

7 Best Audio Annotation & Labeling Tools In 2026
Discover the top 7 audio annotation tools for AI and machine learning. Compare features, use cases, and benefits to find the perfect solution for speech recognition, sound classification, and advanced audio analysis.


Introduction
Audio annotation plays a pivotal role in enhancing machine learning algorithms, enabling better comprehension and analysis of sound-based data across various fields such as speech recognition, natural language processing, and acoustic analysis. The process involves meticulously labeling and categorizing audio segments to facilitate machine learning models in deciphering and extracting meaningful insights.
As the demand for comprehensive audio analysis continues to surge, the need for efficient and versatile audio annotation tools becomes increasingly apparent. In this blog, we'll explore and analyze seven of the most advanced and specialized audio annotation tools available in the market today. Each tool has been meticulously selected based on its distinctive features, user-friendliness, industry applications, and the ability to provide precise annotations across diverse audio formats.
Whether you're a linguist, researcher, podcaster, or AI enthusiast, this curated list will guide you toward finding the ideal audio annotation tool to suit your specific needs and objectives. So, whether you're aiming to streamline annotation processes, enhance accuracy, or delve into intricate acoustic analysis, this blog serves as your comprehensive resource for top-tier audio annotation tools.
Table of Contents
- Labellerr
- SuperAnnotate
- ELAN (EUDICO Linguistic Annotator)
- Praat
- Anvil
- TapeWrite
- MPEG-7 Audio Annotator
- Conclusion
- FAQ
Top 7 Audio Annotation Tools
1. Labellerr
Labellerr is an audio annotation tool designed to assist in the labeling and annotation of audio data, often used in machine learning and AI model training.
Labellerr Audio Annotation Tool
Key Features
Here are some aspects that make Labellerr a beneficial tool:
(i) Ease of Use: Labellerr offers a user-friendly interface allowing annotators to label audio data efficiently. Its intuitive design often includes simple drag-and-drop functionalities, making the annotation process more straightforward.
(ii) Versatility: The tool usually supports various audio formats((MP3, WAV, FLAC, etc.), enabling users to annotate different types of audio data such as speech, music, environmental sounds, etc. This versatility is essential for diverse machine learning and AI applications.
(iii) Labeling Capabilities: Labellerr provides annotation features that allow users to add labels, timestamps, and other relevant metadata to the audio segments. This labeling is crucial for supervised machine learning tasks, enabling models to learn from labeled data.
(iv) Collaboration and Teamwork: Often, Labellerr offers collaborative functionalities, allowing multiple annotators or team members to work simultaneously on the same project. This feature helps streamline the annotation process and improve productivity.
(v) Integration and Compatibility: Labellerr offers integration with other tools or platforms, allowing seamless import/export of data and compatibility with different machine learning frameworks or systems.
(vi) Versioning and History Tracking: Labellerr maintains a history of annotations, enabling version control, and allowing users to track changes to the annotated audio.
(vii) Security and Privacy: Labellerr ensures the protection of sensitive audio data through encryption, user access controls, and compliance with privacy regulations.
(viii) Scalability and Performance: Handles 50,000+ audio files monthly without slowdowns – ideal for large projects and maintain performance even with the increased workload.
Use cases for Labellerr:
Speech Recognition: Labellerr can assist in labeling audio data for speech recognition models, helping them learn and improve accuracy in transcribing speech into text.
Sound Classification: It's useful for annotating audio samples for sound classification tasks, such as identifying different types of sounds (e.g., footsteps, car horns, bird calls) within a dataset.
Sentiment Analysis: In applications like customer service or market research, Labeler can help annotate audio data for sentiment analysis, identifying emotions or tones in spoken language.
Training AI Models: Labeler plays a vital role in training and fine-tuning various AI models that use audio data as input, including applications in natural language processing, audio generation, and more.
