

Accelerate Training Data Generation With OpenAI Embedding

OpenAI is an artificial intelligence research laboratory consisting of the forerunners of the AI community. One of their flagship products is the OpenAI GPT-4 model.
This state-of-the-art language model can perform various language tasks, such as text generation, classification, and summarization.
GPT-4 is a large multimodal model (accepting text inputs and emitting text outputs today, with image inputs coming in the future) that can solve difficult problems with greater accuracy than any of our previous models, thanks to its broader general knowledge and advanced reasoning capabilities.
This blog will discuss how to unlock the power of OpenAI embeddings through few-shot and zero-shot learning.
Table of Contents
- What are OpenAI Embeddings?
- Few-Shot Learning with OpenAI Embeddings
- Zero-Shot Learning with OpenAI Embeddings
- Potential Applications
- Conclusion
What are OpenAI Embeddings?
OpenAI embeddings are vector representations of words, phrases, and even longer text snippets generated by the OpenAI GPT-4 model.
These embeddings are generated by feeding the text into the model, and the model generates a high-dimensional vector that captures the meaning of the input text.
OpenAI embeddings have several advantages over a traditional one-hot encoding of text data, such as capturing the meaning of similar words and phrases, which can help improve the accuracy of natural language processing models.
Few-Shot Learning with OpenAI Embeddings
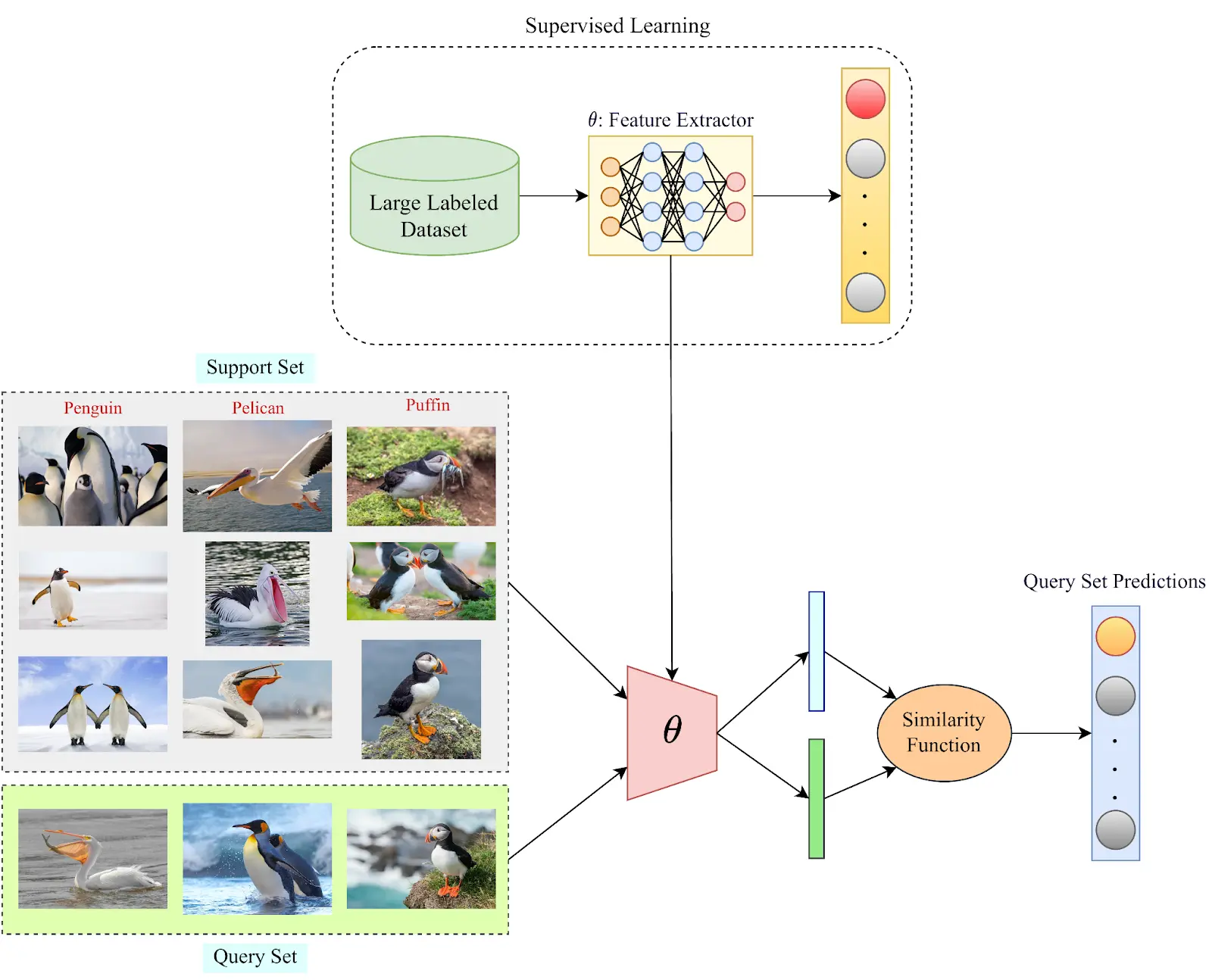
Figure: Representation of Few-shot Learning
Few-shot learning is a technique for training machine learning models with limited labeled data.
