

[Updated] 7 Top Tools for RLHF in 2026
Discover the leading RLHF tools of 2025 in our detailed comparison. We break down key features, use cases, and pricing for platforms like Labellerr, Scale AI, and Encord to help you integrate human feedback into your AI models effectively.

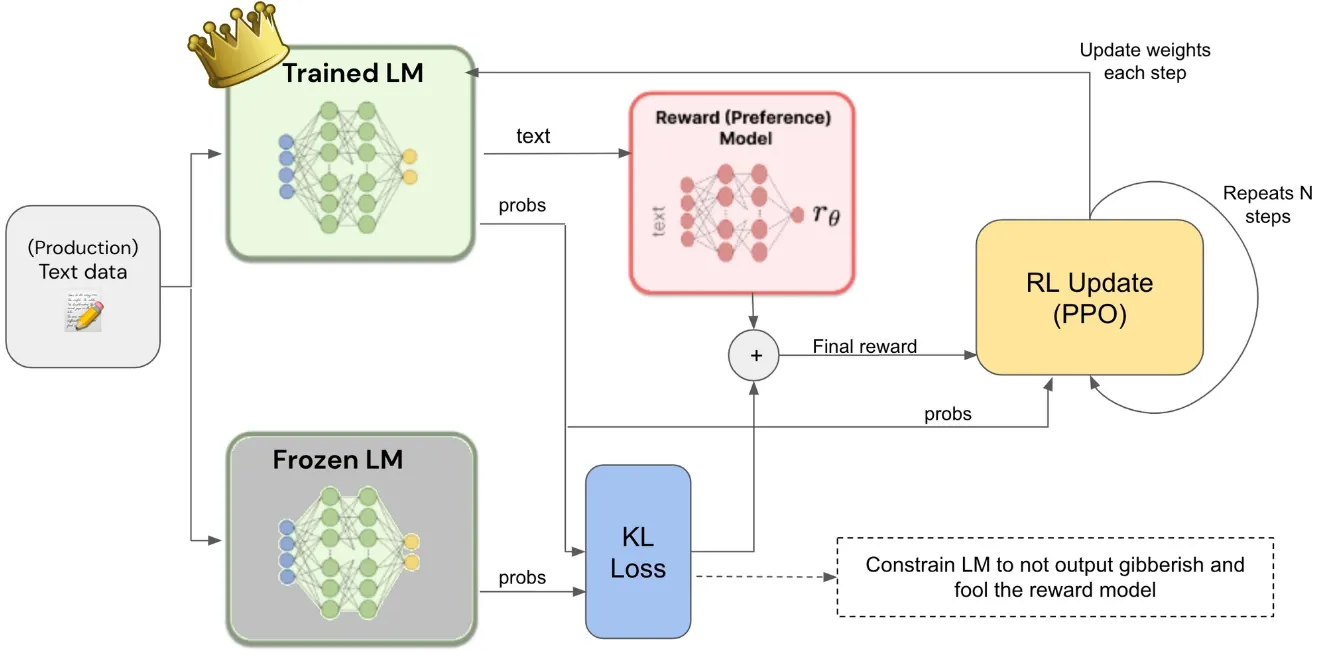
Reinforcement Learning from Human Feedback (RLHF) is a pivotal technique in machine learning for aligning models with human values. The right RLHF tools are essential to implement this process effectively, as they are specifically designed to integrate human input and feedback throughout the learning cycle.
This approach is particularly beneficial for Large Language Models (LLMs) that may be challenging to train using traditional supervised learning methods.
RLHF involves adjusting the reinforcement learning algorithm based on human feedback, allowing the model to learn from the consequences of its actions and adapt its behavior accordingly.
Unlike conventional supervised learning, which relies on pre-labeled data, RLHF enables the model to improve through its own experiences and interactions.
Even though implementing RLHF can be challenging, the right platform makes it manageable. Modern RLHF tools come with built-in features to handle the complexity, helping teams build robust systems efficiently.
These tools come with features to help you build RLHF systems.
Tools associated with RLHF are likely to be software or frameworks designed to facilitate the integration of human feedback into the training process of reinforcement learning algorithms.
These tools may include interfaces for collecting human input, mechanisms to adjust reward functions based on feedback, and components to manage the iterative learning loop between the model and human input.

