

Everything you need to know about AI Model Training
Explore the essentials of AI model training, from data preparation to model selection, hyperparameter tuning, and deployment. Learn key tools, best practices, and challenges to enhance model accuracy and scalability, driving AI innovation and success.

The way we live, work and communicate has been revolutionized by artificial intelligence (AI). AI models are created to automate processes like natural language processing, image recognition, and decision-making that call for human-level intellect.
However, creating an accurate and trustworthy AI model takes a lot of time and money. Model training is an important phase of the AI development process.
In this blog, everything you need to know about AI model training, including its definition, significance, methods, and best practices, will be covered. We'll also go over some of the issues and developments in the training of AI models, as well as how companies may use this technology to spur innovation and expansion.
A Brief Overview of AI Model Training
Huge volumes of data are fed to an AI model during training to educate it on how to complete a particular task. Model training aims to develop a model that can correctly forecast outcomes using fresh data that it has never seen before.
A training dataset is a collection of labeled data that the AI model is exposed to during the model training process. The model adapts its internal parameters to minimize errors and maximize accuracy based on the labeled data. The procedure is repeated until the model's performance satisfies the required level of accuracy.
Several methods, such as supervised learning, unsupervised learning, and reinforcement learning, are used to train AI models. The most popular method is supervised learning, in which the AI model learns to map inputs to outputs based on labeled data.
When labeled data is not available, unsupervised learning is utilized, and the model is trained to find patterns and relationships in the data. Models are trained using reinforcement learning to make decisions based on rewards and penalties.
The accuracy and dependability of the model are established at the crucial stage of AI model training. While appropriate training can lead to erroneous predictions and unreliable results, proper training methods and best practices can considerably enhance the performance of the model.
Importance of Selecting the Right Tools and Following Best Practices
Choosing the appropriate tools and adhering to best practices are essential for effective AI model training.
The effectiveness and efficiency of the training process can be greatly increased with the appropriate tools, and the model's dependability and scalability can be guaranteed with best practices.