2. SuperAnnotate
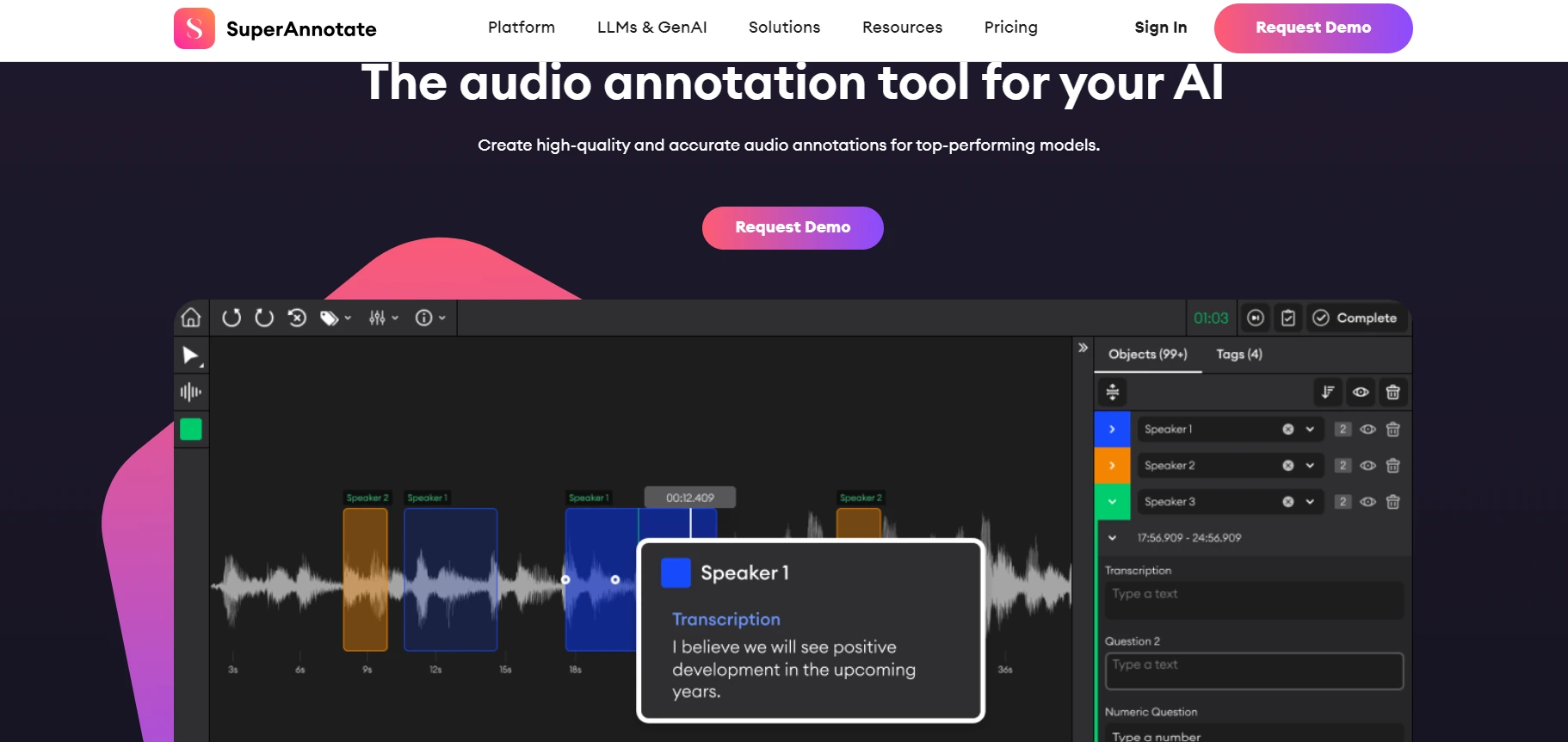
SuperAnnotate
SuperAnnotate's audio annotation tool is a comprehensive and advanced platform designed to create high-quality and precise annotations for various audio file types. It supports a wide range of audio file formats, catering to different industries and use cases. The tool is equipped with advanced features tailored for annotating audio data, making it a versatile solution for diverse applications.