Here are some of the best ones, ranked by how well they work, how easy they are to use, how much they can grow, and how much they cost.
Let's dive in!
Table of Contents
1. Labellerr

Labellerr RLHF Tool is an innovative platform that simplifies the process of optimizing Language Models (LLMs) through Reinforcement Learning from Human Feedback (RLHF).
With user-friendly features and collaborative functionalities, the Labellerr RLHF Tool is designed for diverse users, making it accessible for teams aiming to enhance their language models.
Key Benefits and Features
1. Effortless Chatbot Development
Labellerr RLHF Tool streamlines the creation of powerful chatbots.
It ensures that they generate responses that are both helpful and reliable.
2. Content Moderation
The platform excels in moderating content by constructing LLMs aligned with valuable human feedback.
This helps in identifying and flagging misinformation, hate speech, and spam effectively.
3. Performance Validation
Labellerr RLHF Tool allows users to quickly benchmark, rank, select, recognize named entities, and classify outputs
It ensures the performance validation of both LLMs and Vision-Language Models (VLMs).
4. Data Prioritization and Curation
The tool facilitates the prioritization, labeling, and curation of high-quality data through specialized workforces proficient in RLHF and evaluation.
5. Security Protocols and Integration
Labellerr RLHF Tool comes equipped with high-end security protocols to ensure the confidentiality and integrity of data.
Additionally, it offers easy integration capabilities which allows seamless incorporation into existing workflows.
Cons:
Limited Format Support: Does not currently support point cloud and 3D data formats.
Pricing:
Pro Plan: Starts at $499 per month for 10-user access with 50,000 data credits included. Additional data credits can be purchased at $0.01 USD per data credit, and extra users can be subscribed to at $29 USD per user.
Enterprise Plan: Offers professional services, including tool customization and ML consultancy.
Best Suited for:
Labellerr RLHF Tool is ideal for teams seeking to build scalable RLHF workflows for large language models or vision language models.
Whether you are a team looking to refine chatbots or enhance content moderation, this tool has a broad spectrum of applications.
This tool stands as a user-friendly and effective solution for teams aiming to harness the power of RLHF in their language model optimization journey.
2. SuperAnnotate RLHF
SuperAnnotate's RLHF (Reinforcement Learning from Human Feedback) tool is designed to enhance the learning process of large language models (LLMs) by combining human expertise with reinforcement learning algorithms.
The goal is to improve the model's performance on specific tasks, making it more accurate and effective.
Here's a breakdown of the key features and benefits of SuperAnnotate's RLHF tool:
Fine-tuning Techniques
SuperAnnotate offers advanced annotation and data curation solutions to fine-tune existing models.
This involves providing specialized training data to improve the model's accuracy and effectiveness for a particular task.
Reinforcement Learning from Human Feedback
RLHF is a unique approach that involves collaboration between human trainers and reinforcement learning algorithms.
Instead of relying solely on trial and error, the algorithms receive feedback and guidance from human trainers.
This accelerates and enhances the training process, leading to better model performance.
Feedback Mechanisms
SuperAnnotate provides multiple feedback mechanisms, including:
Multiple Choice: Select the most appropriate feedback from a list of predefined options.
Rating Scale: Rate the accuracy and quality of a response using a numerical scale.
Binary Rating: Provide feedback using thumbs up or thumbs down buttons to indicate approval or disapproval.
Instruction Fine-tuning: Tailor the training process based on specific instructions.
Instant Feedback Loop
The tool facilitates an instant feedback loop, ensuring quick adjustments based on human feedback. This iterative process accelerates the learning curve of the model.
Use Cases
RLHF can be applied to various tasks, including question answering and image captioning.
It allows users to customize their experience based on specific use cases.
LLM Comparison and Evaluation
SuperAnnotate enables users to evaluate the performance of their models on benchmark tasks using predefined metrics.
This includes comparing the model's output against human-generated data for a comprehensive assessment.
Customization and Interface
Users can customize the interface to include only the necessary components, creating a more intuitive and user-friendly experience.
This tailored approach reduces unnecessary steps and distractions, enhancing productivity.
Advanced Analytics
SuperAnnotate provides powerful data insights, allowing users to monitor annotation trends, analyze model performance, track annotation time, and more.