In the case of natural language processing, few-shot learning involves training a model to perform a task, such as text classification or sentiment analysis, with only a small amount of labeled data.
OpenAI embeddings can improve the accuracy of few-shot learning models by providing a more accurate representation of the input text.
To use OpenAI embeddings for few-shot learning, we first need to generate embeddings for the labeled data. We can then train a model, such as a neural network, to classify the text based on these embeddings.
The model can then be fine-tuned using a small amount of labeled data to improve its accuracy.
Zero-Shot Learning with OpenAI Embeddings
Zero-shot learning is a technique for training machine learning models without labeled data. In the case of natural language processing, zero-shot learning involves training a model to perform a task, such as text classification or sentiment analysis, without any examples of the task in the training data.

Figure: Representation of Zero-shot Learning
OpenAI embeddings can perform zero-shot learning by providing a more accurate representation of the input text.
To use OpenAI embeddings for zero-shot learning, we first need to generate embeddings for the input text. We can then use these embeddings to perform a task, such as text classification or sentiment analysis, without labeled data.
This is achieved using the embeddings to compute a similarity score between the input text and predefined categories or labels. The category or label with the highest similarity score is then assigned to the input text.
Potential Applications
Few-shot and zero-shot learning systems have numerous potential use cases across various industries. Here are a few examples:
Text classification
Few-shot and zero-shot learning systems can be used for text classification tasks, such as spam filtering, sentiment analysis, and topic classification.
In spam filtering, a few-shot learning system can be trained on a small set of labeled data to identify spam emails. In contrast, a zero-shot learning system can classify new, previously unseen emails as spam or not spam based on their content.
To use OpenAI's GPT model embeddings in text classification, we must fine-tune the model on a specific task, such as sentiment analysis or topic classification, by training it on a smaller labeled dataset.
Once fine-tuned, the model generates embeddings for new examples by extracting the output of one of the intermediate layers of the neural network, which captures the meaning and context of the input text in a high-dimensional vector space.
Few-shot learning involves training the fine-tuned model on a small number of labeled examples for each class, adjusting its weights to better discriminate between the different classes based on the few examples it has seen.
In contrast, zero-shot learning uses the pre-trained embeddings directly without any fine-tuning.
To classify a new example, we compare its embeddings to a set of predefined class embeddings generated by averaging the embeddings of a set of labeled examples for each class.
Chatbots
Few-shot and zero-shot learning systems can be used to improve the performance of chatbots. A chatbot trained using few-shot learning can quickly adapt to new user queries with a small amount of labeled data.
In contrast, a zero-shot learning system can understand new user queries without prior training data.
OpenAI's embeddings through few-shot and zero-shot learning have the potential to improve chatbots by enabling them to understand better and respond to natural language.
Using the pre-trained GPT models to generate embeddings, chatbots can develop a more nuanced understanding of the context and meaning of user inputs, leading to more accurate and appropriate responses.
