

Best Open-Source Vision Language Models of 2026
Discover the leading open-source vision-language models (VLMs) of 2025 including Qwen 2.5 VL, LLaMA 3.2 Vision, and DeepSeek-VL. This guide compares key specs, encoders, and capabilities like OCR, reasoning, and multilingual support.

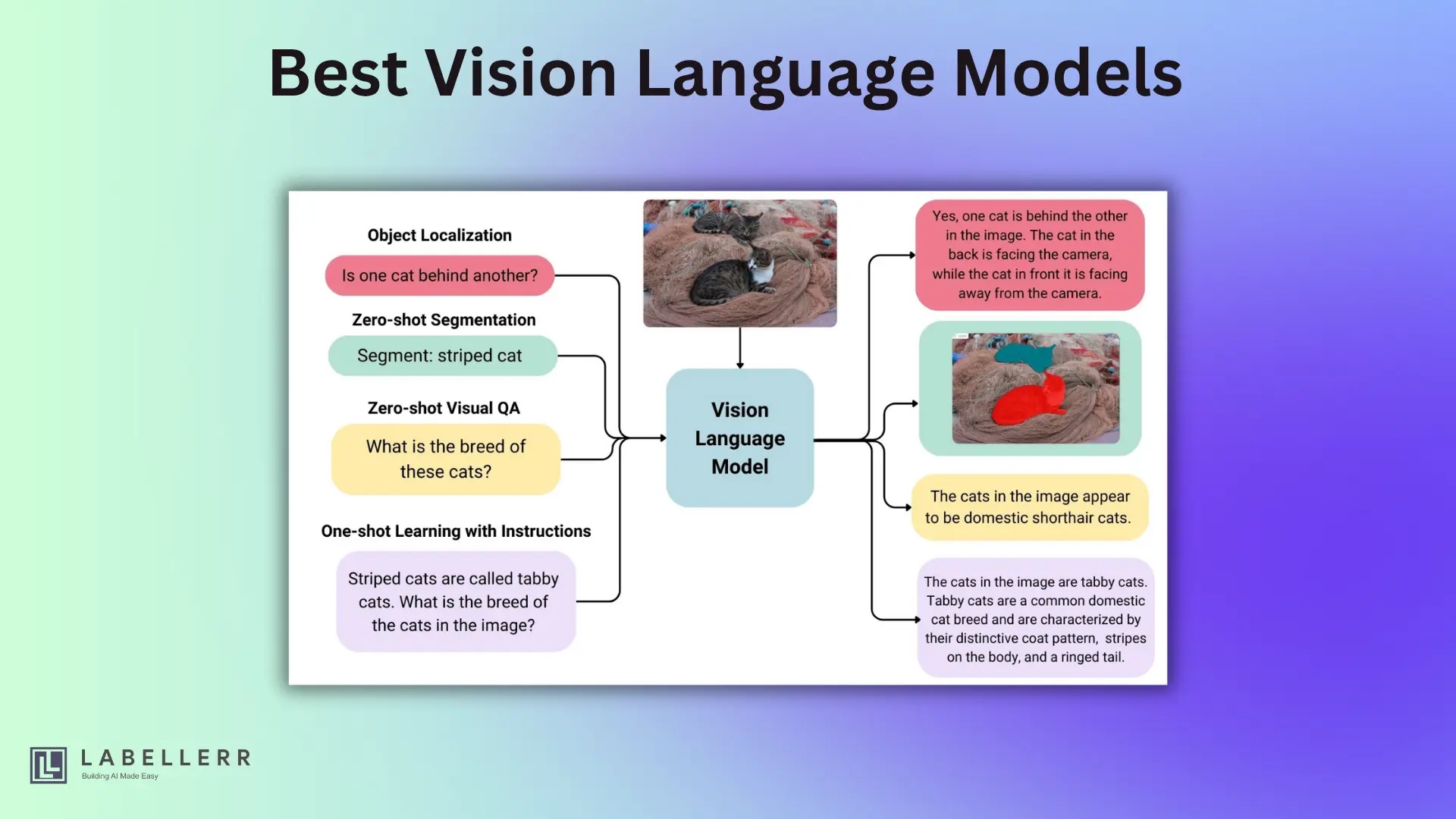
If you’ve ever wished an AI could read a chart, analyze an image, and answer your questions instantly, you’re looking for a Vision Language Model (VLM). In this guide, we break down 2025’s best open-source VLMs, when to use each, and how to choose the one that fits your needs."
