computer vision AI Conveyor Belt Counter: Real-Time Dual-Lane Monitoring Learn how to build a high-precision dual-lane conveyor counter using YOLO11 and ByteTrack. This guide covers how to eliminate manual counting errors, implement spatial partitioning, and use trigger-zone logic to achieve 100% accuracy in high-speed industrial environments.
computer vision Smart City Infrastructure Analysis using AI Discover how AI and drones are revolutionizing urban planning. Using YOLO 11, we transform raw aerial footage into high-definition maps to track green zone compliance and build sustainable smart cities. See how automated mapping is shaping a greener future for urban development.
fitness AI-Powered Deadlift Form Analyser Learn how to build an AI-powered deadlift analysis system using YOLO and computer vision. This guide covers tracking bar paths and biometric "power triangles" to provide real-time, data-driven feedback that prevents injury and optimizes lifting performance through technical precision.
computer vision AI Traffic Analysis: Speed Tracking & Heatmaps using YOLO Discover how to transform standard traffic cameras into intelligent sensors using YOLO AI. This guide explains how to track vehicle speeds in real-time and build dynamic, velocity-weighted heatmaps to identify and solve urban congestion.
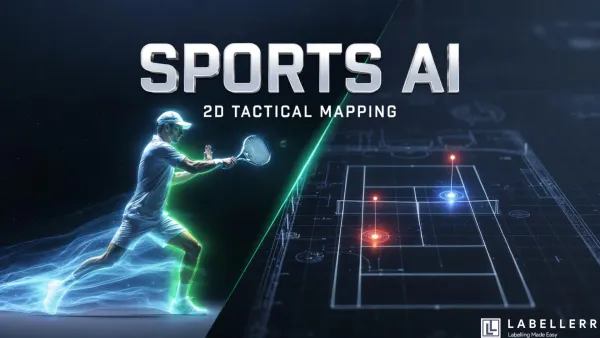
3D Geometry Converting Sports Videos into 2D Tactical Maps with AI Learn how to transform standard sports footage into a professional 2D tactical map. Using YOLO11 and Planar Homography, this project solves perspective distortion to provide real-time player tracking and spatial analytics for coaches and fans.
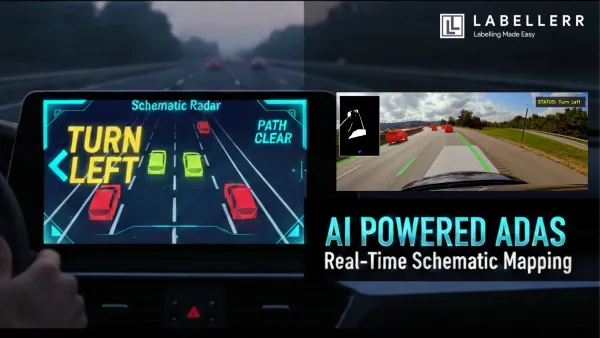
ADAS Building a Real-Time Schematic ADAS with YOLO11x Learn how to build a 4K vision-based ADAS using YOLO11. This guide explains how to track lanes in real time and provide instant safety alerts to help drivers stay in their lanes.
alert Building an AI Fire Alert System with YOLOv8 and FastAPI Stop fire disasters before they escalate. This guide explores building an AI Fire Alert System using YOLOv8 and FastAPI. Learn how to turn passive CCTV into an active guardian that verifies threats in real-time and triggers automated emergency calls and SMS.
computer vision Build an Olympic Skating Sports Analytics System using AI Automate Olympic-grade technical calling with AI. This guide shows how to use YOLO11, MediaPipe, and LSTMs to track figure skaters in real-time, classifying complex jumps like Axels and Lutzes with mathematical precision. Replace human error with data-driven sports analytics.
computer vision Building an AI Pull-Up Counter with YOLO11 Pose Estimation Manual rep counting is flawed. This guide explores building a cheat-proof AI Pull-Up Counter using Python and YOLO11 Pose Estimation. Learn to track skeletal joints in real-time, enforce strict form with "Angle Logic," and build an automated digital spotter that guarantees every rep counts.