This in-depth analysis helps users stay on top of project performance.
API Integration
Users can seamlessly connect their models to SuperAnnotate through their API, gaining access to the annotation tool and advanced features without disruptions.
Data Governance and Security
SuperAnnotate prioritizes data governance and security, ensuring compliance with global regulations.
The platform offers advanced solutions to keep data safe, whether stored on-premises or in the cloud.
SuperAnnotate's RLHF tool is a comprehensive solution for enhancing LLMs through collaboration between human expertise and reinforcement learning, with a focus on customization, feedback mechanisms, and advanced analytics.
3. Label Studio
Label Studio is used in the context of Reinforcement Learning from Human Feedback (RLHF) as a tool to create a custom dataset for training a reward model.
Label Studio is used to collect human feedback on language model responses generated from prompts.
Here's a summary of how Label Studio is utilized in the RLHF process:
Create a Custom Dataset:
Prompts for the language model (LM) are provided, and responses are generated using GPT series.
The prompts and generated responses are then passed to human labelers to rank them based on preference.
This human feedback becomes the dataset for training the reward model.
Labeling with Label Studio:
Label Studio is employed to rank the generated responses using a custom interface.
The Pairwise Classification template in Label Studio is chosen for this task.
The provided XML configuration enhances the appearance of the labeling interface, making it more user-friendly.
Export Data and Train Reward Model
After collecting human labels in Label Studio, the data is exported for further processing.
The exported data is used to train the reward model, which is a crucial step in the RLHF process.
The reward model is then employed to fine-tune the initial language model through reinforcement learning.
Integration with RLHF Process:
RLHF involves collecting human feedback, training a reward model, and fine-tuning the language model using this reward model.
The reward model, trained with human preferences obtained through Label Studio, helps optimize the language model's output to align with complex human values.
The emphasis here is on how Label Studio serves as a tool for gathering human feedback efficiently, contributing to the creation of a high-quality dataset for reinforcement learning.
This process is essential for enhancing language models by incorporating human preferences and values.
4. Encord RLHF
Encord RLHF is a platform designed for the creation of Reinforcement Learning from Human Feedback (RLHF) workflows.
It facilitates the optimization of both Language Models (LLMs) and Vision-Language Models (VLMs) through human input by incorporating collaborative features.
Key Features and Advantages
1. Advanced Chatbot Development
Encord RLHF provides the tools needed to construct powerful chatbots capable of generating reliable and useful responses.
2. Content Moderation
The platform allows users to moderate content effectively by building LLMs aligned with human feedback.
It helps to identify and flag misinformation, hate speech, and spam.
3. Performance Evaluation
Users can efficiently benchmark, rank, select, recognize named entities, and classify outputs to validate the performance of LLMs and VLMs.
4. Data Quality Enhancement
Encord RLHF facilitates the prioritization, labeling, and curation of high-quality data through specialized workforces with expertise in RLHF and evaluation.
5. Security Protocols
With high-end security protocols, the platform ensures the confidentiality and integrity of data.
It provides a secure environment for model training.
6. Integration Capabilities
Encord RLHF can be easily integrated into existing workflows and offers seamless compatibility with other tools and systems.
Best Suited for:
Encord RLHF is ideal for teams to establish scalable RLHF workflows tailored for large language or vision-language models.
The platform helps teams seeking comprehensive solutions for refining and optimizing language and vision models through human feedback.
It is useful for teams the require to build advanced chatbots or enhance content moderation.
5. Appen RLHF
Appen RLHF platform is useful for developing Language Model (LLM) products.
It offers exceptional capabilities in domain-specific data annotation and collection.
With a specialized module for Reinforcement Learning from Human Feedback (RLHF), Appen RLHF leverages a carefully curated crowd of diverse human annotators, each possessing a broad spectrum of expertise and educational backgrounds.
Key Features and Advantages
1. Expert Feedback
Appen RLHF provides access to specialists who offer valuable feedback.
It enhances the overall quality and effectiveness of the LLM products.
2. Quality Controls
The platform incorporates robust quality controls designed to identify and mitigate issues such as gibberish content and duplication.
It ensures the reliability of annotated data.
3. Multi-Modal Annotation
Appen RLHF supports multi-modal data annotation and accommodates various data types.
It enriches the training datasets with diverse information.