Vision Language Models (VLMs) are AI systems that process both images and text simultaneously. They bridge computer vision (AI that understand visual data) with natural language processing (AI that understands language).
VLMs perform tasks like answering questions about pictures, writing image descriptions, and understanding documents with text and visuals.
Open-source VLMs are changing the AI landscape. Their code and pre-trained model weights are shared freely, giving developers access to advanced multimodal AI without proprietary restrictions.
This democratizes innovation and allows customization for specific needs.
Key Technical Features of Modern VLMs
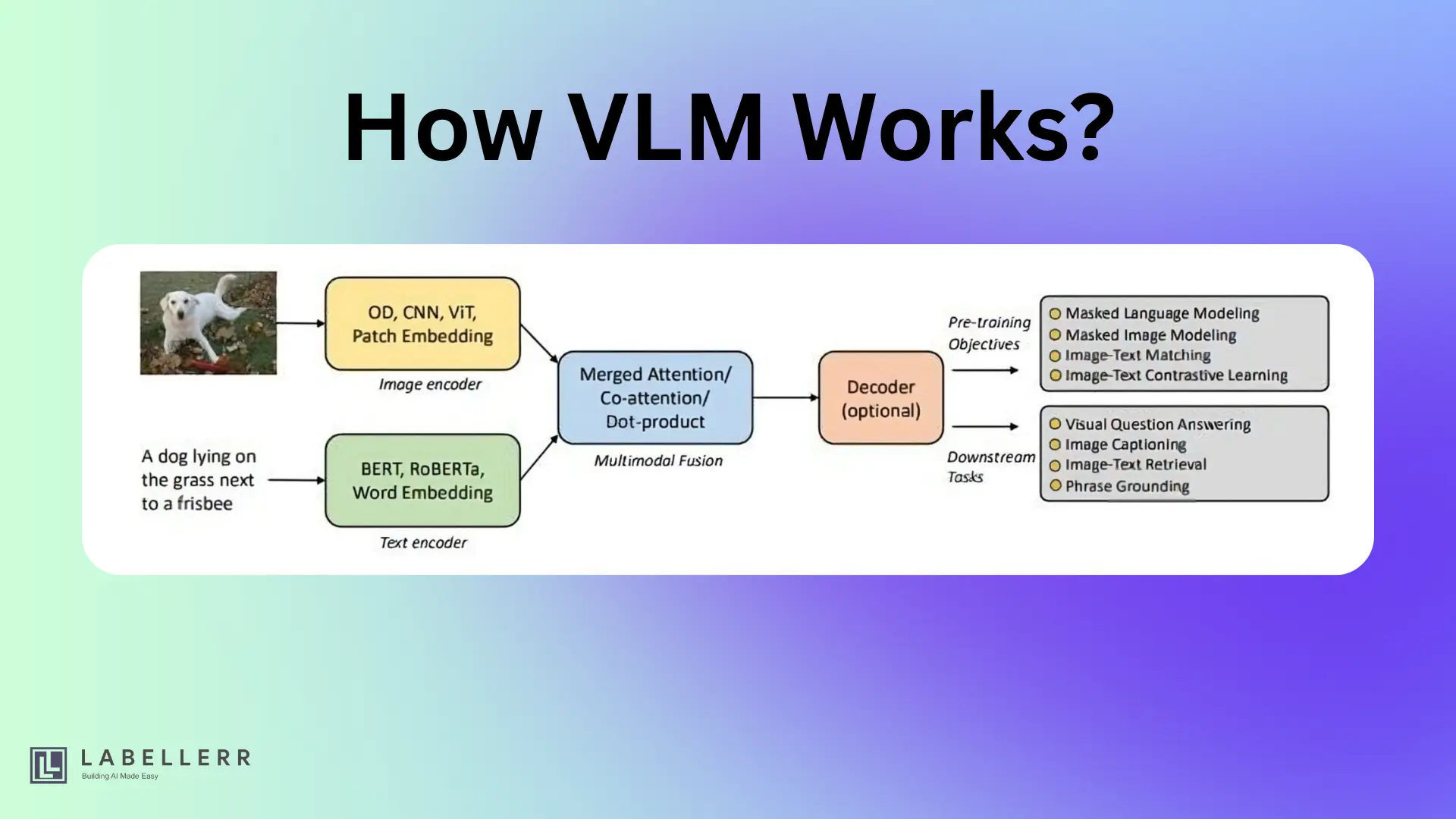
How VLM Works?