Key Features and Capabilities:
(i) Audio File Compatibility: SuperAnnotate's tool supports all common audio file types and formats, ensuring compatibility and usability across different audio sources.
(ii) Use Case Coverage: It covers a broad spectrum of use cases, including but not limited to:
- Speech Recognition: Transcribing audio recordings to train speech recognition models.
- Speaker Recognition: Annotating rhythm and intonation for speaker recognition models.
- Sound Event Detection: Identifying and classifying specific sounds within audio recordings.
- Audio Classification: Categorizing audio files based on their content and characteristics.
(iii) Industry Applications: SuperAnnotate caters to various industries, including agriculture, healthcare, insurance, sports, robotics, autonomous driving, aerial imagery, NLP, security, and surveillance.
(iv) Built-in Quality Assurance: The tool emphasizes quality with features such as:
- Collaboration System: Involving stakeholders in the annotation quality review process through comments for seamless collaboration.
- Item and Project Status: Tracking and monitoring the progress of items and projects.
- Detailed Instructions: Providing comprehensive project instructions to ensure successful execution.
(v) Innovative Solutions: SuperAnnotate offers innovative solutions tailored to specific industries and use cases, providing annotation software, annotation services through a global marketplace, and project and quality management tools.
(vi) Comprehensive Support: The platform covers various data types, allowing users to create top-quality training data across different formats. It also provides access to a global marketplace of annotation service teams and tools for managing project performance and annotators.
Industry Applications:
SuperAnnotate's tool spans multiple industries, enabling applications in agriculture, healthcare, insurance, sports, robotics, autonomous driving, aerial imagery, NLP, security, and surveillance. Its versatility and adaptability make it a valuable resource for a diverse range of audio annotation needs within these sectors.
3. ELAN (EUDICO Linguistic Annotator)
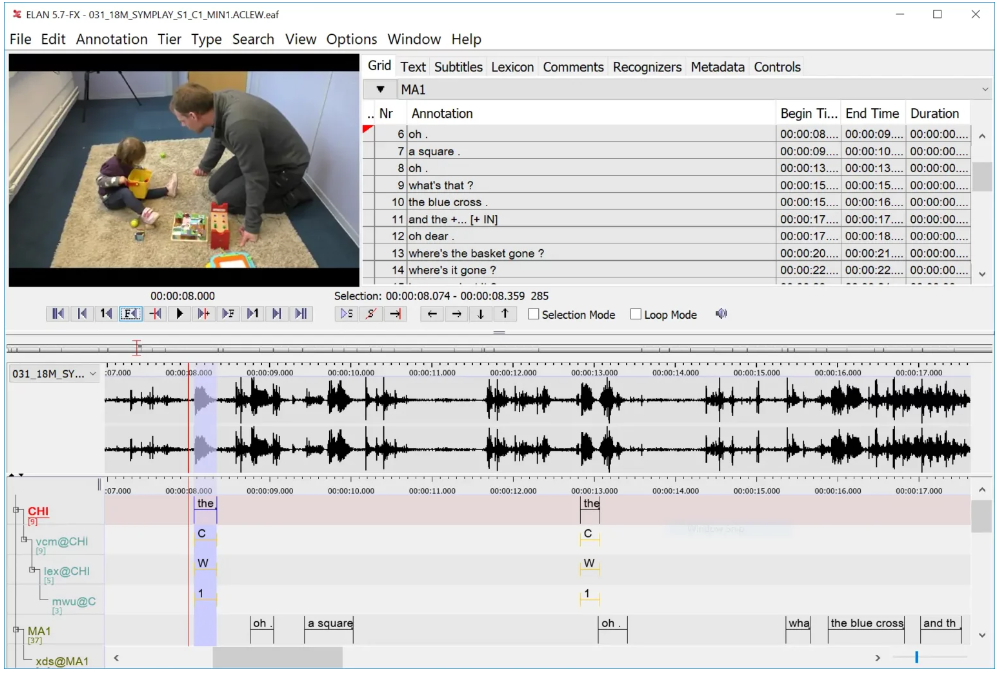
ELAN Audio Annotation Tool
Purpose and Use Cases:
ELAN is primarily designed for linguistic annotation, specifically for researchers and scholars involved in linguistic studies, language documentation, and discourse analysis. It caters to professionals working extensively on detailed linguistic analysis, transcription, and annotation tasks across multiple layers of data.
