

The Ultimate Guide to Text Annotation: Techniques, Tools, and Best Practices
Text annotation is essential for training AI to understand human language by labeling entities, sentiments, and more. This guide covers techniques like sentiment analysis, named entity recognition, and tools that streamline text data annotation, boosting AI accuracy.


Table of Contents
- Introduction
- What is Text Annotation?
- Types of Text Annotation
- Text Annotation Use Cases
- Text Annotation Guidelines
- Text Annotation Tools and Technologies
- Challenges in Text Annotation
- The Future of Text Annotation
- Conclusion
- Frequently Asked Questions
Introduction
Welcome to the realm where language meets machine intelligence: text annotation - the catalyst propelling artificial intelligence to understand, interpret, and communicate in human language. Evolving from editorial footnotes to a cornerstone in data science, text annotation now drives Natural Language Processing (NLP) and Computer Vision, reshaping industries across the globe.
Imagine AI models decoding sentiments, recognizing entities, and grasping human nuances in a text. Text annotation is the magical key to making this possible. Join us on this journey through text annotation - exploring its techniques, challenges, and the transformative potential it holds for healthcare, finance, government, logistics, and beyond.
In this exploration, witness text annotation's evolution and its pivotal role in fueling AI's understanding of language. Explore how tools such as Labellerr help in text annotation and work. Let's unravel the artistry behind text annotation, shaping a future where AI comprehends, adapts, and innovates alongside human communication.
1. What is Text Annotation?
Text annotation is a crucial process that involves adding labels, comments, or metadata to textual data to facilitate machine learning algorithms' understanding and analysis.
This practice, known for its traditional role in editorial reviews by adding comments or footnotes to text drafts, has evolved significantly within the realm of data science, particularly in Natural Language Processing (NLP) and Computer Vision applications.
In the context of machine learning, text annotation takes on a more specific role. It involves systematically labeling pieces of text to create a reference dataset, enabling supervised machine learning algorithms to recognize patterns, learn from labeled data, and make accurate predictions or classifications when faced with new, unseen text.
To elaborate on what it means to annotate text: In data science and NLP, annotating text demands a comprehensive understanding of the problem domain and the dataset. It involves identifying and marking relevant features within the text. This can be akin to labeling images in image classification tasks, but in text, it includes categorizing sentences or segments into predefined classes or topics.
For instance, labeling sentiments in online reviews, distinguishing fake and real news articles, or marking parts of speech and named entities in text.

1.1 Text Annotation Tasks: A Multifaceted Approach to Data Labeling
(i) Text Classification: Assigning predefined categories or labels to text segments based on their content, such as sentiment analysis or topic classification.
(ii) Named Entity Recognition (NER): Identifying and labeling specific entities within the text, like names of people, organizations, locations, dates, etc.
(iii) Parts of Speech Tagging: Labeling words in a sentence with their respective grammatical categories, like nouns, verbs, adjectives, etc.
(iv) Summarization: Condensing a lengthy text into a shorter, coherent version while retaining its key information.
1.2 Significant Benefits of Text Annotation
(i) Improved Machine Learning Models: Annotated data provides labeled examples for algorithms to learn from, enhancing their ability to make accurate predictions or classifications when faced with new, unlabeled text.
(ii) Enhanced Performance and Efficiency: Annotations expedite the learning process by offering clear indicators to algorithms, leading to improved performance and faster model convergence.
(iii) Nuance Recognition: Text annotations help algorithms understand contextual nuances, sarcasm, or subtle linguistic cues that might not be immediately apparent, enhancing their ability to interpret text accurately.
(iv) Applications in Various Industries: Text annotation is vital across industries, aiding in tasks like content moderation, sentiment analysis for customer feedback, information extraction for search engines, and much more.
Text annotation is a critical process in modern machine learning, empowering algorithms to comprehend, interpret, and extract valuable insights from textual data, thereby enabling various applications across different sectors.
2. Types of Text Annotation
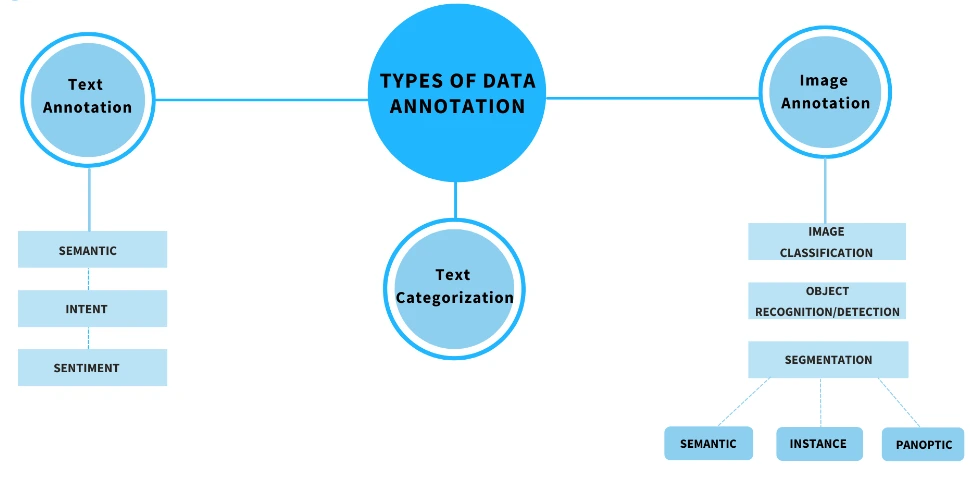
Text annotation, in the realm of data labeling and Natural Language Processing (NLP), encompasses a diverse range of techniques used to label, categorize, and extract meaningful information from textual data. This multifaceted process involves several types of annotations, each serving a distinct purpose in enhancing machine understanding and analysis of text.
These annotation types include sentiment annotation, intent annotation, entity annotation, text classification, linguistic annotation, named entity recognition (NER), part-of-speech tagging, keyphrase tagging, entity linking, document classification, language identification, and toxicity classification.
1. Sentiment Annotation
Sentiment annotation is a technique crucial for understanding emotions conveyed in text. Assigning sentiments like positive, negative, or neutral to sentences aids in sentiment analysis.
This process involves deciphering emotions in customer reviews on e-commerce platforms (e.g., Amazon, Flipkart), enabling businesses to gauge customer satisfaction.
Precise sentiment annotation is vital for training machine learning models that categorize texts into various emotions, facilitating a deeper understanding of user sentiments towards products or services.