When evaluating VLMs, these technical features matter:
- Multimodal Input Processing: VLMs accept and jointly process images, text, and sometimes video or audio
- Vision Encoders (ViT, SigLIP, CLIP): Transform raw image pixels into meaningful representations the language model can understand
- Language Model Backbone (Llama, Qwen, Phi): Powerful pre-trained LLMs provide language understanding and generation
- Vision-Language Fusion: Cross-attention layers or adapter modules integrate visual and textual information
- Context Window Size (128k tokens): Larger windows handle complex prompts and long documents with visuals
- Dynamic Resolution Handling: Advanced techniques process images of various sizes effectively (e.g., Gemma 3's "Pan & Scan")
- Instruction Tuning & RLHF: Fine-tuning stages make VLMs helpful, safe, and instruction-following
- Multilingual Capabilities: Support for multiple languages, including OCR in different languages
- Output Capabilities: Text generation plus structured data like bounding boxes or JSON
- Licensing: Determines usage rights (research, commercial) - always check carefully
"In 2025, open-source VLMs have reduced inference costs by up to 60% compared to closed commercial models, while achieving competitive benchmark scores such as MMBench >80% and MM-Vet >75% for top models like Qwen 2.5 VL and Pixtral."
Top Open-Source VLMs: Technical Comparison
| Model Name | Sizes | Vision Encoder | Key Features | License |
|---|---|---|---|---|
| Gemma 3 | 4B, 12B, 27B | SigLIP | Pan & Scan, high-res vision, 128k context, multilingual | Open Weights |
| Qwen 2.5 VL | 7B, 72B | Custom ViT | Dynamic resolution, 29 languages, video, object localization | Apache 2.0 |
| Llama 3.2 Vision | 11B, 90B | Vision Adapter | 128k context, strong document/OCR, VQA, captioning | Community License |
| Falcon 2 11B VLM | 11B | CLIP ViT-L/14 | Dynamic encoding, fine details, multilingual | Apache 2.0 |
| DeepSeek-VL | 1.3B, 4.5B | SigLIP-L | Strong reasoning, scientific tasks, Mixture of Experts | Open Source |
| Pixtral | 12B | Not specified | Multi-image input, native resolution, strong instruction following | Apache 2.0 |
| Phi-4 Multimodal | Various | Not specified | Strong reasoning, lightweight variants, on-device potential | Open Source |
Technical Details & Use Cases
Gemma 3 (Google DeepMind)
- Technical Details: Built on Gemma LLM (4B-27B parameters). Uses SigLIP vision encoder (896x896 images). "Pan & Scan" algorithm handles varied image resolutions and improves text reading. Images become 256 compact "soft tokens" for efficiency. Supports up to 128k context tokens. Improved tokenizer (262k vocabulary) enhances multilingual support
- Strengths: High-resolution image understanding, long context handling, multilingual text processing
- Use Cases: Document analysis, multimodal chatbots, non-English visual text understanding
- License: Open weights, commercial use allowed
Example:
A global law firm uses Gemma 3 to scan and extract clauses from thousands of multilingual contracts, reducing legal review time from days to hours. Its high-resolution “Pan & Scan” capability makes it ideal for compliance teams handling scanned documents and forms with small text.
