AI KOSMOS-2 Explained: Microsoft’s Multimodal Marvel KOSMOS-2 brings grounding to vision-language models, letting AI pinpoint visual regions based on text. In this blog, I explore how well it performs through real-world experiments and highlight both its promise and limitations in grounding and image understanding.
cvpr CVPR 2025: Breakthroughs in Object Detection & Segmentation CVPR 2025 (June 11–15, Music City Center, Nashville & virtual) features top-tier computer vision research: 3D modeling, multimodal AI, embodied agents, AR/VR, deep learning, workshops, demos, art exhibits and robotics innovations.
Vision Language Model BLIP Explained: Use It For VQA & Captioning BLIP (Bootstrapping Language‑Image Pre‑training) is a Vision‑Language Model that fuses image and text understanding. This blog dives into BLIP’s architecture, training tasks, and shows you how to set it up locally for captioning, visual QA, and cross‑modal retrieval.
SAM SAM Fine-Tuning Using LoRA Learn how to fine‑tune SAM with LoRA to achieve precise, domain‑specific segmentation without massive GPU costs. Freeze the SAM backbone, train only tiny low‑rank adapters, and deploy high‑accuracy models on modest hardware—fast, modular, and efficient.
object tracking OC-SORT Tutorial: Critical Insights You Can’t Miss! OC‑SORT claims improved occlusion and non‑linear motion handling by back‑filling virtual paths and using real detections, but its dependence on detector quality, straight‑line interpolation, and no appearance features can still lead to identity errors in dense or erratic scenes.
highdream Text-to-Image Magic: HiDream-E1's Image Editing Hack In fast-paced fashion, HiDream‑E1 cuts time and cost by using natural language to edit images—change colors, backgrounds, and accessories with pixel-perfect accuracy. Built on a 17B foundation model and Sparse Diffusion Transformer, it's a game-changer for creative workflows.
AI Model 5 Best AI Reasoning Models of 2025: Ranked! Who leads AI reasoning in 2025? Explore how models—OpenAI o3, Gemini 2.5, Claude 3.7 Sonnet, Grok 3, DeepSeek‑R1, AM‑Thinking‑v1 stack up in benchmarks, context window, cost-efficiency, and real-world use cases. Spot the right fit for your next-gen AI project.
object tracking Track Objects Fast: BoT-SORT + YOLO Explained! BoT-SORT boosts multi-object tracking by refining box predictions, compensating for camera motion, and combining motion with appearance cues. Easily integrate it via Ultralytics YOLO or BoxMOT for robust tracking in crowded, dynamic scenes.
ai agent The Rise of AI Agents in Data Labeling Explained AI agents in data labeling pipelines. By combining semi-supervised learning, active learning, and human-in-the-loop workflows, they reduce manual effort by ~50% and cut annotation costs by up to 4×, all while maintaining accuracy above 90%.
minimax MiniMax‑M1: 1M‑Token Open‑Source Hybrid‑Attention AI Meet MiniMax‑M1: a 456 B‑parameter, hybrid-attention reasoning model under Apache 2.0. Thanks to a hybrid Mixture‑of‑Experts and lightning attention, it handles 1 M token contexts with 75% lower FLOPs—delivering top-tier math, coding, long‑context, and RL‑based reasoning.
object tracking Track Crowds in Real-Time with FairMOT - A Detailed Tutorial FairMOT is a real-time, anchor-free tracking system that solves identity switch issues by combining object detection and re-identification in a single network, ideal for crowded scenes, surveillance, sports, and autonomous systems.
Zero-Shot Segmentation Qwen 2.5-VL 7B Fine-Tuning Guide for Segmentation Unlock the full power of Qwen 2.5‑VL 7B. This complete guide walks you through dataset prep, LoRA/adapter fine‑tuning with Roboflow Maestro or PyTorch, segmentation heads, evaluation, and optimized deployment for smart object tasks.
Product Update Product Update: May 2025 You told us you wanted a faster and more organized way to manage your projects, datasets, and API keys. We listened. Today, we are excited to announce a completely redesigned workflow experience. Our May 2025 update introduces a new landing page, a dedicated datasets section, and a secure place to
OpenAI OpenAI O3 Pro: The Most Advanced AI Reasoning Model Yet OpenAI’s O3 Pro delivers unmatched reasoning with real-time web search, vision/file inputs, and Python execution. It’s 10× costlier and much slower than O3, but promising for high‑stakes tasks in science, coding, and research. Is the power worth the price?
object tracking StrongSORT Tutorial: Master Multi-Object Tracking Learn what StrongSORT is, how it improves multi-object tracking, and how to easily implement it in your own projects using modern detectors like YOLO.
object tracking Learn DeepSORT: Real-Time Object Tracking Guide Learn to implement DeepSORT for robust multi-object tracking in videos. This guide covers setup, integration with detectors like YOLO for real-time use.
FVLM Top Vision LLMs Compared: Qwen 2.5-VL vs LLaMA 3.2 Explore the strengths of Qwen 2.5‑VL and Llama 3.2 Vision. From benchmarks and OCR to speed and context limits, discover which open‑source VLM fits your multimodal AI needs.
