computer vision AI Smart Store Analysis Learn how AI is fixing long grocery lines. This project uses YOLO11 to track customers and count items in real-time. By measuring checkout speed and item throughput, this smart monitor helps stores run faster and improves the shopping experience for everyone.
Gemma 4 Google Gemma 4: A Technical Overview Gemma 4 is a powerful open-weight AI model from Google DeepMind, offering multimodal capabilities, high efficiency, and strong benchmark performance across text, code, and reasoning tasks, all with full commercial freedom.
yolo model training 5 Best YOLO Model Training Service Providers in 2026 Discover how to train high-performance YOLO models using optimized datasets and workflows tailored for real-world use cases in India, including traffic, agriculture, and surveillance applications.
Waste Segmentation AI Smart Waste Classifier Discover how AI is solving the global trash crisis. This project uses YOLOv11 and Labellerr to build a Smart Waste Classifier that identifies bottles, bags, and paper with pixel-perfect accuracy. Learn how instance segmentation is making automated, real-time recycling a reality.
AI model training 7 Top AI Model Training Service Providers in 2026 Training AI models is complex, but managed platforms simplify everything from annotation to deployment. Discover the top AI model training service providers in 2026 and find the right platform for your computer vision, LLM, or multimodal workflows.
SAM 3.1 SAM 3.1 vs SAM 3 Faster Video Tracking SAM 3.1 introduces Object Multiplex to eliminate multi-object tracking bottlenecks. By processing multiple objects in a single pass, it delivers up to 7x faster inference and real-time performance without changing the model architecture.
computer vision AI Electronics Detection System Explore how the Raspberry Pi Component Tracker uses YOLOv11 and Instance Segmentation to identify hardware in real-time. This AI system eliminates messy boxes to provide pixel-perfect masks for factory inspection, e-waste recycling, and interactive hardware education.
surveillance AI Mask Detection System Discover how the Smart Face Mask Tracker uses YOLOv11 and persistent sticky logic to solve AI flickering. Learn how this real-time computer vision system ensures accurate, automated safety compliance for hospitals, factories, and public spaces.
egocentric datasets 7 Top Egocentric Data Service Providers for Robotics 2026 Egocentric data is transforming robotics by capturing the world from a robot’s perspective. This guide covers the top 7 providers in 2026 helping teams build accurate, real-world-ready models with high-quality first-person datasets.
robot manipulation 8 Best Video Labeling Tools for Robotics Manipulation 2026 Explore the best video annotation tools for robot manipulation in 2026. Learn how labeling data powers robotics, and compare top platforms for tracking, 3D data, and AI-assisted workflows.
computer vision AI Conveyor Belt Counter: Real-Time Dual-Lane Monitoring Learn how to build a high-precision dual-lane conveyor counter using YOLO11 and ByteTrack. This guide covers how to eliminate manual counting errors, implement spatial partitioning, and use trigger-zone logic to achieve 100% accuracy in high-speed industrial environments.
synthetic data for robotics 7 Top Synthetic Data Platforms for Robotics in 2026 Synthetic data is transforming robotics by enabling scalable, safe, and fully labeled training environments. Discover top platforms powering simulation-driven robot learning in 2026.
human in the loop data labeling 6 Top Human-in-the-Loop Data Services for Robotics 2026 Human-in-the-loop data services help robotics teams train smarter AI by combining automation with human expertise. Discover the top HITL platforms used to label LiDAR, video, and sensor data for warehouse robots, autonomous systems, and humanoid robotics.
computer vision Smart City Infrastructure Analysis using AI Discover how AI and drones are revolutionizing urban planning. Using YOLO 11, we transform raw aerial footage into high-definition maps to track green zone compliance and build sustainable smart cities. See how automated mapping is shaping a greener future for urban development.
teleoperation robotics 7 Top Teleoperation Service Providers for Robotics in 2026 Teleoperation is powering the next generation of humanoid robots. Discover seven companies building the infrastructure for robot training, data pipelines, and human-guided control systems used by leading robotics programs in 2026.