egocentric datasets How EgoX Converts Third-Person to First-Person Video EgoX transforms a single third-person video into a realistic first-person experience by grounding video diffusion models in 3D geometry, enabling accurate egocentric perception without extra sensors or ground-truth data.
easyOCR YOLO11 + OCR: AI-Based Fashion Brand Scanner Master the end-to-end workflow for building an AI retail scanner. This guide breaks down the process from training custom YOLO models with Labellerr to implementing EasyOCR logic. Learn how to automate data entry by extracting price tags and logging them directly into Excel in real-time.
computer vision Small Object Detection using YOLO with SAHI Explained Small object detection often fails with standard YOLO inference due to image resizing. This blog shows how Slicing Aided Hyper Inference (SAHI) improves recall by breaking images into slices and recovering missed objects.
computer vision End-to-End AI-Based Anomaly Detection System for Smart CCTV Surveillance An AI-powered CCTV surveillance system that detects anomalies using computer vision. It tracks people, monitors security zones, and triggers alerts automatically for suspicious behavior in real time.
computer vision End-to-End AI-Based Bottle Cap Quality Inspection System Learn how to build an AI-powered bottle cap inspection system using computer vision. Detect missing caps in real time, reduce defects, and improve quality control on high-speed production lines.
Ai in Security and surveillance How License Plate Recognition Works? Automatic License Plate Recognition (ALPR) explains how computer vision detects, cleans, and reads vehicle license plates using classical image processing and OCR, revealing the challenges and real-world techniques behind modern traffic and security systems.
AI in Manufacturing Building AI-Powered Quality Inspection Pipeline Learn how vision-based quality inspection uses AI and computer vision to detect defects, verify assembly, and automate pass or fail decisions on high-speed manufacturing lines.
security Perimeter Sensing using YOLO Perimeter sensing goes beyond motion detection by understanding context, object interaction, and zone awareness using computer vision to deliver reliable, real-world security intelligence.
computer vision Power Grid Inspection using Computer Vision Manual power grid inspections are risky and slow. Discover how Computer Vision and drones are transforming utility maintenance. This guide explores how AI automates defect detection, ensures worker safety, and enables predictive maintenance to prevent outages before they happen.
Yolo YOLO11 vs YOLOv8: Model Comparison A detailed expert comparison of YOLOv8 and YOLO11 object detection models, covering performance, accuracy, hardware needs, and practical recommendations for developers and researchers.
yolov12 Building a Pill Counting System with Labellerr and YOLO Fine-tuning YOLO for pill counting enables accurate detection and tracking of pills in pharmaceutical setups. Learn how to customize YOLO for your dataset to handle overlapping pills, varied lighting, and real-time counting tasks efficiently.
dino DINOv3 Explained: The Future of Self-Supervised Learning DINOv3 is Meta’s open-source vision backbone trained on over a billion images using self-supervised learning. It provides pretrained models, adapters, training code, and deployment support for advanced, annotation-free vision solutions.
cvpr CVPR 2025: Breakthroughs in GenAI and Computer Vision CVPR 2025 (June 11–15, Music City Center, Nashville & virtual) features top-tier computer vision research: 3D modeling, multimodal AI, embodied agents, AR/VR, deep learning, workshops, demos, art exhibits and robotics innovations.
AI KOSMOS-2 Explained: Microsoft’s Multimodal Marvel KOSMOS-2 brings grounding to vision-language models, letting AI pinpoint visual regions based on text. In this blog, I explore how well it performs through real-world experiments and highlight both its promise and limitations in grounding and image understanding.
cvpr CVPR 2025: Breakthroughs in Object Detection & Segmentation CVPR 2025 (June 11–15, Music City Center, Nashville & virtual) features top-tier computer vision research: 3D modeling, multimodal AI, embodied agents, AR/VR, deep learning, workshops, demos, art exhibits and robotics innovations.
Vision Language Model BLIP Explained: Use It For VQA & Captioning BLIP (Bootstrapping Language‑Image Pre‑training) is a Vision‑Language Model that fuses image and text understanding. This blog dives into BLIP’s architecture, training tasks, and shows you how to set it up locally for captioning, visual QA, and cross‑modal retrieval.