Qwen 2.5 VL (Alibaba)
- Technical Details: Flagship VLM (3B-72B parameters); 72B model rivals GPT-4o in document understanding. "Native Dynamic Resolution" ViT handles diverse image sizes and long videos (up to an hour) without normalization. Absolute Time Encoding enables precise video event localization. Supports 128k context and 29 languages. Excels at object localization and structured data extraction
- Strengths: Superior document/diagram understanding, excellent object localization, long video comprehension, multilingual OCR, agentic capabilities
- Use Cases: Automated data entry, interactive UI agents, long video analysis, multilingual OCR
- License: Apache 2.0
Example:
An edtech platform uses Qwen 2.5 VL to automatically index and search entire lecture videos, pinpointing exact timestamps where concepts are explained. Logistics companies deploy it to process complex PDF shipping manifests and extract container details, even from low-quality scans.
Llama 3.2 Vision (Meta)
- Technical Details: 11B and 90B sizes, built on Llama 3.1 with vision adapter. 128k context support. Strong in image recognition, captioning, VQA, and document understanding
- Strengths: Robust document task performance, good general VQA/captioning, highly customizable
- Use Cases: Document processing workflows, accessibility image descriptions, interactive VQA systems
- License: Community License (research and commercial with terms)
Example:
A government agency applies LLaMA 3.2 Vision to process scanned census forms and generate structured demographic databases. Accessibility platforms use it to generate highly accurate image captions for visually impaired readers in multiple languages.
Falcon 2 11B VLM (TII)
- Technical Details: 11B parameters based on Falcon 2 chat model. CLIP ViT-L/14 vision encoder. Dynamic encoding at high resolution for fine detail perception. Multilingual capabilities
- Strengths: Efficient (single GPU), strong vision-language integration, fine detail perception
- Use Cases: Detailed object recognition, document management, accessibility tools
- License: Apache 2.0
Example:
An aerospace manufacturer uses Falcon 2 11B VLM to inspect high-detail component images for defects while generating engineer-friendly annotations. Museums integrate it into mobile guides, where visitors photograph artifacts and receive multilanguage historical details instantly.
DeepSeek-VL (DeepSeek AI)
- Technical Details: Multiple sizes (1.3B, 4.5B); uses Mixture of Experts (MoE) architecture for efficiency. Comprises SigLIP-L vision encoder, vision-language adapter, and DeepSeekMoE LLM. Trained on diverse data including scientific content
- Strengths: Strong reasoning capabilities, designed for scientific and real-world vision tasks
- Use Cases: Scientific diagram analysis, visual reasoning for robotics, logical scene understanding
- License: Open source
Example:
A robotics research lab feeds DeepSeek-VL scientific diagrams and experiment results to help autonomous robots understand lab equipment layouts. It is also used by pharmaceutical companies to interpret and summarize complex chemical pathway charts.
Pixtral (Mistral AI)
- Technical Details: 12B parameter high-performing VLM. Supports multi-image inputs and native resolution processing. Strong instruction-following and benchmark performance (MMBench, MM-Vet)
- Strengths: Multi-image handling, high visual fidelity, robust instruction following
- Use Cases: Multi-image reasoning, high-detail visual tasks, complex instruction-following agents
- License: Apache 2.0
Example:
A digital marketing team uses Pixtral to compare multiple product photos side-by-side and generate persuasive ad descriptions targeting specific audiences. Wildlife researchers employ it to process time-lapse camera trap images from different locations and extract animal counts.