Let's consider various instances where sentiment annotation encounters complexities:
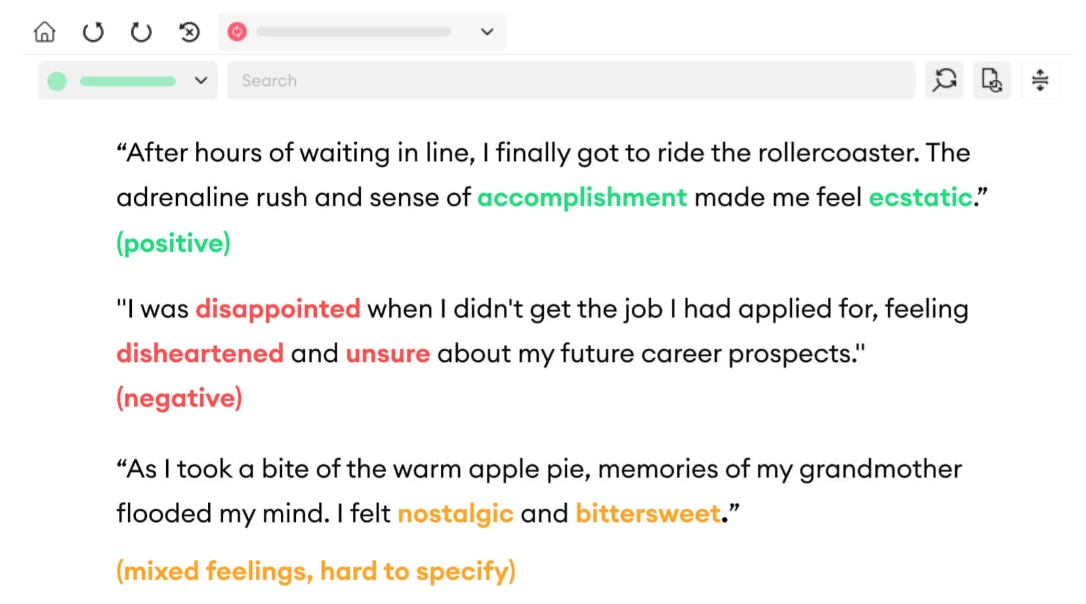
(i) Clear Emotions: In the initial examples, emotions are distinctly evident. The first instance exudes happiness and positivity, while the second reflects disappointment and negative feelings. However, in the third case, emotions become intricate. Phrases like "nostalgic" or "bittersweet" evoke mixed sentiments, making it challenging to classify into a single emotion.
(ii) Success versus Failure: Analyzing phrases such as "Yay! Argentina beat France in the World Cup Finale" presents a paradox. Initially appearing positive, this sentence also implies negative emotions for the opposing side, complicating straightforward sentiment classification.
(iii) Sarcasm and Ridicule: Capturing sarcasm involves comprehending nuanced human communication styles, relying on context, tone, and social cues—characteristics often intricate for machines to interpret.
(iv) Rhetorical Questions: Phrases like "Why do we have to quibble every time?" may seem neutral initially. However, the speaker's tone and delivery convey a sense of frustration and negativity, posing challenges in categorizing the sentiment accurately.
(v) Quoting or Re-tweeting: Sentiment annotation confronts difficulties when dealing with quoted or retweeted content. The sentiment expressed might not align with the opinions of the one sharing the quote, creating discrepancies in sentiment classification.
In essence, sentiment annotation encounters challenges due to the complexity of human emotions, contextual nuances, and the subtleties of language expression, making accurate classification a demanding task for automated systems.
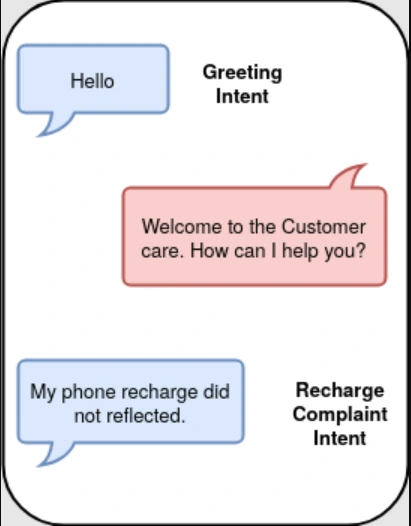
Intent Annotation
Intent annotation is a crucial aspect in the development of chatbots and virtual assistants, forming the backbone of their functionality. It involves labeling or categorizing user messages or sentences to identify the underlying purpose or intention behind the communication.
This annotation process aims to understand and extract the user's intent, enabling these AI systems to provide contextually relevant and accurate responses. Intent annotation involves labeling sentences to discern the user's intention behind a message. By annotating intents like greetings, complaints, or inquiries, systems can generate appropriate responses.
Key points regarding intent text annotation include:
Purpose Identification: Intent annotation involves categorizing user messages into specific intents such as greetings, inquiries, complaints, feedback, orders, or any other actionable user intents. Each category represents a different user goal or purpose within the conversation.
Training Data Creation: Creating labeled datasets is crucial for training machine learning models to recognize and classify intents accurately. Annotated datasets consist of labeled sentences or phrases paired with their corresponding intended purposes, forming the foundation for model training.
Contextual Understanding: Intent annotation often requires a deep understanding of contextual nuances within language. It's not solely about identifying keywords but comprehending the broader meaning and context of user queries or statements.
Natural Language Understanding (NLU): It falls under the realm of natural language processing (NLP) and requires sophisticated algorithms capable of interpreting and categorizing user intents accurately. Machine learning models, such as classifiers or neural networks, are commonly used for this purpose.
Iterative Process: Annotation of intents often involves an iterative process. Initially, a set of intent categories is defined based on common user interactions. As the system encounters new user intents, the annotation process may expand or refine these categories to ensure comprehensive coverage.
Quality Assurance and Validation: It's essential to validate and ensure the quality of labeled data. This may involve multiple annotators labeling the same data independently to assess inter-annotator agreement and enhance annotation consistency.
Adaptation and Evolution: Intent annotation isn't a one-time task. As user behaviors, language use, and interaction patterns evolve, the annotated intents also need periodic review and adaptation to maintain accuracy and relevance.
Enhancing User Experience: Accurate intent annotation is pivotal in enhancing user experience. It enables chatbots and virtual assistants to understand user needs promptly and respond with relevant and helpful information or actions, improving overall user satisfaction.
Industry-Specific Customization: Intent annotation can be industry-specific. For instance, in healthcare, intents may include appointment scheduling, medication queries, or symptom descriptions, while in finance, intents may revolve around account inquiries, transaction history, or support requests.
Continuous Improvement: Feedback loops and analytics derived from user interactions help refine intent annotation. Analyzing user feedback on system responses can drive improvements in intent categorization and response generation.
For instance, Siri or Alexa, trained on annotated data for specific intents, responds accurately to user queries, enhancing user experience. Below are given examples:
- Greeting Intent: Hello there, how are you?
- Complaint Intent: I am very disappointed with the service I received.
- Inquiry Intent: What are your business hours?
- Confirmation Intent: Yes, I'd like to confirm my appointment for tomorrow at 10 AM.
- Request Intent: Could you please provide me with the menu?
- Gratitude Intent: Thank you so much for your help!
- Feedback Intent: I wanted to give feedback about the recent product purchase.
- Apology Intent: I'm sorry for the inconvenience caused.
- Assistance Intent: Can you assist me with setting up my account?
- Goodbye Intent: Goodbye, have a great day!
These annotations serve as training data for AI models to learn and understand different user intentions, enabling chatbots or virtual assistants to respond accurately and effectively.
