "date" at the beginning of a line.
The keywords for each language are determined by analyzing invoices in the development set. These modules are designed to handle specific character-level errors that may occur in the OCR output.
Block Type Detection
Once the annotation modules have incorporated all the relevant local information into the analyzed content, each block is assigned one or more possible block types.
In the case of invoice text blocks, they are categorized into different types, including general information (invoice number, order number, date), seller/buyer information (company name, address, VAT number, contact details), delivery information (delivery address, date, method, code, and cost), bank information (bank name, address, SWIFT code, account number), and the invoice title and page number.
Blocks that do not fit into these categories are assigned an empty label.
The block type detection in the above approach is accomplished through a set of logical rules that utilize information gathered in the preceding steps of the pipeline.
These rules are human-readable and easily modifiable. Each rule is applied to every block in the invoice document, and if a block satisfies the conditions of a particular rule, the corresponding label is assigned as the block's type.
Information Extraction
The data extracted from the document can consist of individual pieces of information, such as the invoice number, invoice date, order number, order date, due date, payment date, payment method, IBAN, or swift code.
It can also involve information groups, such as buyer information, seller information, and delivery address. The first group can be further categorized into smaller clusters: "DATE," "PRICE," "NUMBER," and "GENERAL."
The first two clusters typically associate keywords with specific data types, while the latter two may not have predefined rules for the data.
Unique structured information, like a VAT number, can be identified without relying on keywords.
Each type of information is assigned a confidence score, which helps distinguish situations where only a keyword is found, the data type matches or both conditions are satisfied. For instance, with the VAT number as an example:

Figure: Information type and score for Vat Number
Initially, the system searches for relevant keywords within the annotations. If a keyword is found, the corresponding block and line containing the keyword are identified.
However, the expected data is absent in that line. In that case, a weighted function is applied to the adjacent right block and bottom/bottom-right block to determine whether the data is located to the right or below the keyword.
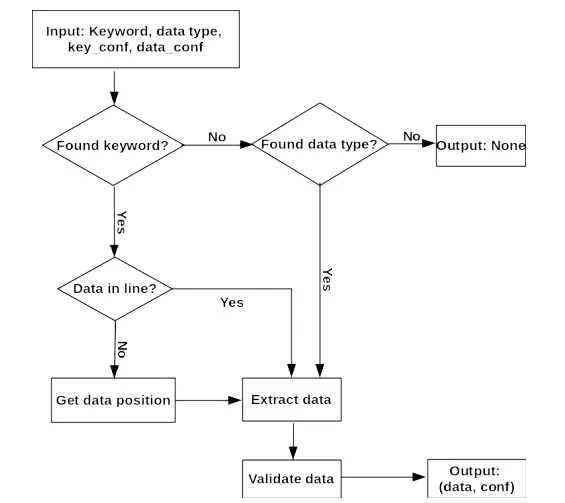
Figure: The workflow process for extraction is depicted in the above figure.
This function assigns a higher score to the correct data type and a lower score to any other data found in the annotations. It imposes a penalty for other keywords that are discovered.
This approach considers the common information organization in columns, where keywords are typically in the left column, and the corresponding data is on the right. The block with the higsher weight is considered more likely to contain the desired data.
In cases where the keyword is not found, the system examines the data type, particularly if it involves structured information. The annotation steps are designed to handle certain OCR errors, and a validation step is incorporated to verify and rectify the extracted data if necessary.