Key Features:
(i) Linguistic Annotation: ELAN is optimized for annotating speech, language, and gesture data. It offers a comprehensive set of tools and functionalities tailored to linguistic research needs.
(ii) Multi-layer Annotation: Users can create multiple tiers of annotations, enabling annotations at different linguistic or temporal levels. This capability allows for the simultaneous display and alignment of various linguistic elements.
(iii) Time-aligned Annotations: ELAN provides precise time alignment for annotations, ensuring accurate representation and analysis of audio data with respect to the timeline.
(iv) Metadata and Transcription: Users can add metadata, transcriptions, and descriptive information to annotations, providing valuable contextual information essential for linguistic analysis.
(v) Annotation Visualization and Analysis: ELAN offers visualization and analysis tools that allow users to explore relationships between annotations and conduct in-depth linguistic analyses.
(vi) Supported File Formats: ELAN supports various audio and video formats, ensuring flexibility in importing and annotating different types of media.
4. Praat
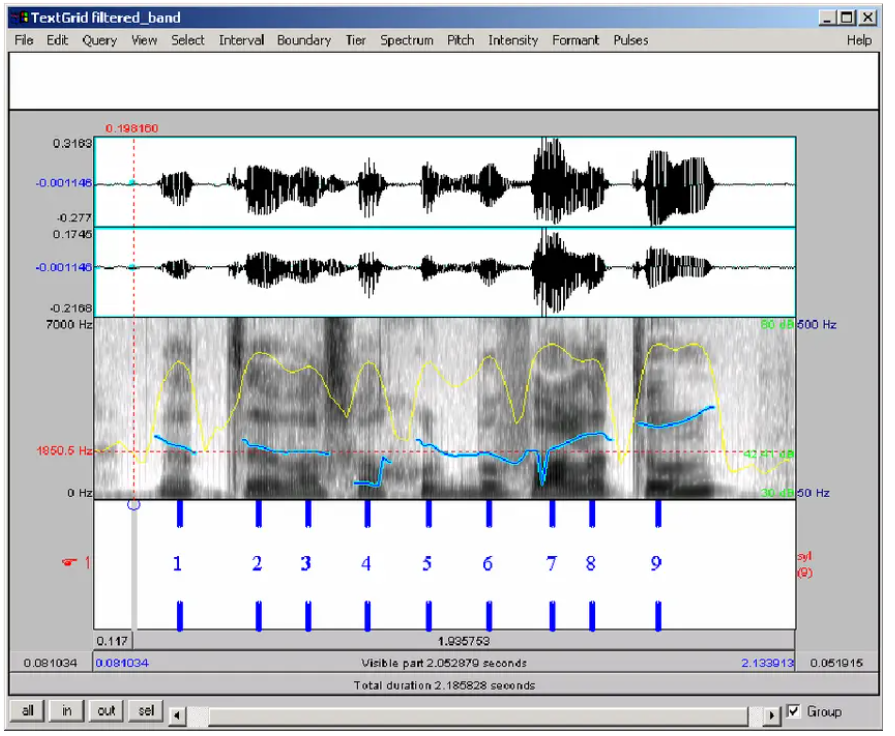
Praat Audio Annotation Tool
Purpose and Use Cases:
Praat is a versatile tool catering to phoneticians, linguists, and researchers primarily engaged in phonetics, speech analysis, and acoustic measurements. It's widely used for detailed phonetic analysis, acoustic measurements, and speech signal processing.