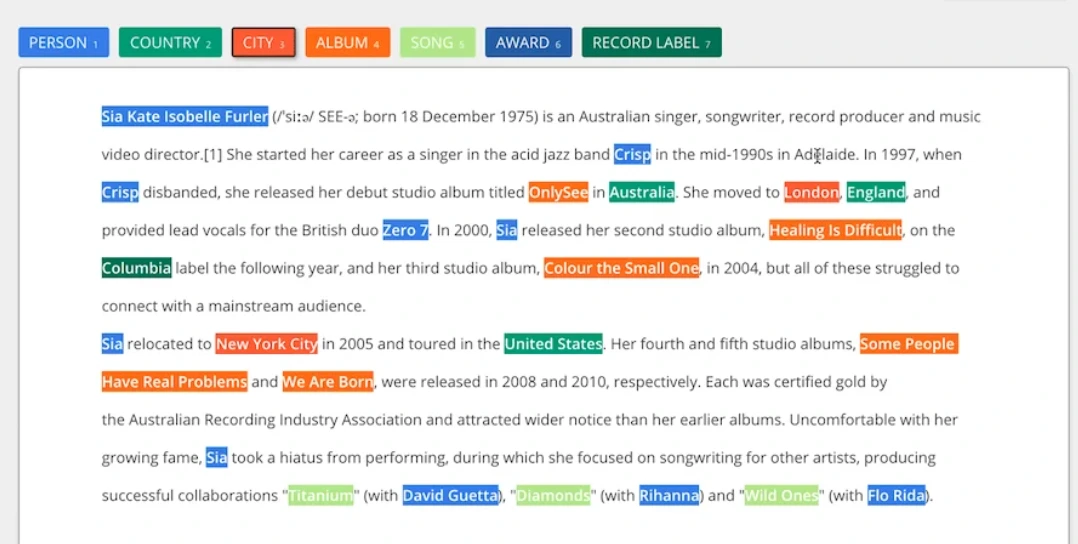
Entity Annotation:
Entity annotation focuses on labeling key phrases, named entities, or parts of speech in text. This technique emphasizes crucial details in lengthy texts and aids in training models for entity extraction. Named entity recognition (NER) is a subset of entity annotation, labeling entities like people's names, locations, dates, etc., enabling machines to comprehend text more comprehensively by distinguishing semantic meanings.
Text Classification
Text classification assigns categories or labels to text segments. This annotation technique is essential for organizing text data into specific classes or topics, such as document classification or sentiment analysis. Categorizing tweets into education, politics, etc., helps organize content and enables better understanding.

Let's look at each of these forms separately.
Document Classification: This involves assigning a single label to a document, aiding in the efficient sorting of vast textual data based on its primary theme or content.
Product Categorization: It's the process of organizing products or services into specific classes or categories. This helps enhance search results in eCommerce platforms, improving SEO strategies and boosting visibility in product ranking pages.
Email Classification: This task involves categorizing emails into either spam or non-spam (ham) categories, typically based on their content, aiding in email filtering and prioritization.
News Article Classification: Categorizing news articles based on their content or topics such as politics, entertainment, sports, technology, etc. This categorization assists in better organizing and presenting news content to readers.
Language Identification: This task involves determining the language used in a given text, is useful in multilingual contexts or language-specific applications.
Toxicity Classification: Identifying whether a social media comment or post contains toxic content, hate speech, or is non-toxic. This classification helps in content moderation and creating safer online environments.
Each form of text annotation serves a specific purpose, enabling better organization, classification, and understanding of textual data, and contributing to various applications across industries and domains.
Linguistic Annotation
Linguistic annotation focuses on language-related details in text or speech, including semantics, phonetics, and discourse. It encompasses intonation, stress, pauses, and discourse relations. It helps systems understand linguistic nuances, like coreference resolution linking pronouns to their antecedents, semantic labeling, and annotating stress or tone in speech.
Named Entity Recognition (NER)
NER identifies and labels named entities like people's names, locations, dates, etc., in text. It plays a pivotal role in NLP applications, allowing systems like Google Translate or Siri to understand and process textual data accurately.
Part-of-Speech Tagging
Part-of-speech tagging labels words in a sentence with their grammatical categories (nouns, verbs, adjectives). It assists in parsing sentences and understanding their structure.
Keyphrase Tagging
Keyphrase tagging locates and labels keywords or keyphrases in text, aiding in tasks like summarization or extracting key concepts from large text documents.
Entity Linking
Entity linking maps words in text to entities in a knowledge base, aiding in disambiguating entities' meanings and connecting them to larger datasets for contextual understanding.
3. Text Annotation use cases
(I) Healthcare
Text annotation significantly transforms healthcare operations by leveraging AI and machine learning techniques to enhance patient care, streamline processes, and improve overall efficiency:
Automatic Data Extraction: Text annotation aids in extracting critical information from clinical trial records, facilitating better access and analysis of medical documents. It expedites research efforts and supports comprehensive data-driven insights.
Patient Record Analysis: Annotated data enables thorough analysis of patient records, leading to improved outcomes and more accurate medical condition detection. It aids healthcare professionals in making informed decisions and providing tailored treatments.
Insurance Claims Processing: Within healthcare insurance, text annotation helps recognize medically insured patients, identify loss amounts, and extract policyholder information. This speeds up claims processing, ensuring faster service delivery to policyholders.

(II) Insurance
Text annotation in the insurance industry revolutionizes various facets of operations, making tasks more efficient and accurate:
Risk Evaluation: By annotating and extracting contextual data from contracts and forms, text annotation supports risk evaluation, enabling insurance companies to make more informed decisions while minimizing potential risks.
Claims Processing: Annotated data assists in recognizing entities like involved parties and loss amounts, significantly expediting the claims processing workflow. It aids in detecting dubious claims, contributing to fraud detection efforts.
Fraud Detection: Through text annotation, insurance firms can monitor and analyze documents and forms more effectively, enhancing their capabilities to detect fraudulent claims and irregularities.

(III) Banking
The banking sector utilizes text annotation to revolutionize operations and ensure better accuracy and customer satisfaction:
Fraud Identification: Text annotation techniques aid in identifying potential fraud and money laundering patterns, allowing banks to take proactive measures and ensure security.
Custom Data Extraction: Annotated text facilitates the extraction of critical information from contracts, improving workflows and ensuring compliance. It enables efficient data extraction for various attributes like loan rates and credit scores, supporting compliance monitoring.

(IV) Government
In government operations, text annotation facilitates various tasks, ensuring better efficiency and compliance:
Regulatory Compliance: Text annotation streamlines financial operations by ensuring regulatory compliance through advanced analytics. It helps maintain compliance standards more effectively.
Document Classification: Through text classification and annotation, different types of legal cases can be categorized, ensuring efficient document management and access to digital documents.
Fraud Detection & Analytics: Text annotation assists in the early detection of fraudulent activities by utilizing linguistic annotation, semantic annotation, tone detection, and entity recognition. It enables analytics on vast amounts of data for insights.