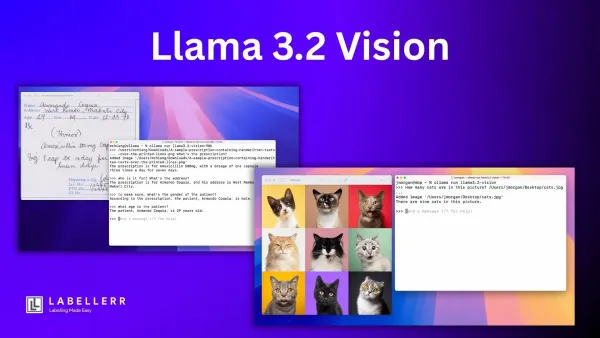
Vision-language models How to Fine-Tune Llama 3.2 Vision On a Custom Dataset? Unlock advanced multimodal AI by fine‑tuning Llama 3.2 Vision on your own dataset. Follow this guide through Unsloth, NeMo 2.0 and Hugging Face workflows to customize image‑text reasoning for OCR, VQA, captioning, and more.
object tracking How to Implement ByteTrack for Multi-Object Tracking This blog shows code implementation of ByteTrack, combining high- and low-confidence detections to maintain consistent object IDs across frames. By matching strong detections first and “rescuing” weaker ones, it excels at tracking in cluttered or occluded scenes.
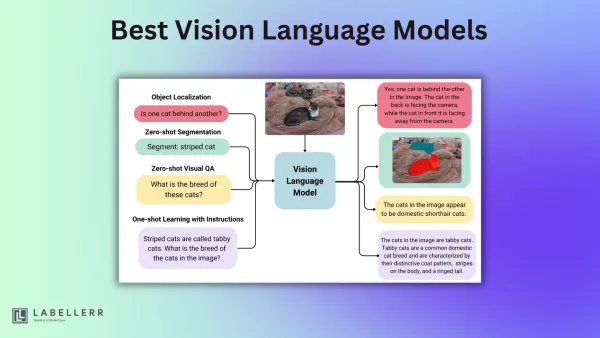
computer vision Best Open-Source Vision Language Models of 2025 Discover the leading open-source vision-language models (VLMs) of 2025 including Qwen 2.5 VL, LLaMA 3.2 Vision, and DeepSeek-VL. This guide compares key specs, encoders, and capabilities like OCR, reasoning, and multilingual support.
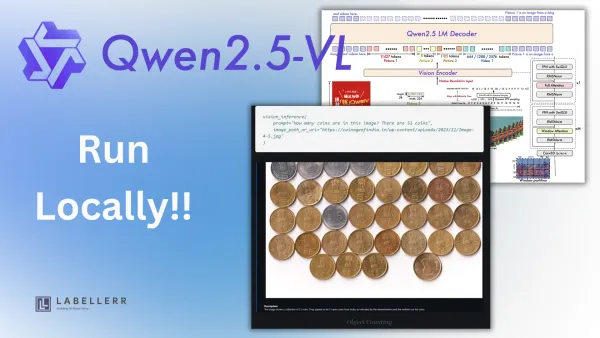
qwen Run Qwen2.5-VL 7B Locally: Vision AI Made Easy Discover how to deploy Qwen2.5-VL 7B, Alibaba Cloud's advanced vision-language model, locally using Ollama. This guide covers installation steps, hardware requirements, and practical applications like OCR, chart analysis, and UI understanding for efficient multimodal AI tasks.
object segmentation MASA Implementation Guide: Track Objects in Video Using SAM MASA revolutionizes object tracking by combining the Segment Anything Model (SAM) with self-supervised matching. Track any object across video frames without category-specific training or manual labels. Learn how MASA works and implement state-of-the-art universal tracking in your projects.
LLAMa A Hands-On Guide to Meta's Llama 3.2 Vision Explore Meta’s Llama 3.2 Vision in this hands-on guide. Learn how to use its multimodal image-text capabilities, deploy the model via AWS or locally, and apply it to real-world use cases like OCR, VQA, and visual reasoning across industries.
Image Segmentation Learn SAM 2 in Minutes: The Ultimate Starter Guide for 2025 Learn to implement Meta's SAM2 for pixel-perfect image/video segmentation. Explore its zero-shot capabilities, real-time processing, and step-by-step code examples for bounding box & point-based object masking.
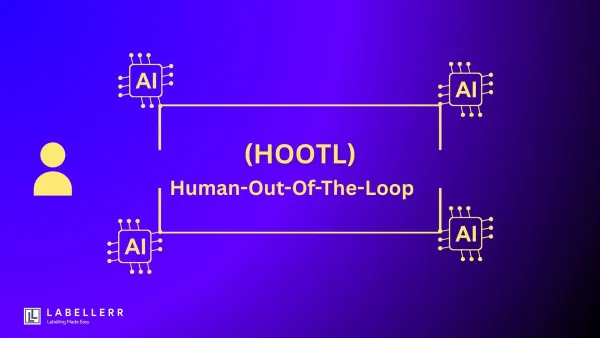
Agent Human-Out-Of-The-Loop: No Humans, No Limits As AI systems become more autonomous, the debate intensifies over the benefits and dangers of removing human oversight. Explore the promise of efficiency and the peril of ethical dilemmas in human-out-of-the-loop AI systems.