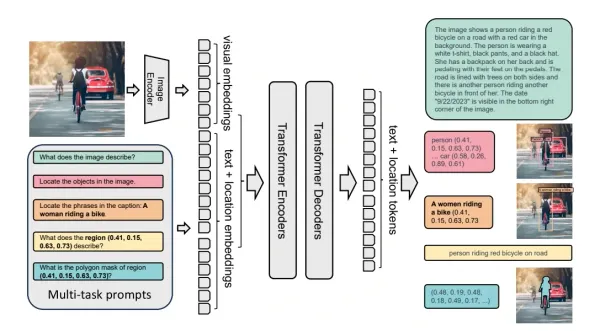
Discover how to deploy Qwen2.5-VL 7B, Alibaba Cloud's advanced vision-language model, locally using Ollama. This guide covers installation steps, hardware requirements, and practical applications like OCR, chart analysis, and UI understanding for efficient multimodal AI tasks.