(V) Logistics
Text annotation in logistics plays a pivotal role in handling massive volumes of data and improving customer experiences:
Invoice Annotation: Annotated text assists in extracting crucial details such as amounts, order numbers, and names from invoices. It streamlines billing and invoicing processes.
Customer Feedback Analysis: By utilizing sentiment and entity annotation, logistics companies can analyze customer feedback, ensuring better service improvements and customer satisfaction.

(VI) Media and News
Text annotation's role in the media industry is indispensable for content categorization and credibility:
Content Categorization: Annotation is crucial for categorizing news content into various segments such as sports, education, government, etc., enabling efficient content management and retrieval.
Entity Recognition: Annotating entities like names, locations, and key phrases in news articles aids in information retrieval and fact-checking. It contributes to credibility and accurate reporting.
Fake News Detection: Utilizing text annotation techniques such as NLP annotation and sentiment analysis enables the identification of fake news by analyzing the credibility and sentiment of the content.

These comprehensive applications across sectors showcase how text annotation significantly impacts various industries, making operations more efficient, accurate, and streamlined.
4. Text Annotation Guidelines
Annotation guidelines serve as a comprehensive set of instructions and rules for annotators when labeling or annotating text data for machine learning tasks. These guidelines are crucial as they define the objectives of the modeling task and the purpose behind the labels assigned to the data. They are crafted by a team familiar with the data and the intended use of the annotations.
Starting with defining the modeling problem and the desired outcomes, annotation guidelines cover various aspects:
(i) Annotation Techniques: Guidelines may start by choosing appropriate annotation methods tailored to the specific problem being addressed.
(ii) Case Definitions: They define common and potentially ambiguous cases that annotators might encounter in the data, along with instructions on how to handle each scenario.
(iii) Handling Ambiguity: Guidelines include examples from the data and strategies to deal with outliers, ambiguous instances, or unusual cases that might arise during annotation.
Text Annotation Workflow
An annotation workflow typically consists of several stages:
(i) Curating Annotation Guidelines: Define the problem, set the expected outcomes, and create comprehensive guidelines that are easy to follow and revisit.
(ii) Selecting a Labeling Tool: Choose appropriate text annotation tools, considering options like Labellerr or other available tools that suit the task's requirements.
(iii) Defining Annotation Process: Create a reproducible workflow that encompasses organizing data sources, utilizing guidelines, employing annotation tools effectively, documenting step-by-step annotation processes, defining formats for saving and exporting annotations, and reviewing each labeled sample.
(iv) Review and Quality Control: Regularly review labeled data to prevent generic label errors, biases, or inconsistencies. Multiple annotators may label the same samples to ensure consistency and reduce interpretational bias. Statistical measures like Cohen's kappa statistic can assess annotator agreement to identify and address discrepancies or biases in annotations.
Ensuring a streamlined flow of incoming data samples, rigorous review processes, and consistent adherence to annotation guidelines are crucial for generating high-quality labeled datasets for machine learning models. Regular monitoring and quality checks help maintain the reliability and integrity of the annotated data.
5. Text Annotation Tools and Technologies

Text annotation tools play a vital role in preparing data for AI and machine learning, particularly in natural language processing (NLP) applications. These tools fall into two main categories: open-source and commercial offerings. Open-source tools, available at no cost, are customizable and widely used in startups and academic projects for their affordability. Conversely, commercial tools offer advanced functionalities and support, making them suitable for large-scale and enterprise-level projects.
Commercial Text Annotation Tools
(I) Labellerr
Labellerr is a text annotation tool that provides high-quality and accurate text annotations for training AI models at scale. The tool, Labellerr, offers various features and services tailored to text annotation needs.
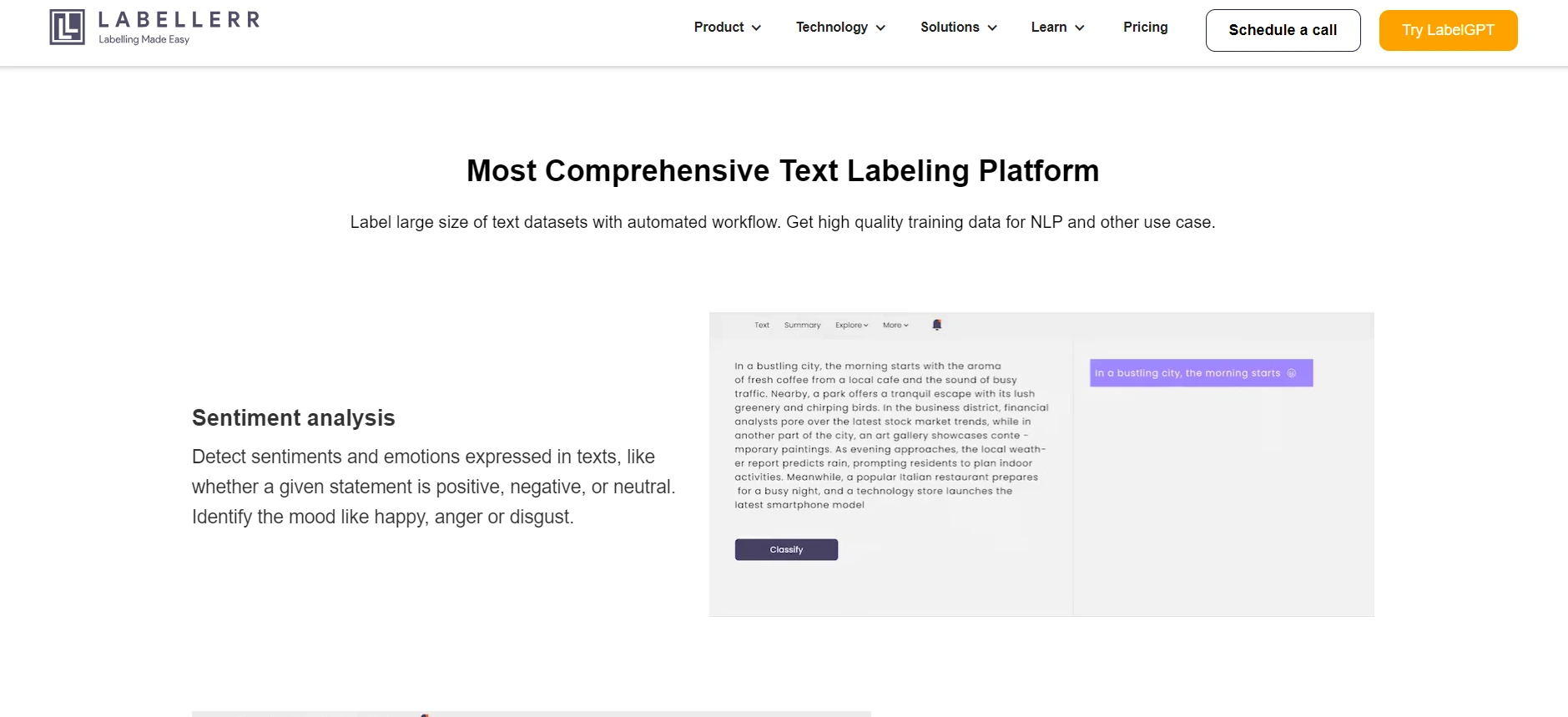
Labellerr boasts the following functionalities and services:
Text Annotation Features:
(i) Sentiment Analysis: Identifies sentiments and emotions in text, categorizing statements as positive, negative, or neutral.
