

SegGPT Demo + Code: Next-Gen Segmentation is Here
SegGPT is a versatile, unified vision model that performs semantic, instance, panoptic, and niche-domain segmentation via in-context “color-in” prompting—no task-specific fine-tuning required, instantly adapting to new classes from just a few annotated examples.


Can a single vision model really master semantic, instance, panoptic, and even niche-domain segmentation without a single epoch of task-specific fine-tuning?
Recent benchmarks report SegGPT hitting upwards of 95 % mIoU on standard semantic datasets and rivaling specialized instance-segmentation networks on COCO and ADE20K.
In this hands-on exploration, we’ll put SegGPT’s in-context learning claims to the test, implementing it across multiple real-world datasets to see if its unified, color-mapping approach truly delivers.
If you’re an AI/ML engineer, computer-vision researcher, or developer building image-centric applications, this step-by-step evaluation will show you exactly how SegGPT performs and whether it lives up to its foundation-model promise.
What is SegGPT?
SegGPT is a single, versatile vision model that tackles every kind of segmentation task: semantic, instance, panoptic, parts, contours, and text, using the same core approach.
Instead of training separate networks for each problem, SegGPT learns to “color in” segments by example: during training, it sees randomly assigned color maps on every sample and figures out how to reproduce the right shapes purely from context.
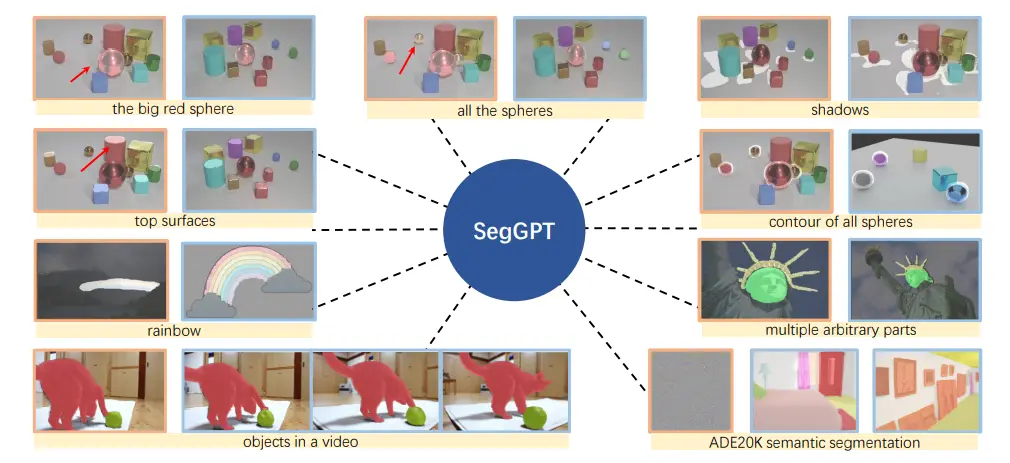
Task performed using segGPT
Once trained, you simply show it a few annotated examples in an image or video, and it instantly segments new inputs without any extra fine-tuning.
Whether you need few-shot semantic masks, video object outlines, or panoptic labels, SegGPT adapts on the fly and delivers accurate results on both familiar and brand-new targets.
How to Implement SegGPT?
To implement, you can use Huggingface's transformer library.
Before that, you have to install some required libraries to perform SegGPT.
!pip install -q torch transformers datasets matplotlib numpy pillow
Now, we have to import these modules
import torch
from datasets import load_dataset
from transformers import SegGptImageProcessor, SegGptForImageSegmentation
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
We will create some helper functions to better visualize our data.
def show_images_side_by_side(images, titles=None, cmap_list=None):
"""
Display a list of images side by side in a notebook.
Args:
images (list): List of images (PIL or np.ndarray).
titles (list): Optional list of titles for each subplot.
cmap_list (list): Optional list of colormaps for each image.
"""
n = len(images)
plt.figure(figsize=(4 * n, 4))
for i, img in enumerate(images):
plt.subplot(1, n, i + 1)
# Convert PIL image to np.ndarray if needed
if hasattr(img, 'mode'):
img = np.array(img)
cmap = cmap_list[i] if cmap_list and i < len(cmap_list) else None
plt.imshow(img, cmap=cmap)
plt.axis('off')
if titles and i < len(titles):
plt.title(titles[i])
plt.tight_layout()
plt.show()