The time and effort needed for model training can be greatly decreased by using the appropriate tools, such as well-liked machine learning frameworks like TensorFlow, PyTorch, or Keras.
These frameworks provide pre-built models, libraries, and APIs that streamline model training and speed up testing and prototyping.
The dependability and scalability of the model can be ensured by adhering to best practices, such as employing a carefully curated and diverse dataset, applying data augmentation techniques, and tracking the model's performance. A carefully chosen dataset ensures that the model can generalize to new data and learn from various examples.
Data augmentation methods like flipping, rotating, and cropping can be used by generating additional training examples and minimizing overfitting. By keeping an eye on the model's performance throughout training, problems can be found and fixed before they waste time or resources.
In conclusion, selecting the right tools and following best practices are critical for successful AI model training. These practices can significantly improve the model's efficiency, accuracy, reliability, and scalability, ultimately leading to better outcomes and increased business value.
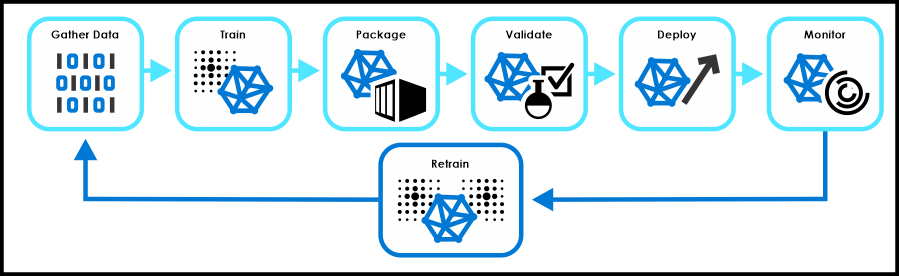
Stages of AI Model Training
AI model training is a complex process that involves several stages, each with its own set of challenges and best practices. The following are the five main stages of AI model training:
Stage 1: Data Collection and Preparation
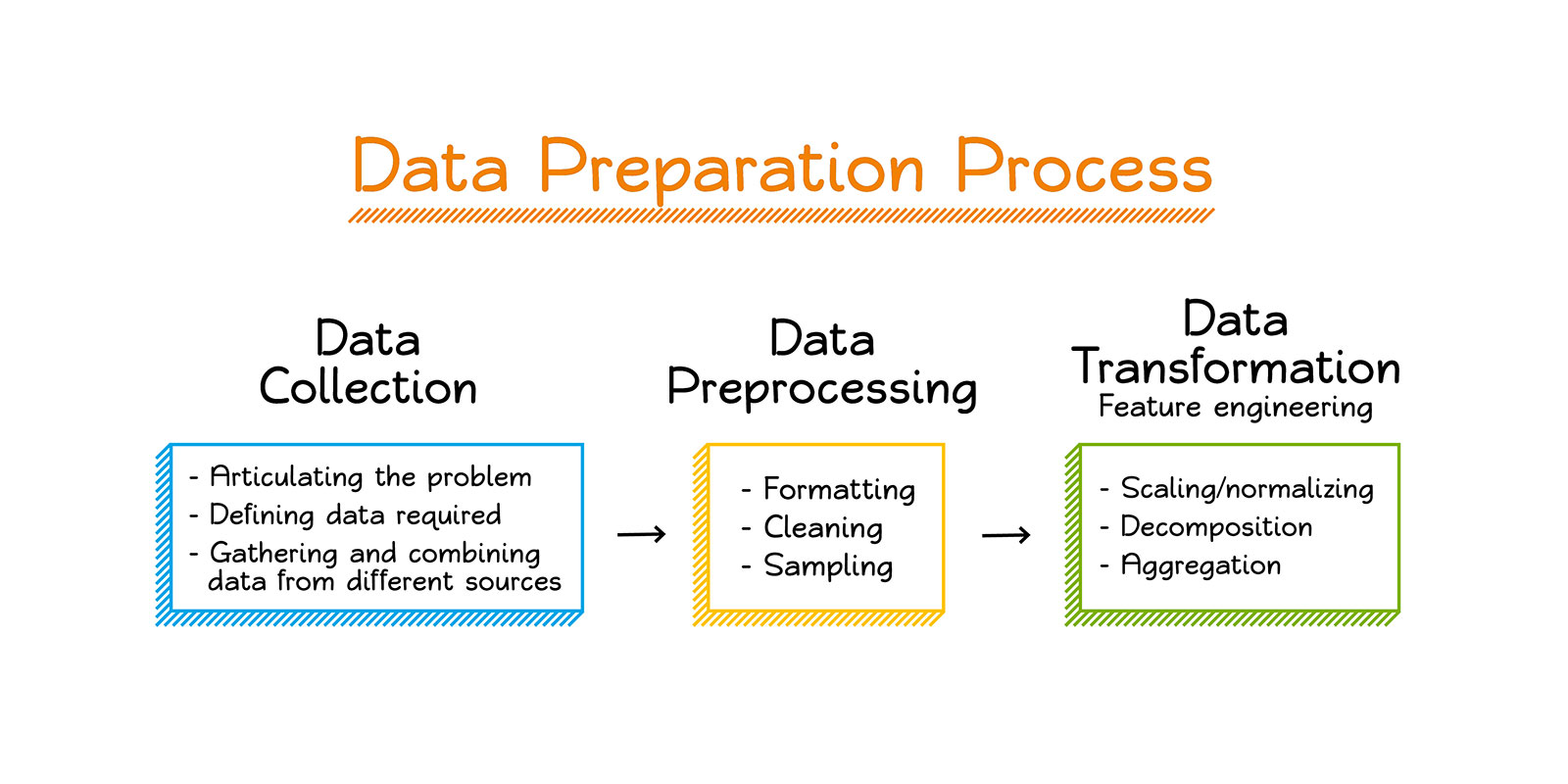
The collection and preparation of data is the initial step in the training of an AI model. The quality and quantity of the training data can considerably impact the accuracy and dependability of the model. Choosing a carefully curated and diverse dataset is crucial at this step, as is cleaning, normalizing, and formatting the data before dividing it into training, validation, and testing sets.
Best Tools
The best tools for this stage include data collection and annotation platforms like Labelbox, Labellerr, Scale AI, or SuperAnnotate, data cleaning tools like OpenRefine, data visualization tools like Matplotlib or Seaborn, and data preprocessing libraries like NumPy or Pandas.
Best Practices
Here are some best practices for data collection and preparation in AI model training:
- The goal should be precisely defined, together with the data needs (format, size, diversity, etc.).
- Gather a wide range of information that reflects the target audience and accounts for various circumstances and variations.
- Make sure the data is accurate by eliminating duplicates, fixing mistakes, and guaranteeing consistency across the dataset.
- Label the data precisely using a clear and consistent labeling methodology to guarantee the correctness and dependability of the model.