(ii) Summarization: Highlights key sentences or phrases within text to create a summarized version.
(iii) Translation: Translates selected text segments into different languages, such as English to French or German to Italian.
(iv) Named-Entity Recognition: Tags named entities (e.g., ID, Name, Place, Price) in text based on predefined categories.
(v) Text Classification: Classifies text by assigning appropriate classes based on their content.
(vi) Question Answering: Matches questions with their respective answers to train models for generating accurate responses.
Automated Workflows:
(i) Customization: Allows users to create custom automated data workflows, collaborate in real-time, perform QA reviews, and gain complete visibility into AI operations.
(ii) Pipeline Management: Enables the creation and automation of text labeling workflows, multiple user roles, review cycles, inter-annotator agreements, and various annotation stages.
Text Labeling Services:
(i) Provides professional text annotators and linguists focused on ensuring quality and accuracy in annotations.
(ii) Offers fully managed services, allowing users to concentrate on other important aspects while delegating text annotation tasks.
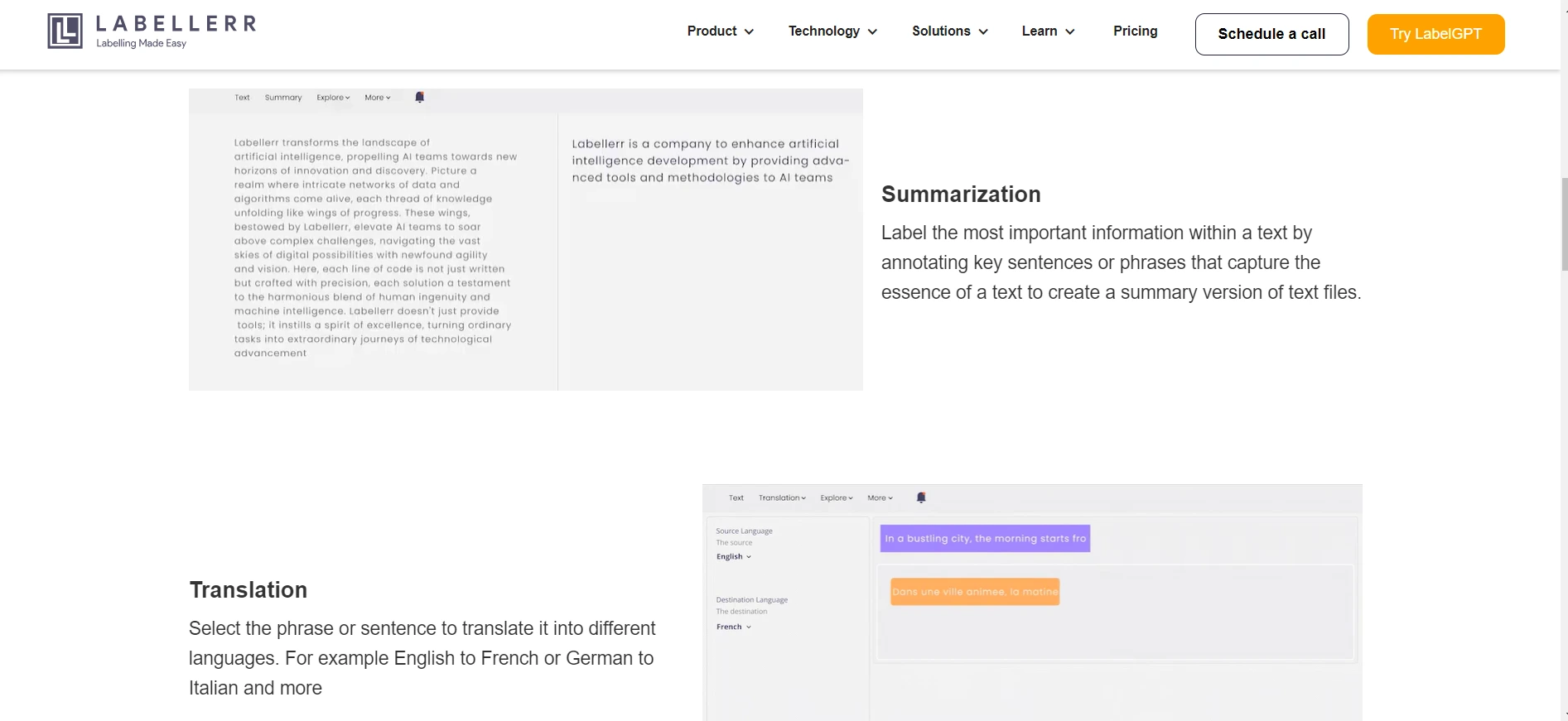
Labellerr emerges as a comprehensive and versatile commercial text annotation tool that streamlines the process of annotating large text datasets for AI model training purposes. It provides a wide array of annotation capabilities and customizable workflows, catering to diverse text annotation requirements.
(II) SuperAnnotate
SuperAnnotate is an advanced text annotation tool designed to facilitate the creation of high-quality and accurate annotations essential for training top-performing AI models. This tool offers a wide array of features and functionalities aimed at streamlining text annotation processes for various industries and use cases.

Key Features of SuperAnnotate's Text Annotation Tool:
Cloud Integrations: Supports integration with various cloud storage systems, allowing users to easily add items from their cloud repositories to the SuperAnnotate platform.
Versatile Use Cases: Encompasses all use cases, ensuring its applicability across different industries and scenarios.
Advanced Annotation Tools: Equipped with an array of advanced tools tailored for efficient text annotation.
Functionalities Offered by SuperAnnotate:
Sentiment Analysis: Capable of identifying sentiments expressed in text, determining whether statements are positive, negative, or neutral, and even detecting emotions like happiness or anger.
Summarization: Annotations can focus on key sentences or phrases within text, aiding in the creation of summarized versions.
Translation Assistance: Annotations assist in identifying elements for translation, such as sentences, terms, and specific entities.
Named-Entity Recognition: Detects and classifies named entities within text, sorting them into predefined categories like dates, locations, names of individuals, and more.
Text Classification: Assigns classes to texts based on their content and characteristics.
Question Answering: Enables the pairing of questions with corresponding answers to train models for generating accurate responses.
Efficiency-Boosting Features:
Token Annotation: Splits texts into units using linguistic knowledge, ensuring seamless and accurate annotation.
Classify All: Instantly assigns the same class to every occurrence of a word or phrase in a text, enhancing efficiency.
Quality-Focused Elements:
Collaboration System: Involves stakeholders in the quality review process through comments, fostering seamless collaboration and task distribution.
Status Tracking: Provides visibility into the status of items and projects, allowing users to track progress effectively.
Detailed Instructions: Sets a solid foundation for project execution by offering comprehensive project instructions to the team.