Key Features:
(i) Speech and Phonetics Annotation: Praat provides specialized tools for speech and phonetics analysis, facilitating annotation features for audio recordings and linguistic analysis with a focus on phonetic elements.
(ii) Waveform and Spectrogram Visualization: It offers visual representations of audio waveforms and spectrograms, aiding in detailed analysis and annotation of speech sounds and acoustic properties.
(iii) Annotation Types: Praat supports various annotation types (segment labels, point labels, interval labels, boundary labels) for precise annotation of speech data at different levels, allowing users to mark specific elements within the audio.
(iv) Scripting and Automation: Users can create scripts to automate repetitive annotation tasks or perform advanced analyses, providing flexibility and efficiency in workflow.
(v) Acoustic Analysis: Praat enables users to extract and analyze acoustic features from speech data, facilitating detailed acoustic measurements and analysis.
(vi) Supported File Formats: Praat supports various audio file formats, allowing for the importation and analysis of different types of audio recordings.
5. Anvil
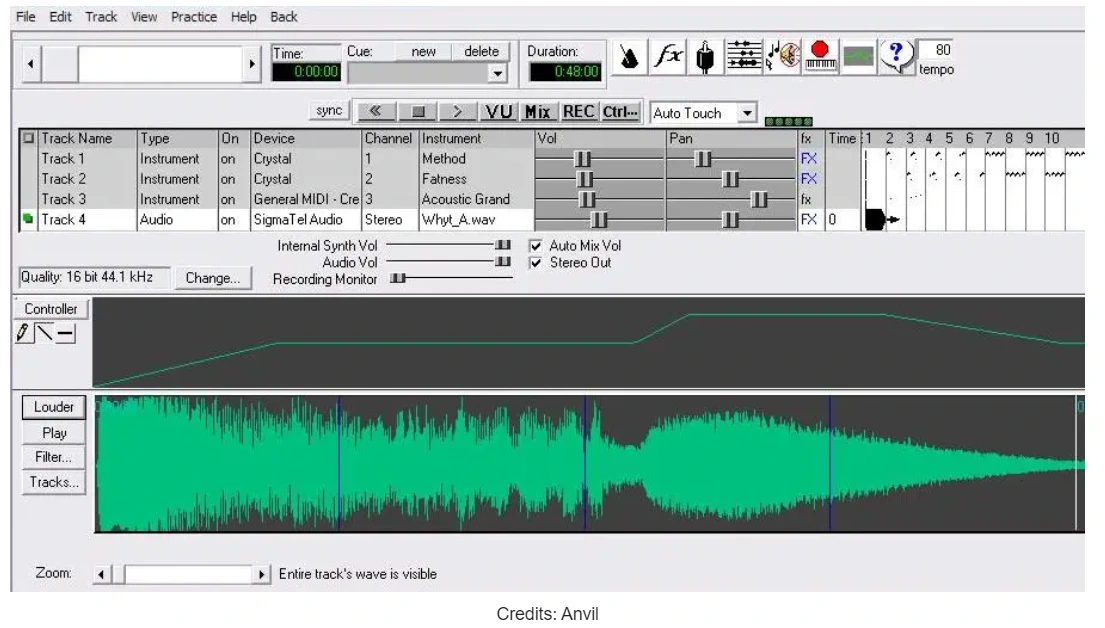
Anvil
Anvil is a multi-modal annotation platform that stands out for its ability to handle both audio and video data, making it a versatile tool for researchers working with multi-sensory content. It's designed to facilitate synchronized annotations, providing an integrated environment for analyzing and annotating audio and video data simultaneously.