- To ensure the model's generalizability and prevent overfitting, divide the data into training, validation, and testing sets.
- To improve resilience and lessen overfitting, augment the data by including variations or creating synthetic data.
- Document the data by noting its source, format, and metadata to assure repeatability and promote data sharing.
- Use data annotation tools like Labelbox or SuperAnnotate to streamline the annotation process and ensure consistency and quality.
- Ensure compliance with data privacy and security guidelines by anonymizing sensitive data, securing the data storage and transmission, and obtaining consent when necessary.
Stage 2: Model Selection and Architecture Design
In this stage, the AI model's architecture and algorithm are selected based on the specific task and dataset. The architecture design involves choosing the number and type of layers, activation functions, loss functions, and optimization algorithms.
Best tools
Best tools for this stage include popular machine learning frameworks like TensorFlow, PyTorch, Keras, or sci-kit-learn, which offer pre-built models and libraries for different tasks and architectures. It is also essential to follow best practices, such as choosing a model that matches the data complexity and size, avoiding overfitting, and using transfer learning when possible.
Best Practices
Here are some best practices for model selection and architecture design in AI model training:
- Select a model that is appropriate for the dataset's complexity and size.
- Overfitting can be avoided by using a simpler model or regularisation approaches.
- Improve performance by utilizing pre-trained models and transfer learning.
- Utilize the proper loss functions and optimization techniques for the given task.
- When building the architecture, consider the model's interpretability and explainability.
- Keep an eye on how the model performs and change the design as appropriate.
- Utilise libraries and frameworks that provide pre-built models and architectures for a variety of activities.
Stage 3: Hyperparameter Tuning
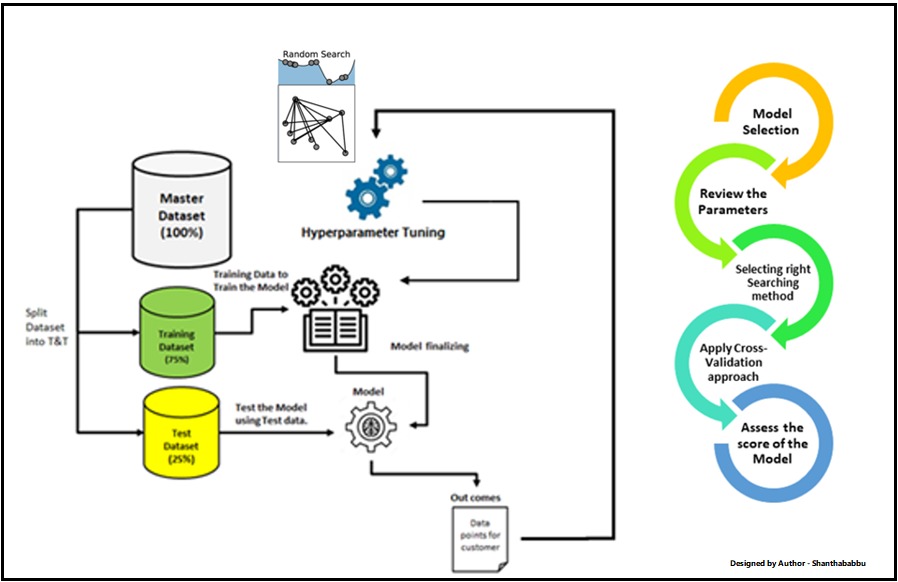
Hyperparameters are the parameters that define the model's architecture and optimization algorithm, such as learning rate, batch size, and regularization. Tuning hyperparameters involves selecting the optimal values that maximize the model's performance.
Best Tools
The best tools for this stage include hyperparameter tuning libraries like Hyperopt, Ray Tune, or Optuna, which use automated algorithms to find the optimal values. It is also essential to use a validation dataset to monitor the model's performance during tuning and avoid overfitting.
Best Practices
Here are some best practices for hyperparameter tuning:
- Make sure that each hyperparameter's range of values is defined and that it is sensible.
- Use a separate validation dataset to assess the model's performance while hyperparameter tuning and preventing overfitting.
- To determine the ideal values, use an automated search algorithm like grid search, random search, or Bayesian optimization.
- To choose the ideal collection of hyperparameters, run numerous experiments with various hyperparameters.
- To improve the model's performance, experiment with various hyperparameters and use those that appear promising.
- Observe how various hyperparameter combinations perform to spot patterns and enhance future adjustments.
