DINOv3 Explained: The Future of Self-Supervised Learning DINOv3 is Meta’s open-source vision backbone trained on over a billion images using self-supervised learning. It provides pretrained models, adapters, training code, and deployment support for advanced, annotation-free vision solutions.
CVPR 2025: Breakthroughs in GenAI and Computer Vision CVPR 2025 (June 11–15, Music City Center, Nashville & virtual) features top-tier computer vision research: 3D modeling, multimodal AI, embodied agents, AR/VR, deep learning, workshops, demos, art exhibits and robotics innovations.
Qwen 2.5-VL 7B Fine-Tuning Guide for Segmentation Unlock the full power of Qwen 2.5‑VL 7B. This complete guide walks you through dataset prep, LoRA/adapter fine‑tuning with Roboflow Maestro or PyTorch, segmentation heads, evaluation, and optimized deployment for smart object tasks.
Top Vision LLMs Compared: Qwen 2.5-VL vs LLaMA 3.2 Explore the strengths of Qwen 2.5‑VL and Llama 3.2 Vision. From benchmarks and OCR to speed and context limits, discover which open‑source VLM fits your multimodal AI needs.
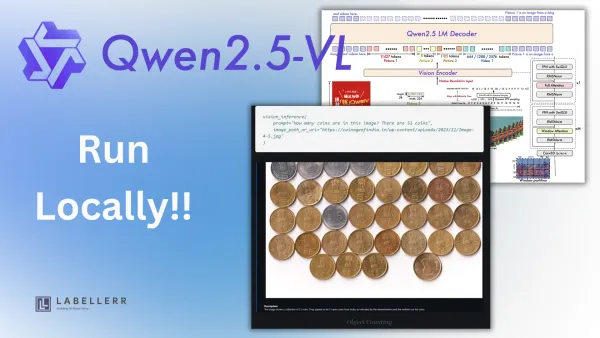
Run Qwen2.5-VL 7B Locally: Vision AI Made Easy Discover how to deploy Qwen2.5-VL 7B, Alibaba Cloud's advanced vision-language model, locally using Ollama. This guide covers installation steps, hardware requirements, and practical applications like OCR, chart analysis, and UI understanding for efficient multimodal AI tasks.
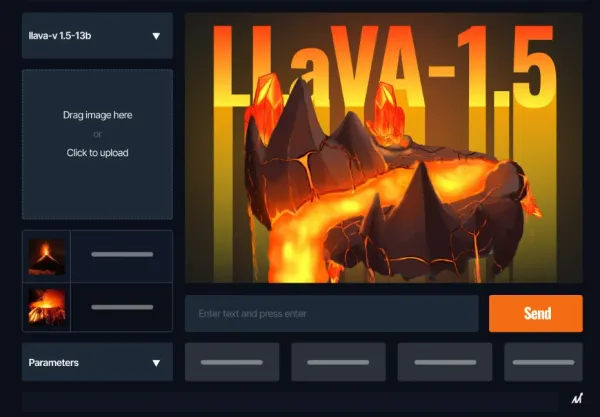
Unlocking Multimodal AI: LLaVA and LLaVA-1.5's Evolution in Language and Vision Fusion LLaVA merges language and vision for advanced AI comprehension, challenging GPT-4V with chat capabilities and Science QA. Discover LLaVA-1.5's enhanced multimodal performance with a refined vision-language connector.
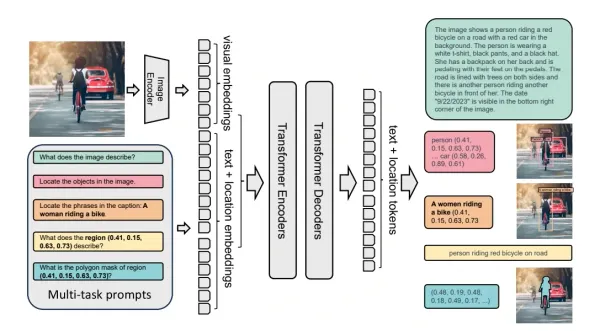
Florence2 Florence-2: Vision Model Shaping the Future of AI Understanding Table of Contents 1. Introduction 2. Florence-2: Shaping the Future of Computer Vision 3. Multitask Learning for Versatility in Vision Capabilities 4. Key Highlights of Florence-2's Performance 5. Data Engine: Annotating the Vision Landscape 6. Annotation-specific Variations 7. Multitask Transfer Learning: A Quest for Superiority 8. Conclusion Introduction