Key Features:
(i) Multi-Modal Annotation: Anvil excels in handling multi-modal data, allowing users to annotate both audio and video content concurrently. This capability is particularly valuable for researchers delving into the combined nuances of speech, body language, and environmental cues.
(ii) Synchronized Annotations: Anvil's standout feature is its ability to synchronize annotations between audio and video elements. This synchronization enables users to analyze the correlation between visual cues and spoken words or sounds in a seamless manner.
(iii) Flexible Timeline: The tool offers a flexible timeline interface, allowing researchers to zoom in to analyze short intervals, such as brief pauses or specific linguistic features, or zoom out to study longer segments, like extended dialogues or conversations.
(iv) Export Features: Anvil facilitates the export of annotated data into shareable formats. Researchers can package their findings neatly, making it convenient for presentation or sharing insights with peers or in academic settings.
Benefits and Use Cases:
(i) Enhanced Research Insights: Anvil aids researchers in gaining deeper insights by allowing them to analyze and interpret the interconnectedness of audio and visual cues in multi-modal data.
(ii) Multi-Sensory Data Analysis: It serves as a valuable tool for decoding the complex interactions between spoken language, non-verbal cues, and environmental context captured in video and audio recordings.
(iii) Academic and Research Utility: Anvil is beneficial for academics, researchers, and students exploring fields such as linguistics, communication studies, psychology, and more, where multi-modal analysis is crucial.
Cost:
Anvil is available for free, which makes it accessible to a wide range of users, including students, researchers, and academics, without the barrier of subscription fees.
Overall, Anvil is positioned as a visionary companion, providing a holistic approach to research by enabling users to uncover the intricate stories embedded in the convergence of audio and visual elements within data.
6. TapeWrite
TapeWrite
TapeWrite is a specialized tool tailored for podcast enthusiasts, designed to facilitate the annotation of audio files with text notes. It caters specifically to individuals engaged in podcast-related activities, offering a unique approach to annotating and engaging with audio content, particularly podcasts or lengthy audio segments.
Key Features:
(i) Podcast-Centric Annotation: TapeWrite focuses on the annotation of podcast content, providing a platform that allows users to add text-based notes directly onto specific segments of audio files. This feature aids in creating focused annotations on various topics discussed within the podcast.
(ii) Text-Based Notes: Users can create text-based annotations or notes linked to particular parts of the audio, enabling a more detailed and structured approach to understanding and engaging with the content.
(iii) Streamlined Playback Options: The tool likely offers playback features tailored for podcast consumption, allowing users to navigate through the audio segments efficiently while referring to their annotated notes.
Benefits and Use Cases:
(i) Segmented Annotations: TapeWrite enables users to create specific annotations or notes for different topics or segments within podcasts. This feature is beneficial for academic studies involving podcasts, allowing for a more organized and topic-specific approach to annotation.
(ii) Interactive Playback: The interactive playback options likely enhance the engagement with the content, allowing users to revisit specific parts of the podcast easily while referring to their annotations.
(iii) Collaborative Studies: The ability to create shareable notes fosters collaborative academic studies, facilitating discussions and knowledge-sharing among peers or researchers.
Cost:
The specific pricing or cost details for TapeWrite are not provided in the summary. It's advisable to check the platform's website or contact their support for the most current information regarding pricing plans or available subscription models.
TapeWrite is positioned as a valuable tool for podcast enthusiasts, academics, or researchers dealing with podcast content. By allowing text-based annotations linked to specific segments of audio files, it offers a focused and structured approach to engaging with podcasts. Its emphasis on segmented annotations, interactive playback, and shareable notes makes it suitable for academic pursuits involving podcasts, facilitating a more organized and collaborative study of audio content.