- Run numerous trials concurrently to accelerate the hyperparameter tweaking procedure via parallel processing.
Following these best practices can optimize the model's performance and achieve better accuracy and reliability.
Stage 4: Training and Validation
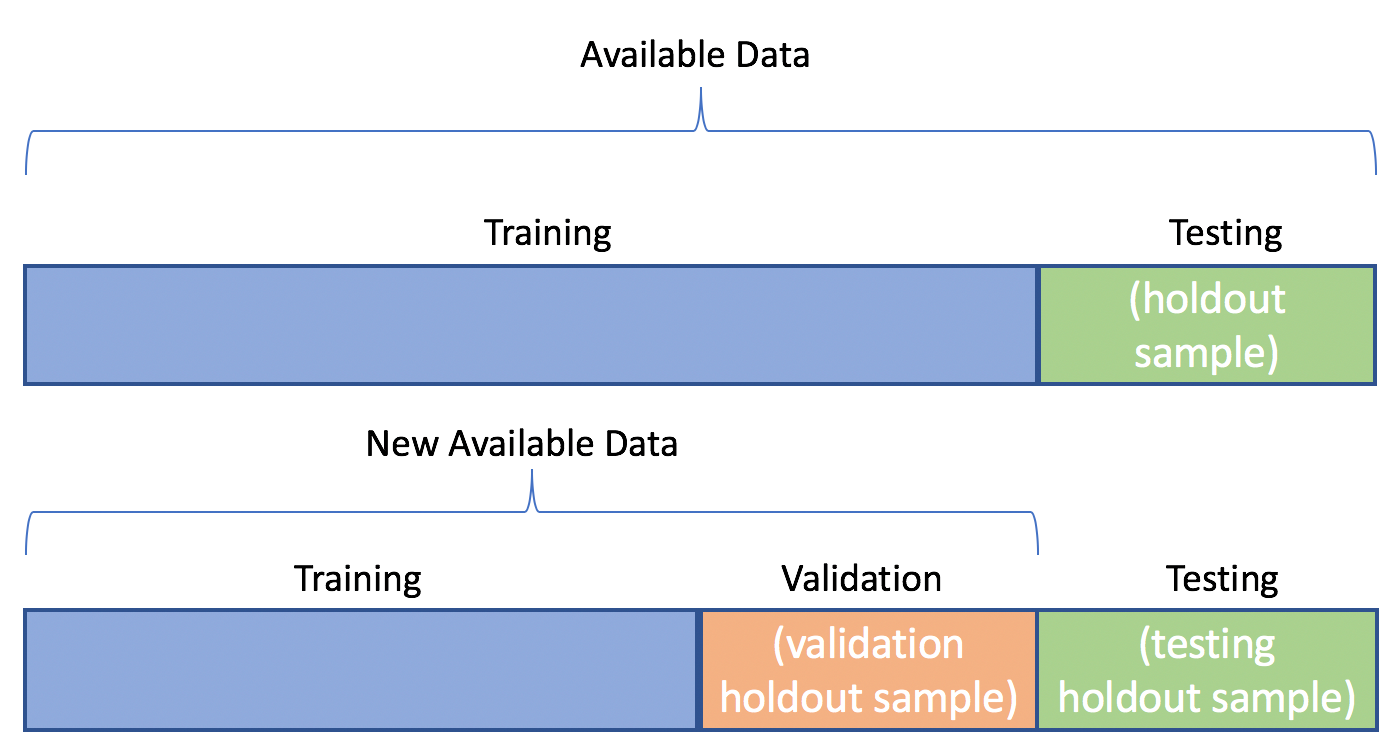
The model is trained on the training dataset using the selected architecture and hyperparameters in this stage. The training process involves feeding the data to the model and adjusting the parameters to minimize errors and maximize accuracy. The validation process involves using the validation dataset to monitor the model's performance and adjust the hyperparameters if necessary.
Best Tools
The best tools for this stage include training frameworks like TensorFlow, PyTorch, or Keras, which offer efficient training algorithms and APIs for monitoring the model's performance.
Best Practices
Some best practices for training and validation in AI model training include:
- Splitting the data into training, validation, and testing sets
- Monitoring the model's performance during training using metrics such as loss, accuracy, and validation error
- Regularly saving checkpoints of the model during training to avoid losing progress in case of crashes or interruptions
- Avoiding overfitting by using techniques such as early stopping, regularization, and dropout
- Using a variety of data augmentation techniques to increase the diversity of the training data
- Tuning the learning rate and other hyperparameters to optimize the model's performance
- Balancing the training data to avoid bias towards one class or feature
- Ensuring that the validation data is representative of the test data to evaluate the model's performance accurately.