(III) V7 Labs
The V7 Text Annotation Tool is a feature within the V7 platform that facilitates the annotation of text data within images and documents. This tool automates the process of detecting and reading text from various types of visual content, including images, photos, documents, and videos.
Key features and steps associated with the V7 Text Annotation Tool include:
Text Scanner Model: V7 has incorporated a public Text Scanner model within its Neural Networks page. This model is designed to automatically detect and read text within images and documents.
Integration into Workflow: Add a model stage to the workflow under the Settings page of your dataset. Select the Text Scanner model from the dropdown list and map the newly created text class. If desired, enable the Auto-Start option to automatically process new images through the model at the beginning of the workflow.
Automatic Text Detection and Reading: Once set up, the V7 Text Annotation Tool will automatically scan and read text from different types of images, including documents, photos, and videos. The tool is extensively pre-trained, enabling it to interpret characters that might be challenging for humans to decipher accurately.
Overall, the V7 Text Annotation Tool streamlines the process of text annotation by leveraging a pre-trained model to automatically detect and read text within visual content, providing an efficient and accurate solution for handling text data in images and documents.
Open Source Text Annotation Tools
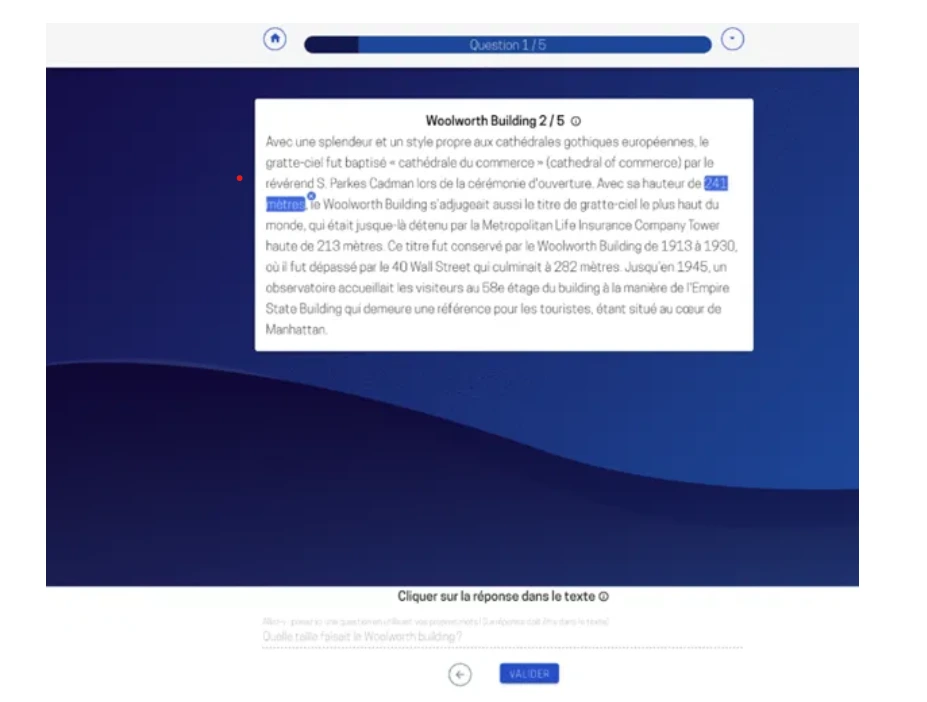
(I) PIAF Platform
- Led by Etalab, this tool aims to create a public Q&A dataset in French.
- Initially designed for question/answer annotation, it allows users to write questions and highlight text segments that answer them.
- Offers an easy installation process and collaborative annotation capabilities.
- Export annotations in the format of the Stanford SQuAD dataset.
- Limited to question/answer annotation but has potential for adaptation to other use cases like sentiment analysis or named entity recognition.
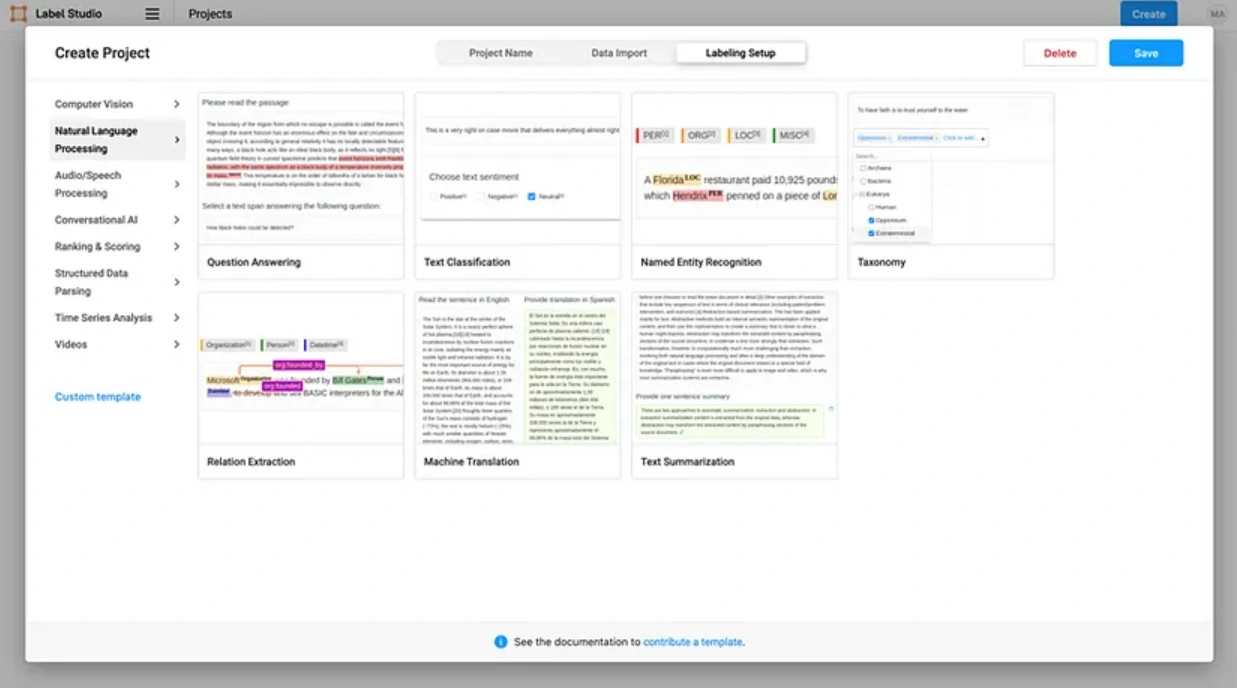
(II) Label Studio
- Free and open-source tool suitable for various tasks like natural language processing, computer vision, and more.
- Highly scalable and configurable labeling interface.
- Provides templates for common tasks (sentiment analysis, named entities, object detection) for easy setup.
- Allows exporting labeled data in multiple formats, compatible with learning algorithms.
- Supports collaborative annotation and can be deployed on servers for simultaneous annotation by multiple collaborators.