4. Real-World Simulation
Appen RLHF goes beyond traditional annotation by providing real-world simulation environments tailored to specific needs.
This feature enhances the applicability and realism of the trained models.
Best Suited for:
Appen RLHF is an ideal choice for teams seeking to create powerful LLM applications across a range of use cases.
Whether the goal is to refine language models for specific industries or enhance applications through RLHF, this platform helps the teams aiming to leverage high-quality and domain-specific data annotation with the support of a diverse and expert crowd.
6. Scale
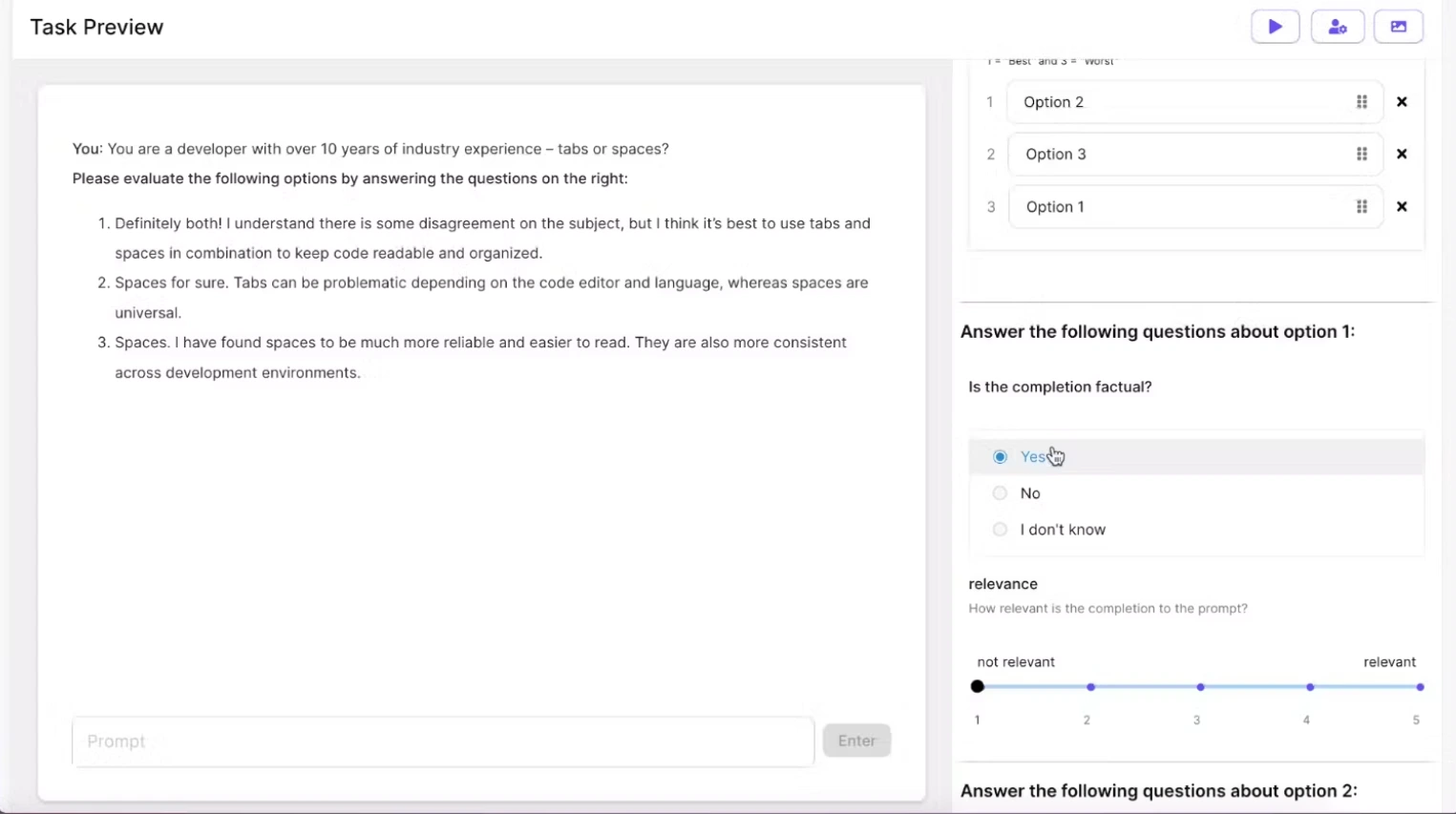
Scale is an advanced AI platform specializing in the optimization of Language Models (LLMs) through Reinforcement Learning from Human Feedback (RLHF).