7. MPEG-7 Audio Annotator
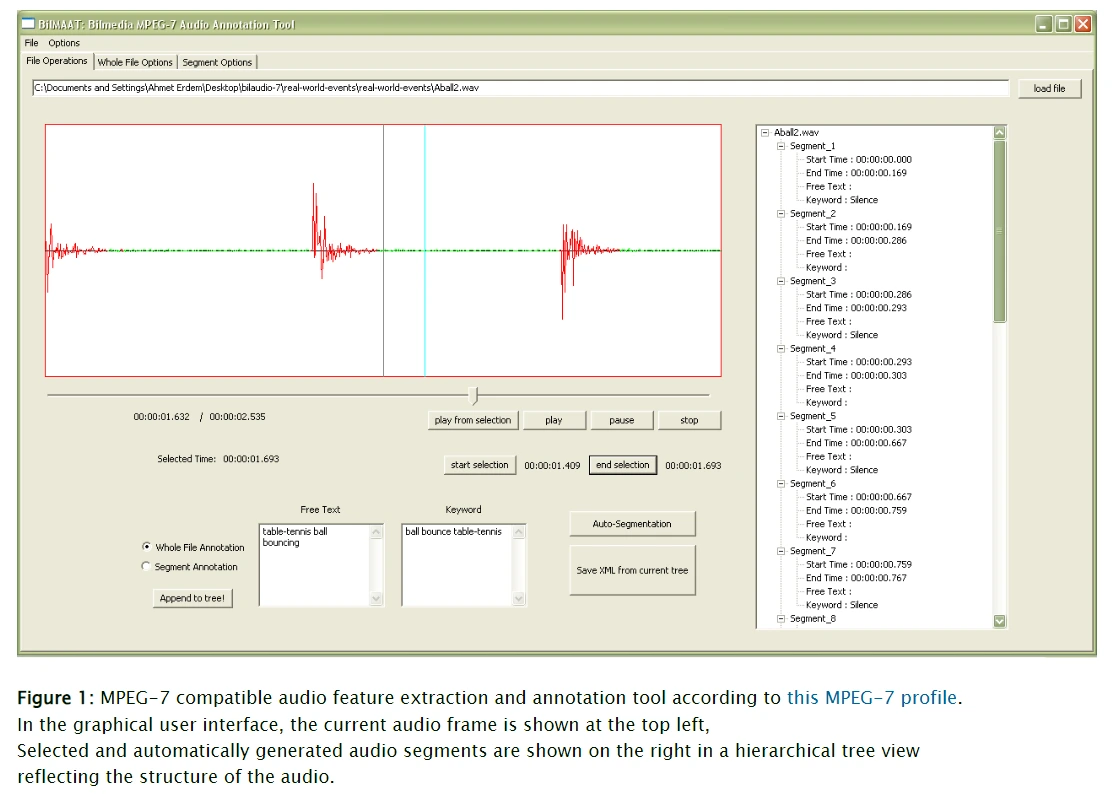
MPEG-7 Audio Annotator
The MPEG-7 Audio Annotator is a specialized tool that harnesses the MPEG-7 audio standards, offering advanced capabilities for creating detailed audio descriptors. It's designed to cater to academics and researchers who require in-depth audio metadata analysis for their studies and research projects. The tool provides a comprehensive platform for unraveling intricate layers of audio details with precision, making it an indispensable resource for those needing nuanced audio analyses.
Key Features:
(i) MPEG-7 Audio Standards: The tool operates based on the MPEG-7 audio standards, enabling the creation of advanced audio descriptors according to these standardized specifications.
(ii) Advanced Audio Descriptors: It facilitates the generation of highly detailed audio descriptors, allowing researchers to delve deeply into the characteristics and features of audio segments.
(iii) Intricate Audio Metadata Tasks: Suitable for tasks requiring detailed and standardized audio metadata analysis, the tool aids in obtaining precise insights into the content and characteristics of audio data.
(iv) Standardized Annotations: The tool ensures compatibility and consistency in annotations, allowing researchers to adhere to established standards for describing audio content.