Phi-4 Multimodal (Microsoft)
- Technical Details: Part of Microsoft's Phi family known for strong reasoning in compact sizes. Lightweight variants suitable for on-device deployment via ONNX Runtime
- Strengths: Good reasoning in smaller models, efficient on-device inference, potentially less censored
- Use Cases: Mobile/edge AI features, real-time multimodal apps, content description tasks
- License: Open source
Example:
A mobile health startup integrates Phi-4 Multimodal into its app, enabling patients to take photos of medical prescriptions and receive dosage reminders offline. Field technicians use it on rugged tablets to identify faulty machinery parts without needing a cloud connection.
Which Model Should You Use?
| If you need… | Best Choice | Why |
|---|---|---|
| Fast multilingual OCR in images | Gemma 3 | Handles high-res text in 29+ languages |
| Long-form video understanding | Qwen 2.5 VL | Processes an hour of video with precise time encoding |
| Document understanding with OCR | LLaMA 3.2 Vision | Strong in VQA, captions, and scanned doc reading |
| Scientific diagram reasoning | DeepSeek-VL | Trained on technical, scientific visuals |
| Low-resource/memory environments | Phi-4 Multimodal | Lightweight and suitable for on-device |
The Future of Open-Source VLMs
Expect rapid progress in:
- Performance: Better accuracy, reasoning, and efficiency
- Video Understanding: Robust long-form video processing
- Agentic Capabilities: Interacting with digital environments
- Edge AI: Smaller, more efficient architectures
- Fine-Tuning Tools: Easier customization for specialized applications
Conclusion
Open-source VLMs are revolutionizing multimodal AI. Models like Gemma 3, Qwen 2.5 VL, Llama 3.2 Vision, and others offer diverse capabilities and licensing options, empowering developers to build innovative applications.
Success requires understanding technical details, choosing the right model, and leveraging quality data and fine-tuning.
The future of VLMs, driven by vibrant open-source communities, promises even more powerful AI that can truly see, understand, and interact with our world.
References
- Vision Language Model Explained
- What are Vision Language Models
- Hugging Face Vision Language Models
- Collection of Awesome-VLM
FAQs
Q1: What is a Vision Language Model (VLM)?
A: A VLM is a model that processes both visual and textual data. These models understand, generate, and reason about multimodal content — including images, charts, and natural language.
Q2: What are the most powerful open-source VLMs in 2025?
A: Some of the top open-source VLMs include:
- Gemma 3 (4B–27B) — Pan & scan, multilingual, 128k context.
- Qwen 2.5 VL (7B–72B) — Video input, object localization, 29 languages.
- LLaMA 3.2 Vision (11B–90B) — Strong OCR, document VQA, 128k context.
- DeepSeek-VL — Strong scientific reasoning, MoE architecture.
Q3: Which open-source VLM supports video input?
A: Qwen 2.5 VL is one of the few open-source VLMs with support for video, along with dynamic resolution and strong multilingual capabilities.
Q4: What is the smallest high-performance VLM in 2025?
A: DeepSeek-VL (1.3B) is currently one of the smallest VLMs with strong reasoning performance, especially in scientific tasks.
Q5: Are these models truly open-source?
A: Yes, most are under open licenses like Apache 2.0 or Community License, with open weights. Some (like Phi-4) are designed for lightweight deployment and edge usage.
Q6: Which VLM is best for non-English document analysis?
A: Gemma 3 and Qwen 2.5 VL excel here. Gemma 3 has multilingual OCR; Qwen supports 29 languages and dynamic resolution for mixed image-text docs.
Q7: Can I run these models on my laptop?
A: Yes — use smaller models like Phi-4 or DeepSeek-VL 1.3B for faster inference without GPU clusters.
Q8: How do these models compare to GPT-4o?
A: Models like Qwen 2.5 VL (72B) and LLaMA 3.2 Vision come close for document understanding but may require fine-tuning for niche tasks.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
