

A practical guide on image labeling in computer vision


The images that are used to develop, verify, and evaluate any algorithms for computer vision will have a big impact on how well your AI project turns out.
To teach an AI algorithm to recognize items similarly to how a person can, every image in your collection must be carefully and precisely tagged.
The machine learning models will likely perform better if image labeling is of higher quality.
Performing Image labeling in accordance with the required criteria might be difficult, which can hold down the project and, as a consequence, the speed to market, even if the quantity and variety of the image data are probably increasing every day.
Consideration should be given to the decisions you make regarding your image labeling methods, resources, and personnel.
In this blog, we have provided you with a practical guide that will help you understand Image labeling in Computer Vision
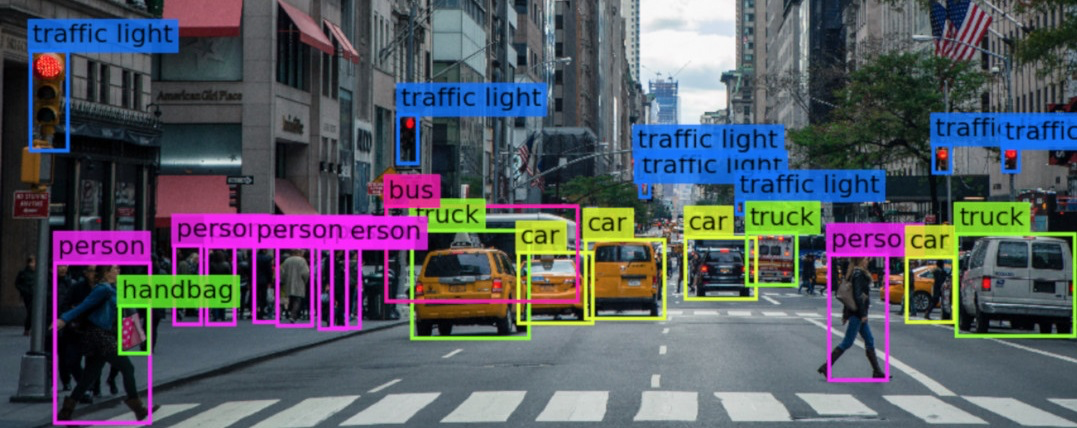
Image labeling: What is it?
Data labeling that focuses on recognizing and tagging certain details in images is known as Image labeling.
Data labeling in computer vision is adding tags to unprocessed data, including photos and videos. An associated object class with the data is represented by each tag.
Labels are used by supervised machine learning algorithms to identify a particular object class in unstructured data. It enables these models to give meaning to the data, which aids in model training.
Data sets for computer vision algorithms are produced using image labeling and are divided into training and test/validation sets.
The training set is used to train the model initially, while the test/validation set is used to assess the model's performance. The dataset is used by data scientists to train and test their models, after which the models may automatically categorize hidden unlabeled data.
Why is image labeling crucial for machine learning and AI?
A crucial step in creating supervised models having computer vision abilities is image tagging. Machine learning models can be trained to label complete images or recognize groups of items within an image.
Image tagging is beneficial in the following ways:
- Image labeling tools and approaches aid in highlighting or capturing specific things in an image, assisting in the development of useful artificial intelligence (AI) models. Machines can now understand photographs thanks to these labels, and highlighted images are frequently used as training sets for machine learning and artificial intelligence models.
- Enhancing computer vision—by enabling object recognition, image labeling, and annotation aid to enhance computer vision accuracy. Machine learning and artificial intelligence models can recognize patterns before they can detect and recognize them on their own by being trained with labels.
Image identification algorithms are a core component of computer vision systems. These algorithms analyze images to detect, classify, and recognize objects or patterns. They rely heavily on accurately labeled images to learn the visual features that distinguish one object from another. Without precise image labeling, these algorithms struggle to understand the context and details within images, leading to poor performance.
Common image identification algorithms include convolutional neural networks (CNNs), which excel at recognizing complex patterns in images. These models require large, diverse, and well-annotated datasets to generalize effectively. By providing detailed labels such as object boundaries, categories, and attributes, image identification algorithms can learn to identify objects in various environments and lighting conditions.
Incorporating high-quality labeled data enhances the accuracy and reliability of image identification algorithms, enabling applications like autonomous driving, facial recognition, and medical imaging. Thus, investing in robust image labeling processes is essential to unlock the full potential of these algorithms in real-world AI solutions.
Different types of Image labeling for computer vision
One of the main purposes of computer vision algorithms is image tagging. Here are several techniques used by computer vision systems to tag images.
Automated labeling is the ultimate objective of machine learning algorithms, but then in order to train a model, it needs a sizable dataset of previously labeled images.

1. Classification of Images
When given images as input, image classification algorithms can automatically categorize them into one of several classifications (also known as classes).
For instance, an algorithm may be able to categorize images of vehicles into groups with names like "car," "train," or "ship."
The same image may have many labels in various circumstances. This might happen, as in the previous example, if a single photograph incorporates various vehicle kinds.
Generating training data for image classification
It is important to manually review images and mark them with labels utilized by the algorithm to produce training data for image classification.
In the case of training data for transportation-related photographs, a person would be in charge of looking at each image and assigning the proper label—"car," "train," "ship," etc.
2. Segmentation
Under segmentation, there are two categories such as:
Semantic segmentation

A computer vision system is concerned with semantic picture segmentation, which involves distinguishing various objects in an image from the backdrop or other objects.
This normally entails mapping out the image's pixels, giving each one a number of 1 if it corresponds to the important object and a value of 0 otherwise.
The conventional method for handling many items in the same image is to construct separate pixel objects for each object and combine them channel-wise.
Instance Segmentation

The process of instance segmentation keeps track of and counts the number, size, shape, and number of objects in a picture. The term "object class" is also used to describe this kind of image annotation.
The number of spectators in the stadium might be calculated using instance segmentation and labeling using the same sample images of a sporting event as before.
Each pixel within the outline is labeled while performing semantic or instance-based pixel-wise segmentation. In boundary segmentation, just the border dimensions are counted, thus you can also carry them out.
Generating training data for Segmentation
It is important to manually review photos and outline the boundaries of pertinent objects in order to produce training data for the semantic segmentation dataset. This generates a pixel map that has been human-validated and can be utilized for the model's training.
3. Object Detection
An object detection algorithm's aim is to locate an object in the image and identify it. Bounding boxes are often used to specify an object's location. The narrowest rectangle that encompasses the entire object depicted in the image is called a bounding box.
A bounding box technically refers to a collection of four coordinates that are associated with a label that identifies the object's class. Typically, bounding box coordinates and labels are kept in a JSON file by using a dictionary format. The dictionary file's key is the image ID or number.
How Labellerr can help you?
Labellerr offers a smart feedback loop that automates the processes that help data science teams to simplify the manual mechanisms involved in the AI-ML product lifecycle. We are highly skilled at providing training data for a variety of use cases with various domain authorities.
By choosing us, you can reduce the dependency on industry experts as we provide advanced technology that helps to fasten processes with accurate results.
A variety of charts are available on Labellerr's platform for data analysis. The chart displays outliers if any labels are incorrect or to distinguish between advertisements.
We accurately extract the most relevant information possible from advertisements—more than 95% of the time—and present the data in an organized style. having the ability to validate organized data by looking over screens.
If you want to know more such related information, then connect with labellerr.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