Key Features and Advantages
1. Diverse Applications
Scale facilitates the development of chatbots, code generators, and content creation solutions, providing a versatile platform for a wide range of AI-driven applications.
2. Intuitive User Interface
The platform boasts an intuitive user interface designed to streamline the process of providing feedback.
It ensures a user-friendly experience for all contributors.
3. Collaborative Features
Scale incorporates collaborative features that enhance communication between labelers and task requirements during the feedback process.
This fosters a better understanding of the objectives and improves the overall quality of input.
Best Suited for:
Scale is particularly well-suited for teams in search of a robust labeling platform that actively supports human input.
Whether the goal is to refine chatbots, generate code, or create content, Scale provides an effective solution for teams seeking to optimize Language Models through RLHF with a focus on user-friendly interfaces and collaborative features.
7. Surge AI
Surge AI stands as an innovative Reinforcement Learning from Human Feedback (RLHF) platform, which drives Anthropic AI's Language Model (LLM) tool named Claude.
Surge AI provides a range of modeling capabilities, including summarization, copywriting, and behavior cloning, empowering users to build advanced language models tailored to their specific needs.
Key Features and Advantages
1.InstructGPT-Style Models
Surge AI enables the construction of models reminiscent of InstructGPT, allowing users to create sophisticated language models with versatile applications.
2. Safety Protocols
The platform prioritizes safety by incorporating robust protocols, including SOC 2 compliance, ensuring a secure and trustworthy environment for model development and deployment.
3. Integration Capabilities
Surge AI offers seamless integration through the Application Programming Interface (API) and Software Development Kit (SDK), providing flexibility and ease for incorporating its capabilities into existing workflows.
Best Suited for:
Surge AI is an ideal choice for teams aiming to develop multi-purpose chatbots and generative tools. Whether the objective is to create models for instructive tasks, enhance content generation, or clone specific behaviors, Surge AI provides a comprehensive RLHF platform with a focus on safety, integration, and diverse modeling capabilities.
Conclusion
Reinforcement Learning from Human Feedback (RLHF) is a powerful technique for training Language Models (LLMs) with the help of human input, especially beneficial for large models that might be challenging to train using traditional methods.
This overview highlighted several leading platforms, each offering unique features to simplify the RLHF process. The best choice depends on your project's specific needs, whether it's seamless collaboration, support for diverse data types, or enterprise-level security.
Labellerr stood out for its user-friendly interface and collaborative functionalities, making it suitable for diverse teams aiming to optimize their language models.
Encord RLHF, Appen RLHF, Scale, and Surge AI also showcased their capabilities in developing advanced chatbots, refining content moderation, and optimizing LLMs through a combination of human feedback and reinforcement learning.
These tools cater to different needs, from quality data annotation to real-world simulation, providing teams with versatile solutions to improve language models effectively.
Choosing the right RLHF tool depends on specific project requirements, and each platform offers distinct advantages for teams seeking to harness the power of RLHF in their language model optimization journey.
Read our other listicles:
