

What is data augmentation? Techniques, examples & benefits
Data augmentation enhances machine learning models by creating varied data versions, boosting accuracy, and reducing data collection costs. Common in image recognition and NLP, it leverages techniques like GANs, word swaps, and neural style transfer

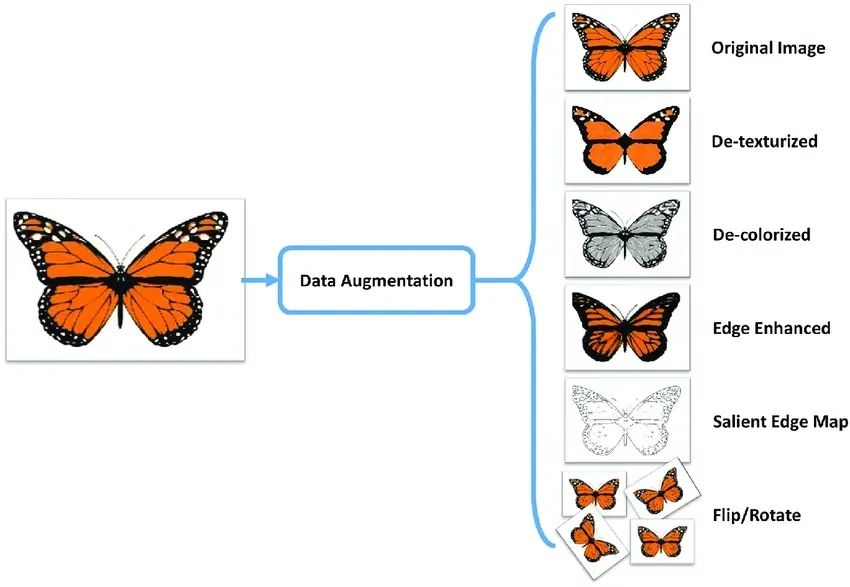
Data is the era's essential core. Every decision in the world is driven by data. But if not properly organized, divided, and chosen, even the data that has been gathered is worthless. The lead in this role is data augmentation. Data augmentation aids in organizing the data by assisting with selection, blending, and highlighting.
The standard, volume, and relevance of training data determine how well most ML models perform, and deep learning algorithms in particular. One of the most frequent problems in applying AI and ML in the workplace, though, is a lack of data. This is because gathering such data can frequently be expensive and time-consuming.
Businesses can use data augmentation to develop faster, more reliable machine learning models while reducing their dependency on the preparation and acquisition of training data.
In this blog, we will discuss data augmentation-its techniques, examples and advantages. Let’s first understand what data augmentation is.
Data augmentation: what is it?
Data augmentation combines the words "augmentation" with "data." It is a widely used method for improving an over fitted data model's generalization. Data analysis includes data augmentation.
By adding changed versions of already existing data, a collection of procedures is utilized to enhance the amount of data. From the existing data, it can occasionally produce newly synthetic data.
Data augmentation helps control over fitting of data by acting as a regularizer. By producing more data for training and presenting the model to various data versions, data augmentation raises the risk of over fitting the model.
You might be curious what over fitting a model actually means.
A function that is strongly aligned to a small number of data points results in an over fitted data model, which is a modeling inaccuracy in the data sequence.
Deep learning applications in particular continue to vary and grow quickly in number. Data augmentation strategies, for example, are data-centric strategies to model creation that might be a useful tool for overcoming obstacles in the artificial intelligence field.
.webp)
How does it function?
Computer vision applications use common data augmentation techniques for training data. There are both simple and intricate data augmentation methods for image recognition and natural language processing.
Data augmentation frequently entails making elementary adjustments to visual data. Additionally, generative adversarial networks are used to generate new synthetic data (GANs). Traditional image processing techniques including padding, re scaling, zooming, translation, and cropping are employed for data augmentation.
In comparison to the computer vision industry, data augmentation is less common in the NLP field. Augmenting textual data is challenging because of the complexity of a language. The following are typical NLP techniques for data augmentation:
- Word insertion, word swapping, word replacement, and word deletion are all straightforward Data Augmentation (EDA) procedures.
- Reversing the translation
- Context-based word embedding
What benefits do data augmentation techniques offer?
One or more of the benefits of data augmentation include the following:
- Enhancing model prediction accuracy
- Increasing the models' training data output
- Reducing the lack of data so that improved models may be created
- reducing data over fitting (an error in statistics where a function too closely connects to a limited data points) and raising data variability
- Reducing the cost of labeling and collecting data
- The models' increasing capacity for generalization
- Assisting in resolving concerns with classification's class imbalance
Our SaaS platform streamlines the process of enhancing training datasets, helping improve model accuracy and reduce overfitting. Sign up today
Significance of data augmentation
The second concern is the significance of data augmentation. Machine learning includes the notion of data augmentation. Machine learning has many variations, and its range of applications is expanding quickly. And data augmentation serves as a way to overcome these difficulties.