Few-shot learning can help chatbots adapt to new topics or contexts with only a small amount of labeled data, allowing them to incorporate new information and improve their responses quickly.
Zero-shot learning can also help chatbots classify user inputs without explicit labeling, making them more flexible and adaptable to new situations.
Image recognition
Few-shot and zero-shot learning systems can be used for image recognition tasks, such as object detection and image segmentation.
A few-shot learning system can quickly adapt to new objects with a small amount of labeled data, while a zero-shot learning system can recognize new objects without prior training data.
OpenAI's embeddings through few-shot and zero-shot learning have been primarily used for natural language processing tasks, but they can also be applied to improve image recognition.
Using the embeddings generated by pre-trained GPT models, we can extract features from images and use them to classify and identify different objects.
Few-shot learning can be particularly useful for improving image recognition by enabling the model to learn from a small number of labeled examples.
For example, suppose we want to train a model to recognize a new type of animal. In that case, we can provide it with a few labeled images and use few-shot learning to fine-tune the pre-trained model to better discriminate between the new animal and other similar animals.
Zero-shot learning can also be applied to image recognition using the pre-trained embeddings directly without fine-tuning.
In this case, the embeddings can be used to identify and classify objects based on their similarity to the embeddings of known objects, even if the model has not been explicitly trained on them.
Recommendation systems
Few-shot and zero-shot learning systems can be used to improve the accuracy of recommendation systems.
A few-shot learning system can quickly adapt to new user preferences with a small amount of labeled data. In contrast, a zero-shot learning system can recommend new items to users without prior training data.
OpenAI's embeddings through few-shot and zero-shot learning can improve recommendation systems by enabling them to understand user preferences better and make more accurate and personalized recommendations.
In a few-shot learning scenario, we can train a fine-tuned model on a small number of labeled examples for each user or item, adjusting its weights to better discriminate between the different preferences based on the few examples it has seen.
This can help the model learn more quickly and effectively from new data, leading to more accurate recommendations for individual users.
Zero-shot learning can also be applied to recommendation systems using the pre-trained embeddings without fine-tuning.
In this case, the embeddings can be used to identify and classify items based on their similarity to the embeddings of previously rated or recommended items, even if the model has not been explicitly trained on them.
Translation
Few-shot and zero-shot learning systems can be used for translation tasks, such as machine and document translation.
A few-shot learning system can quickly adapt to new languages with a small amount of labeled data. In contrast, a zero-shot learning system can translate new languages without prior training data.
In few-shot learning scenarios, we can fine-tune a pre-trained model on a small amount of labeled data for each language pair, allowing it to adapt to new languages and improve its translation accuracy quickly.
This can be particularly useful for translating low-resource languages with limited training data available.
Zero-shot learning can also be applied to machine and document translation using the pre-trained embeddings directly without fine-tuning.
By comparing the embeddings of the source and target languages, we can identify and translate words and phrases even if the model has not been explicitly trained on them.
Overall, few-shot and zero-shot learning systems can be used in various industries to improve the accuracy and efficiency of machine learning models, making them valuable tools for businesses and organizations.
Conclusion
n conclusion, OpenAI embeddings are vector representations of words, phrases, and text snippets generated by the OpenAI GPT-4 model.
They offer several advantages over traditional one-hot encoding of text data, such as capturing the meaning of similar words and phrases, leading to more accurate natural language processing models.
OpenAI embeddings can be used for few-shot and zero-shot learning in natural language processing tasks.
Few-shot learning involves training a model with limited labeled data, while zero-shot learning trains a model without labeled data.
OpenAI embeddings can provide a more accurate representation of the input text, improving the accuracy of both few-shot and zero-shot learning models.
Few-shot and zero-shot learning systems have numerous potential applications, including text classification, chatbots, and image recognition.
OpenAI's embeddings through few-shot and zero-shot learning have the potential to improve these applications, enabling them to better understand and respond to natural language, adapt to new topics or contexts, and recognize new objects with small amounts of labeled data.
Book a Demo with our sales team at Labellerr to see how these models can help you to accelerate training data generation process and improve the quality of output.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