Frequently Asked Questions
1. What is RLHF & how does it work?
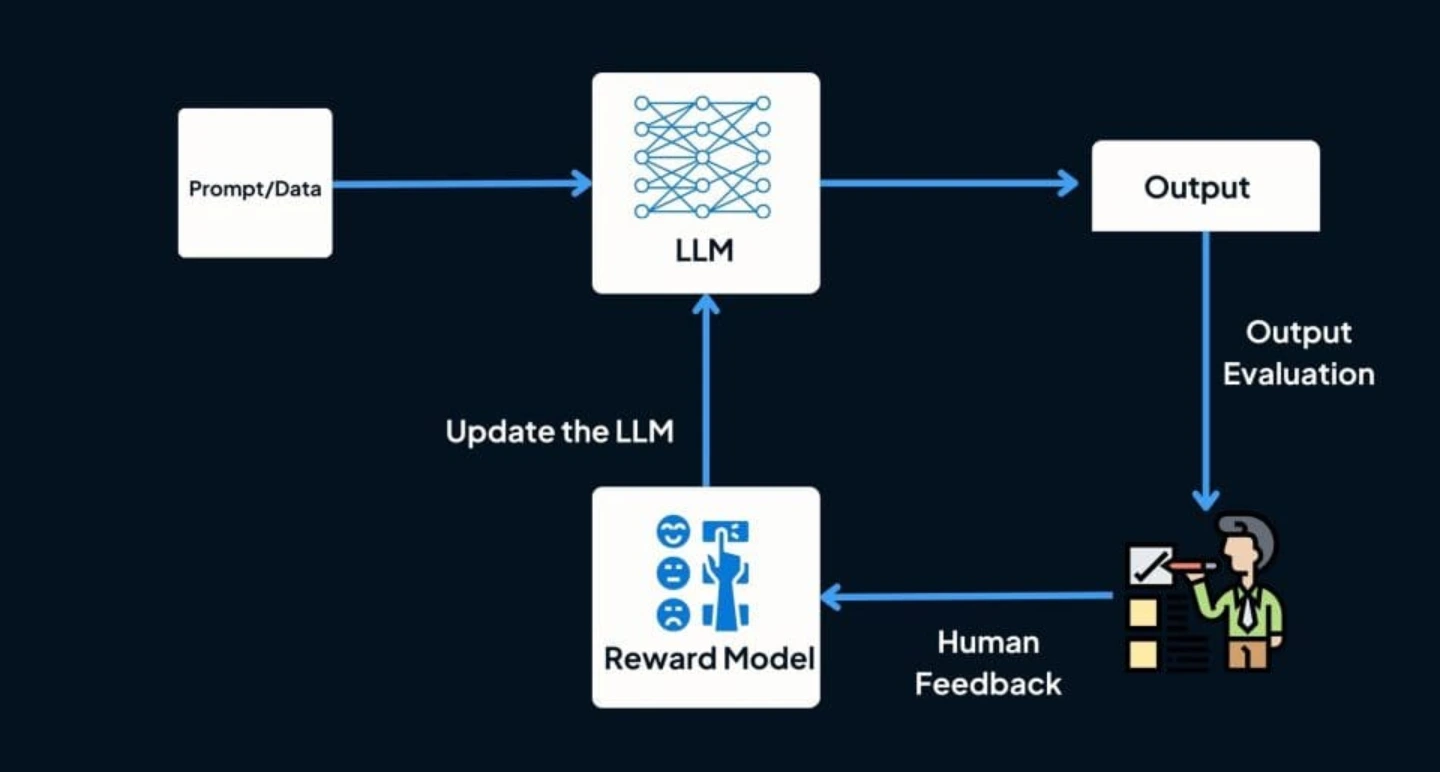
RLHF, or Reinforcement Learning from Human Feedback, is a machine-learning approach where an artificial intelligence system learns by receiving feedback from humans.
In RLHF, the model is initially trained using traditional methods, and then it refines its performance through interactions with humans who provide feedback on its outputs.
The feedback helps the model understand the desired behavior and improve over time.
This iterative process allows the AI system to learn from human input, making it particularly useful in scenarios where explicit examples of correct behavior are challenging to define or where human expertise is crucial for fine-tuning the model's performance.
2. Which model is best for RLHF training?
The choice of the best model for RLHF training depends on the specific task and domain.
Transformer-based language models, such as GPT-3, BERT, or similar architectures, are commonly used for RLHF due to their ability to capture complex patterns in data.
These models excel in understanding context and generating human-like responses.
However, the optimal model selection should consider factors like the task requirements, available data, and the desired level of model sophistication.
Experimentation and fine-tuning with different models are often necessary to determine which one performs best for a particular RLHF application.
3. What is RLHF & how does it affect AI?
RLHF, or Reinforcement Learning from Human Feedback, is a machine learning approach that involves training artificial intelligence (AI) models by receiving feedback from humans.
This iterative learning process helps refine the AI's behavior over time based on human input, allowing the model to improve its performance.
RLHF has a significant impact on AI as it enables the models to adapt and learn from real-world interactions and human expertise.
It enhances the AI's ability to handle complex tasks, make informed decisions, and generate outputs that align better with human expectations, making it a valuable methodology for improving the overall capabilities and reliability of AI systems.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