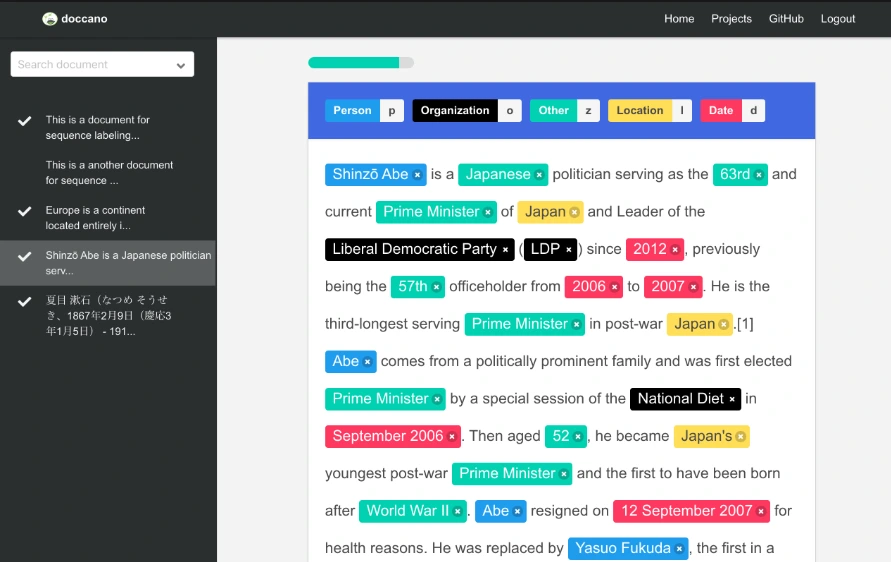
(III) Doccano
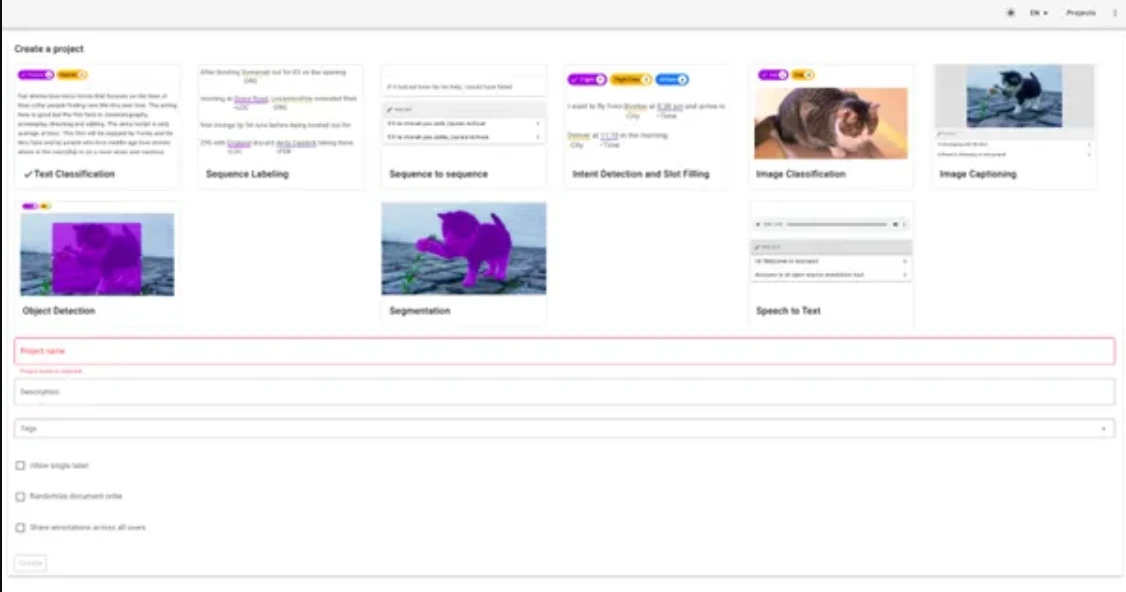
- Originally designed for text annotation tasks and recently extended to image classification, object detection, and speech-to-text annotations.
- Offers local installation via pip, supporting SQLite3 or PostgreSQL databases for saving annotations and datasets.
- Docker image available for deployment on various cloud providers.
- Simple user interface, collaborative features, and customizable labeling templates.
- Allows importing datasets in various formats (CSV, JSON, fastText) and exporting annotations accordingly.
These open-source tools provide valuable solutions for annotating text data, with each tool having its unique features and suitability for specific annotation tasks. While PIAF is focused on Q&A datasets in French, Label Studio offers extensive customization, and Doccano supports diverse annotation tasks, expanding beyond text to cover image and speech annotations.
Open-source NLP Service Toolkits
- spaCy: A Python library designed for production-level NLP tasks. While not a standalone annotation tool, it's often used with tools like Prodigy or Doccano for text annotation.
- NLTK (Natural Language Toolkit): A popular Python platform that provides numerous text-processing libraries for various language-related tasks. It can be combined with other tools for text annotation purposes.
- Stanford CoreNLP: A Java-based toolkit capable of performing diverse NLP tasks like part-of-speech tagging, named entity recognition, parsing, and coreference resolution. It's typically used as a backend for annotation tools.
- GATE (General Architecture for Text Engineering): An extensive open-source toolkit equipped with components for text processing, information extraction, and semantic annotation.
- Apache OpenNLP: A machine learning-based toolkit supporting tasks such as tokenization, part-of-speech tagging, entity extraction, and more. It's used alongside other tools for text annotation.
- UIMA (Unstructured Information Management Architecture): An open-source framework facilitating the development of applications for analyzing unstructured information like text, audio, and video. It's used in conjunction with other tools for text annotation.
Commercial NLP Service Platforms
- Amazon Comprehend: A machine learning-powered NLP service offering entity recognition, sentiment analysis, language detection, and other text insights. APIs facilitate easy integration into applications.
- Google Cloud Natural Language API: Provides sentiment analysis, entity analysis, content classification, and other NLP features. Part of Google Cloud's Machine Learning APIs.
- Microsoft Azure Text Analytics: Offers sentiment analysis, key phrase extraction, language detection, and named entity recognition among its text processing capabilities.
- IBM Watson Natural Language Understanding: Utilizes deep learning to extract meaning, sentiment, entities, relations, and more from unstructured text. Available through IBM Cloud with REST APIs and SDKs for integration.
- MeaningCloud: A text analytics platform supporting sentiment analysis, topic extraction, entity recognition, and classification across multiple languages through APIs and SDKs.
- Rosette Text Analytics: Provides entity extraction, sentiment analysis, relationship extraction, and language identification functionalities across various languages. Can be integrated into applications using APIs and SDKs.
6. Challenges in Text Annotation
AI and ML companies face numerous hurdles in text annotation processes. These encompass ensuring data quality, efficiently handling large datasets, mitigating annotator biases, safeguarding sensitive information, and scaling operations as data volumes expand. Tackling these issues is crucial to achieving precise model training and robust AI outcomes.