It helps machine learning models perform better and produce better results. The methods for data augmentation create information that is rich and sufficient, which improves the performance and accuracy of the model. By injecting transformation into the datasets, data augmentation techniques lower operating expenses. Data cleaning is aided by data augmentation, which is necessary for high precision models. Machine learning is strengthened by data augmentation by adding variances to the model.
.webp)
What techniques are employed in data augmentation?
Before starting the data augmentation procedure or functioning. Let's examine the principles underlying the approaches used in data augmentation. The sophisticated data augmentation models are as follows:
1. Adverse instruction
The term adversarial machine learning is sometimes used. It produces antagonistic examples. These instances challenge machine learning algorithms. They are afterwards injected into datasets.
2. GANs
As generative adversarial networks, GANs grow. From input datasets, these algorithms discover patterns. Then it generates fresh examples that mimic training material.
3. Neural style Transfer
A method for combining content and style images is called neural style transfer. Additionally, it serves the opposite purpose of separating style from content.
4. Reinforcement Learning
The software agents may make judgments in a virtual world with the aid of reinforcement learning.
5. Implementing data augmentation
Depending on the purpose, data augmentation may take several forms. Natural language processing and picture recognition both use traditional and contemporary methods.
6. In order to classify images
Visual transformations are made easier by data augmentation. Flipping, color adjustments, cropping, rotation, geometric modification, padding, re-scaling, zooming, gray scaling, darkening and brightness, random erasing, etc. are the transformations that are primarily focused on picture categorization.
The data augmentation method uses many tools, including generating adversarial networks and the unity game engine, to provide fresh synthetic data in image categorization.
7. For signal processing techniques
A number of signal processing techniques also involve data augmentation. Electromyography and electroencephalography are two examples of such signals. Deep convolutional neural networks and generative adversarial networks are two examples of data augmentation methods for signal processing. By using statistical machine learning models, data augmentations enable signal detection.
These algorithms may categorize the human data after being trained on a synthetic domain.
8. Speech recognition
By transferring learning from artificial data that has been produced using a character-level recurrent neural network, data augmentation helps to improve voice recognition.
9. In order to process natural language (NLP)
By enhancing the text data, data augmentation for NLP functions. However, because of how difficult the process is, it isn't very well known. Common procedures include contextualized word embeddings, back translation, word inclusion, word switch, word deletion, and synonym substitution.
What are a few use cases for data augmentation?
The natural language processing (NLP) and image recognition models frequently employ data augmentation approaches. In the field of medical imaging, data augmentation also is employed to modify images as well as provide variation to datasets. There are several reasons why data augmentation in wellness is of importance.
The dataset for medical images is modest. Data sharing is challenging because of limits on patient data privacy. Only a small number of patients' data can be used as training data for the diagnosis of unusual illnesses.
Some instances of research done in this field include the following:
- The division of brain tumors
-Divergent data augmentation is utilized in medical imaging.
- An automated data augmentation technique for tagging medical images
- Segmentation of medical images using task-driven semi-supervised learning
If you find this blog informative, then stay tuned for more information with Labellerr!

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