Stage 5: Testing and Deployment
The final stage involves testing the trained model on new data to evaluate its performance and deploy it in production. Testing involves using the testing dataset to evaluate the model's accuracy, precision, recall, and F1 score. Deployment involves integrating the model into a production environment and ensuring its scalability, security, and reliability.
Best Tools
The best tools for this stage include testing frameworks like pytest, deployment frameworks like Docker or Kubernetes, and monitoring tools like Prometheus or Grafana.
Best Practices
Here are some best practices for testing and deployment in AI model training:
- Use a dedicated testing dataset to evaluate the model's performance and generalization.
- Conduct both quantitative and qualitative evaluations of the model's performance.
- Monitor the model's performance in production to detect and address any issues.
- Use version control to manage the model's code and configuration files.
- Containerize the model using Docker or other containerization tools to ensure consistency and portability.
- Implement continuous integration and deployment (CI/CD) pipelines to automate testing and deployment.
- Ensure the security and privacy of the model and the data it processes.
- Document the testing and deployment process to facilitate collaboration and knowledge sharing.
By following these best practices, you can ensure that your AI model is reliable, scalable, and secure in production.
Training an AI Model Made Easy: Simple Steps Anyone Can Follow
Training an AI model means teaching a computer to learn from data. It is like teaching a child to recognize things.
Here are easy steps to train an AI model:
- Get Good Data: Find lots of examples that show what you want the AI to learn. For example, pictures of cats and dogs.
- Clean and Label the Data: Make sure the data is correct and clear. Label the pictures as "cat" or "dog" so the AI knows what they are.
- Pick a Model: Choose a AI model that fits your problem.
- Train the Model: Give data to the AI model. It will learn by finding patterns in the data.
- Check the Model: Test the model with new data that it has never seen. See if it guesses right.
- Improve the Model: If the model makes mistakes, give it more data or change settings to make it better.
- Use the Model: When the model works well, use it in real life to help with tasks like recognizing images or understanding text.
Easy Tips for Training an AI Model
- Use clean and clear data. Better data means better results.
- Label everything carefully. The model learns from your labels.
- Start simple. Use simple models first, then try more complex ones if needed.
- Test if your model works well with new data.
- Tools like Labellerr can make labeling and training much easier.
- Ask for feedback. Show your results to others and learn from their suggestions.
By following these easy steps and tips, anyone can start training an AI model and get great results.
Conclusion
Overall, successful AI model training requires careful attention to each stage of the process and the selection of appropriate tools and best practices. The data collection and preparation stage sets the foundation for the model's accuracy and reliability, while the model selection and architecture design stage determines the model's performance. Hyperparameter tuning, training, and validation stages fine-tune the model's performance while testing and deployment ensure its reliability and scalability.
Explore AI & Data Annotation Insights
FAQs
Q1: What is AI model training?
The process of training an artificial intelligence model to learn patterns, recognize characteristics, and make accurate predictions by exposing it to labeled or unlabeled data and optimizing its parameters is referred to as AI model training.
Q2: What is the process of AI model training?
AI model training often entails entering training data into a machine learning algorithm or neural network, optimizing the model's internal parameters (through gradient descent, for example), and repeatedly improving the model's performance across numerous training epochs.
Q3: What are the essential elements of AI model training?
Defining the issue and objectives, preparing and prepping the training data, selecting an appropriate method or architecture, initializing and optimizing the model, and assessing its performance using validation and test datasets are the major components of AI model training.
Q4: What types of data are utilized to train AI models?
A: AI models can be trained to utilize a variety of data sources, such as numerical data, written documents, images, audio recordings, and even video sequences. The type of data used is determined by the application and the sort of information that the model must learn and forecast.
Q5: What are the processes involved in training an AI model?
Data collection and preparation, feature engineering or extraction, model selection, and configuration, training the model on the data, optimizing hyperparameters, and assessing the model's performance using metrics such as accuracy or loss are common processes in AI model training.
Q6: What function does labeled data play in AI model training?
Labeled data is required for supervised learning, which pairs input data with appropriate target labels. Labeled data assists the model in learning patterns and relationships, allowing it to make accurate predictions on previously unknown data.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
