Spatial Reasoning How Think3D Gives Vision Models a Real Sense of Space Think3D enables AI models to reason directly in 3D space instead of flat images. By combining 3D reconstruction, camera geometry, and reinforcement learning, it transforms how vision-language models understand depth, occlusion, and viewpoint change.
cvpr CVPR 2025: Breakthroughs in Object Detection & Segmentation CVPR 2025 (June 11–15, Music City Center, Nashville & virtual) features top-tier computer vision research: 3D modeling, multimodal AI, embodied agents, AR/VR, deep learning, workshops, demos, art exhibits and robotics innovations.
Zero-Shot Segmentation Qwen 2.5-VL 7B Fine-Tuning Guide for Segmentation Unlock the full power of Qwen 2.5‑VL 7B. This complete guide walks you through dataset prep, LoRA/adapter fine‑tuning with Roboflow Maestro or PyTorch, segmentation heads, evaluation, and optimized deployment for smart object tasks.
FVLM Top Vision LLMs Compared: Qwen 2.5-VL vs LLaMA 3.2 Explore the strengths of Qwen 2.5‑VL and Llama 3.2 Vision. From benchmarks and OCR to speed and context limits, discover which open‑source VLM fits your multimodal AI needs.
Vision-language models How to Fine-Tune Llama 3.2 Vision On a Custom Dataset? Unlock advanced multimodal AI by fine‑tuning Llama 3.2 Vision on your own dataset. Follow this guide through Unsloth, NeMo 2.0 and Hugging Face workflows to customize image‑text reasoning for OCR, VQA, captioning, and more.
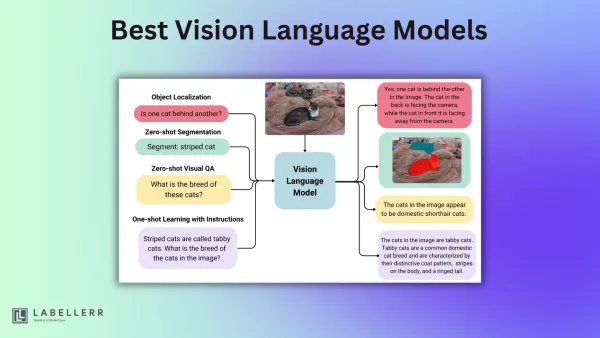
computer vision Best Open-Source Vision Language Models of 2026 Discover the leading open-source vision-language models (VLMs) of 2025 including Qwen 2.5 VL, LLaMA 3.2 Vision, and DeepSeek-VL. This guide compares key specs, encoders, and capabilities like OCR, reasoning, and multilingual support.
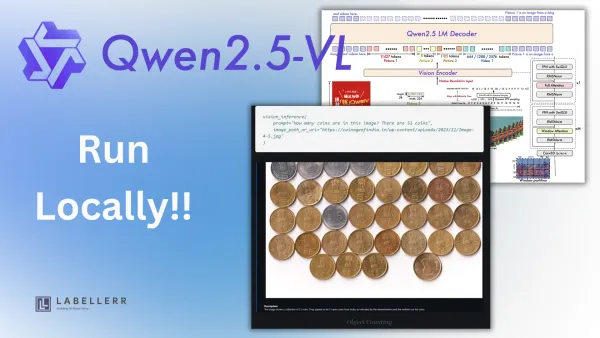
Run Qwen2.5-VL 7B Locally: Vision AI Made Easy Discover how to deploy Qwen2.5-VL 7B, Alibaba Cloud's advanced vision-language model, locally using Ollama. This guide covers installation steps, hardware requirements, and practical applications like OCR, chart analysis, and UI understanding for efficient multimodal AI tasks.
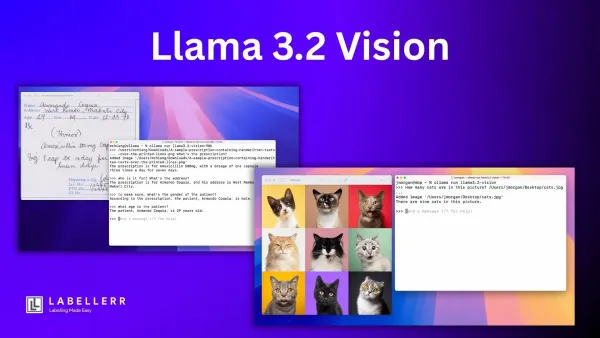
A Hands-On Guide to Meta's Llama 3.2 Vision Explore Meta’s Llama 3.2 Vision in this hands-on guide. Learn how to use its multimodal image-text capabilities, deploy the model via AWS or locally, and apply it to real-world use cases like OCR, VQA, and visual reasoning across industries.
AI-Powered Real-Time Guidance for the Visually Impaired Navigating around can be difficult for visually impaired individuals. This article explores how AI-powered wearable devices could help them move and gather information for surroundings
Vision-language models AIDE (Automatic Data Engine): Leveraging LLMs To Auto Label Table of Contents 1. Introduction 2. Introduction To AIDE 3. Components of AIDE 4. Experimental Results of AIDE 5. Conclusion 6. FAQ Introduction The field of autonomous vehicles (AVs) is rapidly evolving, with the promise of revolutionizing transportation by enhancing safety, efficiency, and convenience. Central to the successful deployment of