AI cricket analytics AI-Powered Cricket Bowling Analyzer Using Yolo Build an AI-powered cricket bowling biomechanics system using YOLOv8x-Pose. Track shoulder, elbow, and wrist keypoints, calculate elbow angle, measure wrist speed, and visualize the bowling arm arc directly from standard broadcast video.
fitness AI-Powered Deadlift Form Analyser Learn how to build an AI-powered deadlift analysis system using YOLO and computer vision. This guide covers tracking bar paths and biometric "power triangles" to provide real-time, data-driven feedback that prevents injury and optimizes lifting performance through technical precision.
data annotation 7 Top Data Labeling Companies in Robotics 2026 Discover the top data annotation companies for robotics and physical AI in 2026. Compare platforms for egocentric video, LiDAR, and multimodal datasets that help robots learn faster with high-quality training data.
computer vision AI Traffic Analysis: Speed Tracking & Heatmaps using YOLO Discover how to transform standard traffic cameras into intelligent sensors using YOLO AI. This guide explains how to track vehicle speeds in real-time and build dynamic, velocity-weighted heatmaps to identify and solve urban congestion.
robot world model DreamDojo Platform for Scalable Robot Training DreamDojo is a generalist robot world model trained on 44,711 hours of human video. It learns interaction dynamics, enables zero-shot generalization, and supports model-based planning for scalable embodied AI.
Gemini 3.1 Pro Google Gemini 3.1 Pro Review and Analysis Gemini 3.1 Pro is Google’s most advanced reasoning model yet, built for deep agentic workflows, large-scale code generation, and multimodal tasks. With 65K output tokens and major benchmark gains, it shifts AI from conversation to autonomous execution.
SAM 3 Benchmarking SAM and SAM 3 on Aerial Data Compare SAM and SAM 3 for aerial image segmentation. See zero-shot benchmark results across satellite datasets, performance differences, and how to use both models inside Labellerr for faster geospatial annotation workflows.
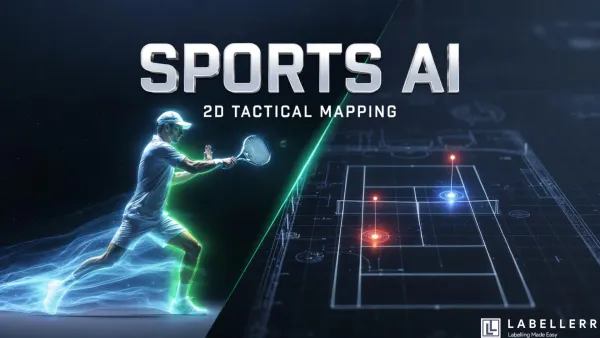
3D Geometry Converting Sports Videos into 2D Tactical Maps with AI Learn how to transform standard sports footage into a professional 2D tactical map. Using YOLO11 and Planar Homography, this project solves perspective distortion to provide real-time player tracking and spatial analytics for coaches and fans.
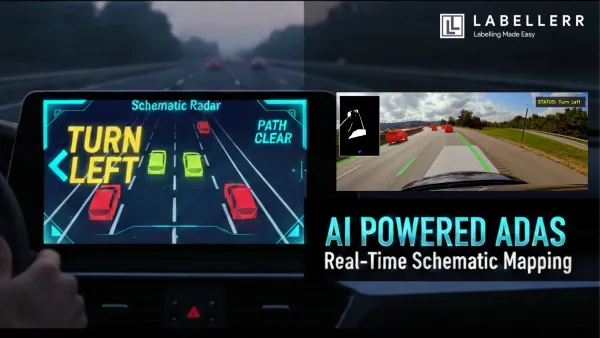
ADAS Building a Real-Time Schematic ADAS with YOLO11x Learn how to build a 4K vision-based ADAS using YOLO11. This guide explains how to track lanes in real time and provide instant safety alerts to help drivers stay in their lanes.
humanoid robot learning VideoMimic: How Robots Learn Human Motion VideoMimic turns monocular human videos into deployable humanoid robot policies. By combining 4D reconstruction, scene geometry, and reinforcement learning, it enables context-aware robot control without motion capture or handcrafted rewards.