(v) Intuitive Interface: The tool likely offers an intuitive user interface, streamlining the annotation process and making it easier for users to navigate and manipulate audio descriptors.
Detailed Functionality:
The MPEG-7 Audio Annotator operates by utilizing an MPEG-7 feature extraction library adapted from MPEG-7 XM Reference Software. It allows users to load audio files along with segment information and manually process these segments to obtain MPEG-7 representations. Users can select segments and annotate them with free text, keywords, and structured annotations.
The tool computes various types of audio descriptors, including basic descriptors, basic spectral descriptors, basic signal parameters, temporal timbral descriptors, spectral timbral descriptors, and spectral basis representations. Users can choose a subset of these descriptors to describe each type of audio segment.
Benefits and Use Cases:
(i) Highly Detailed Analyses: Researchers can perform nuanced and detailed analyses of audio data, enabling a deeper understanding of audio content and characteristics.
(ii) Standardization: The tool ensures standardized annotations and descriptors, fostering compatibility and consistency in audio metadata analysis across projects and studies.
(iii) Enhanced Academic Research: Ideal for academic research requiring precise and detailed audio metadata insights, contributing to a more comprehensive understanding of audio content.
Cost:
The specific pricing or cost details for the MPEG-7 Audio Annotator are not provided in the summary. For accurate and updated information on pricing plans or availability, it would be advisable to refer to the tool's official website or contact their support.
The MPEG-7 Audio Annotator emerges as a highly specialized tool for academics and researchers seeking to explore intricate audio metadata and descriptors. By adhering to MPEG-7 audio standards and offering a range of detailed descriptors, it provides a platform for in-depth analysis, standardization, and precise understanding of audio content, thereby bolstering academic research in this field.
Dr. Smith, ML Lead at HealthTech Inc., shares:
"We cut model training time by 70% using Labellerr’s collaborative annotation. Its timestamp labels were crucial for detecting heart murmurs in stethoscope recordings."
Read our other listicles:
Conclusion
The array of seven highlighted audio annotation tools, Labellerr, SuperAnnotate, ELAN, Praat, Anvil, TapeWrite, and MPEG-7 Audio Annotator, offer specialized features catering to diverse audio annotation needs.
From user-friendly interfaces and multilayered linguistic annotation to podcast-centric tools and detailed audio metadata analysis, these tools empower researchers, academics, and industry professionals in precise audio labeling and analysis.
Their versatile functionalities facilitate the development of advanced machine-learning models and foster in-depth research across various fields. As pivotal assets in audio analysis and machine learning, these tools significantly contribute to technological advancements and research endeavors.
Frequently Asked Questions
1. What are audio annotations?
Audio annotations involve the meticulous process of labeling and tagging specific segments or features within audio data, providing descriptive metadata or markers to enhance understanding and analysis. These annotations typically encompass a range of information, including labels, timestamps, transcriptions, or other metadata added to audio segments.
By annotating audio data, individuals can delineate distinct elements such as speech, music, sounds, or tones, aiding in supervised machine learning tasks, speech recognition, sound classification, sentiment analysis, and various other applications. Audio annotations serve as crucial reference points for machine learning algorithms, enabling them to learn and extract meaningful insights from labeled audio datasets.
2. What are the best annotation tools?
The top eight annotation tools comprise Adobe Acrobat Pro DC, Labellerr, Annotate, Filestage, zipBoard, ClickUp, PDF Annotator, and Hive. These software applications serve the purpose of annotating documents and monitoring modifications made to them. They are versatile tools used for a multitude of tasks, such as reviewing alterations, monitoring changes, and collaborating on documents effectively.
3. When should you outsource audio annotation?
Scenario 1: Your team lacks ML expertise → Outsource to avoid labeling errors.
Scenario 2: Handling sensitive data (e.g., patient recordings) → Keep annotation in-house for security.
Pro Tip: Use tools like Labellerr’s enterprise plan for hybrid control.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