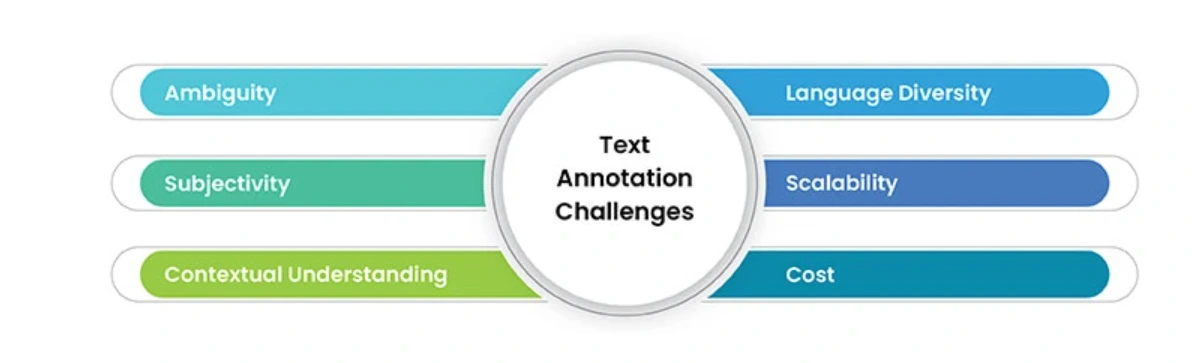
(i) Ambiguity
This occurs when a word, phrase, or sentence holds multiple meanings, leading to inconsistencies in annotations. Resolving such ambiguities is vital for accurate machine learning model training. For instance, the phrase "I saw the man with the telescope" can be interpreted in different ways, impacting annotation accuracy.
(ii) Subjectivity
Annotating subjective language, containing personal opinions or emotions, poses challenges due to differing interpretations among annotators. Labeling sentiment in customer reviews can vary based on annotators' perceptions, resulting in inconsistencies in annotations.
(iii) Contextual Understanding
Accurate annotation relies on understanding the context in which words or phrases are used. Failing to consider context, such as the dual meaning of "bank" referring to a financial institution or a river side, can lead to incorrect annotations and hinder model performance.
(iv) Language Diversity
The need for proficiency in multiple languages poses challenges in annotating diverse datasets. Finding annotators proficient in less common languages or dialects is difficult, leading to inconsistencies in annotations and proficiency levels among annotators.
(v) Scalability
Annotating large volumes of data is time-consuming and resource-intensive. Handling increasing data volumes demands more annotators, posing challenges in efficiently scaling annotation efforts.
(vi) Cost
Hiring and training annotators and investing in annotation tools can be expensive. The significant investment required in the data labeling market emphasizes the challenge of balancing accurate annotations with the associated costs for AI and machine learning implementation.
7. The Future of Text Annotation
Text annotation, an integral part of data annotation, is experiencing several future trends that align with the broader advancements in data annotation processes. These trends are likely to shape the landscape of text annotation in the coming years:

(i) Natural Language Processing (NLP) Advancements
With the rapid progress in NLP technologies, text annotation is expected to witness the development of more sophisticated tools that can understand and interpret textual data more accurately. This includes improvements in sentiment analysis, entity recognition, named entity recognition, and other text categorization tasks.
(ii) Contextual Understanding
Future trends in text annotation will likely focus on capturing contextual understanding within language models. This involves annotating text with a deeper understanding of nuances, tone, and context, leading to the creation of more context-aware and accurate language models.
(iii) Multilingual Annotation
As the demand for multilingual AI models grows, text annotation will follow suit. Future trends involve annotating and curating datasets in multiple languages, enabling the training of AI models that can understand and generate content in various languages.
(iv) Fine-grained Annotation for Specific Applications
Industries such as healthcare, legal, finance, and customer service are increasingly utilizing AI-driven solutions. Future trends will involve more fine-grained and specialized text annotation tailored to these specific domains, ensuring accurate and domain-specific language models.
(v) Emphasis on Bias Mitigation
Recognizing and mitigating biases within text data is crucial for fair and ethical AI. Future trends in text annotation will focus on identifying and mitigating biases in textual datasets to ensure AI models are fair and unbiased across various demographics and social contexts.
(vi) Semi-supervised and Active Learning Approaches
To optimize annotation efforts, future trends in text annotation might include the integration of semi-supervised and active learning techniques. These methods intelligently select the most informative samples for annotation, reducing the annotation workload while maintaining model performance.
(vii) Privacy-Centric Annotation Techniques
In alignment with broader data privacy concerns, text annotation will likely adopt techniques that ensure the anonymization and protection of sensitive information within text data, balancing the need for annotation with privacy preservation.
(viii) Enhanced Collaboration and Crowdsourcing Platforms
Similar to other data annotation domains, text annotation will benefit from collaborative and crowdsourced platforms that allow distributed teams to annotate text data efficiently. These platforms will offer improved coordination, quality control mechanisms, and scalability.
(ix) Continual Learning and Adaptation
As language evolves and new linguistic patterns emerge, text annotation will evolve towards continual learning paradigms. This will enable AI models to adapt and learn from ongoing annotations, ensuring they remain relevant and up-to-date.
(x) Explainable AI through Annotation
Text annotation may involve creating datasets that facilitate the development of explainable AI models. Annotations focused on explaining decisions made by AI systems can aid in building transparent and interpretable language models.
These future trends in text annotation are driven by the evolving nature of AI technology, the increasing demands for more accurate and specialized AI models, ethical considerations, and the need for scalable and efficient annotation processes.
Conclusion
The exploration of text annotation highlights its crucial role in AI's language understanding. This journey revealed:
(i) Text annotation is vital for AI to interpret human language nuances across industries like healthcare, finance, and more.
(ii) Challenges in annotation, like dealing with ambiguity and subjectivity, stress the need for ongoing innovation.
(iii) The best practices and guidelines for text annotation and various available text annotation tools.
(iv) The future promises advancements in language processing, bias mitigation, and contextual understanding.
Overall, text annotation is a cornerstone in AI's language comprehension, fostering innovation and laying the groundwork for seamless human-machine communication in the future.
Frequently Asked Questions
1. What is text annotation & why is it important?
Text annotation enriches raw text by labeling entities, sentiments, parts of speech, etc. This labeled data trains AI models for better language understanding. It's crucial for improving accuracy in tasks like sentiment analysis, named entity recognition, and more. Annotation aids in creating domain-specific AI models and standardizing data, facilitating precise human-AI interactions.
2. What are the different types of annotation techniques?
Annotation techniques involve labeling different aspects of text data for training AI models. Types include Entity Annotation (identifying entities), Sentiment Annotation (labeling emotions), Intent Annotation (categorizing purposes), Linguistic Annotation (marking grammar), Relation Extraction, Coreference Resolution, Temporal Annotation, and Speech Recognition Annotation.
These techniques are vital for training models in various natural language processing tasks, aiding accurate comprehension and response generation by AI systems.
3. What is in-text annotation?
In-text annotation involves adding labels directly within the text to highlight attributes like phrases, keywords, or sentences. These labels guide machine learning models. Quality in-text annotations are essential for building accurate models as they provide reliable training data for AI systems to understand and process language more effectively.

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