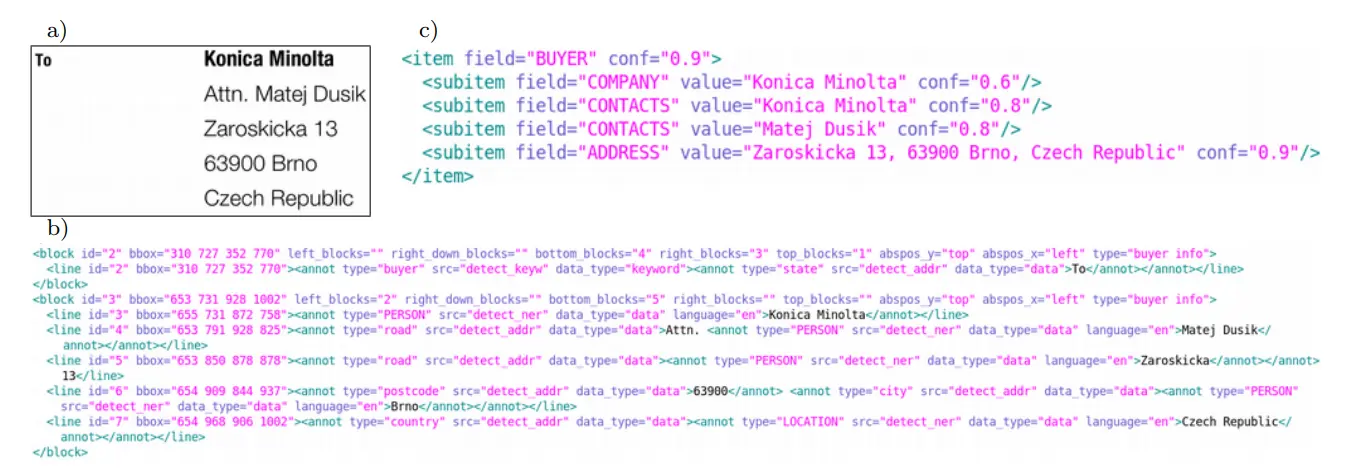
Figure: An example of an address block analysis: a) the input image, b) after annotation, and c) the extracted information
Performance Analysis
The system underwent evaluation using two invoice datasets, one in English and the other in Czech. These datasets included data from over 150 vendors globally.
The system achieved a high detection rate with an open-source OCR tool and a small development set comprising only 20 invoices.
It successfully detected 90.5% of items in the English invoices and 88.2% in the Czech invoices, with 93-96% of these detected items having accurate values.
Additionally, the system demonstrated an impressive ability to determine whether an image represents the first page of an invoice, achieving an accuracy rate of 98%.
Conclusion
In Conclusion, above approach shows promise in automating invoice processing, offering potential benefits for companies dealing with large invoices.
However, the limited availability of benchmark datasets for annotated invoices remains a challenge, primarily due to confidential information. Further research and development are needed to improve the accuracy and reliability of text extraction from bills and invoices.
The project utilizes OCR (Optical Character Recognition) technology to analyze document pages and extract relevant information. Further, the pipeline consists of interconnected modules that incorporate partial annotations into the analyzed document, enabling the extraction of desired metadata information.
The performance of above methodology and system has been evaluated using two invoice datasets, one in English and the other in Czech.
These datasets contain data from over 150 different vendors worldwide. The system achieved impressive results, with a high detection rate for items in the invoices.
It detected 90.5% of items in the English invoices, 88.2% in the Czech invoices, and 93-96% of these detected items had accurate values.
Additionally, it has demonstrated a 98% accuracy in determining whether an image represents the first page of an invoice.
Frequently Asked Questions (FAQ)
What is Automatic Invoice Processing?
In simple terms, automated invoicing refers to setting up an invoice system that operates automatically. It involves using technology to streamline the invoice processing workflow, saving time for businesses of any scale.
This technology handles all aspects of invoice processing, starting from creation and ending with payment reconciliation.
What AI tool is popularly used for making invoices?
Invoicer.ai is an AI-powered invoicing tool that streamlines the invoice creation process for sellers and buyers. This cloud-based solution provides a user-friendly interface and guides users through creating invoices, helping them stay organized and generate professional invoices quickly.
By leveraging AI technology, Invoicer.ai enhances cash flow management and simplifies the invoicing experience.
What are the benefits of Automated Invoice Processing?
The benefits include Cutting down on error rates. Further, it also leads to less manual entry means less room for mistakes, along with Speeding up the approval process and reducing processing times. Saves on labor costs.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