def show_segmentation_mask(image, mask, alpha=0.5, colormap='jet'):
"""
Displays an image with its segmentation mask overlay.
Args:
image (PIL.Image or np.ndarray): The input image.
mask (np.ndarray): The segmentation mask (2D array of class indices).
alpha (float): Transparency for the mask overlay.
colormap (str): Matplotlib colormap to use for the mask.
"""
# Convert PIL image to numpy array if necessary
if not isinstance(image, np.ndarray):
image = np.array(image)
# If grayscale, convert to RGB
if image.ndim == 2:
image = np.stack([image]*3, axis=-1)
elif image.shape[2] == 1:
image = np.concatenate([image]*3, axis=-1)
plt.figure(figsize=(8, 8))
plt.imshow(image)
plt.imshow(mask, cmap=colormap, alpha=alpha, vmin=0)
plt.axis('off')
plt.show()
Now we create a simple function to perform SegGPT segmentation.
def seggpt(image, prompt_image, prompt_mask, num_labels=None):
checkpoint = "BAAI/seggpt-vit-large"
image_processor = SegGptImageProcessor.from_pretrained(checkpoint)
model = SegGptForImageSegmentation.from_pretrained(checkpoint)
inputs = image_processor(
images=image,
prompt_images=prompt_image,
prompt_masks=prompt_mask,
num_labels=num_labels,
return_tensors="pt"
)
with torch.no_grad():
outputs = model(**inputs)
target_sizes = [image.size[::-1]]
mask = image_processor.post_process_semantic_segmentation(outputs, target_sizes, num_labels=num_labels)[0]
return mask
To perform segGPT, we just have to provide it with the image, prompt_image and prompt_mask.
Performing and Visualizing
we will perform our experiment on a semantic dataset of sidewalk,
dataset_id = "segments/sidewalk-semantic"
ds = load_dataset(dataset_id, split="train")
input_image = (ds['pixel_values'][27])
prompt_image = (ds['pixel_values'][25])
prompt_mask = (ds['label'][25])
# Usage:
show_images_side_by_side(
[input_image, prompt_image, prompt_mask],
titles=["Input Image", "Prompt Image", "Prompt Mask"],
cmap_list=[None, 'jet', None, 'jet']
)

Provided input image with prompt image and masks
Now, performing the segGPT segmentation,
mask = seggpt(input_image, prompt_image, prompt_mask, num_labels=35)
show_segmentation_mask(input_image, mask, alpha=1)

SegGPT result
SegGPT performed the semantic segmentation of the provided image in the given context.
Let's take another example,
image_input = Image.open(requests.get("https://raw.githubusercontent.com/baaivision/Painter/main/SegGPT/SegGPT_inference/examples/hmbb_2.jpg", stream=True).raw)
image_prompt = Image.open(requests.get("https://raw.githubusercontent.com/baaivision/Painter/main/SegGPT/SegGPT_inference/examples/hmbb_1.jpg", stream=True).raw)
mask_prompt = Image.open(requests.get("https://raw.githubusercontent.com/baaivision/Painter/main/SegGPT/SegGPT_inference/examples/hmbb_1_target.png", stream=True).raw).convert("L")

Provided input image with prompt image and masks
In this example, I have provided a prompt mask of the eyes of a character, given SegGPT an input image of the same character in another scenario.
mask = seggpt(image_input, image_prompt, mask_prompt)
show_segmentation_mask(image_input, mask, alpha=0.7)

SegGPT result
SegGPT finds the eyes of the same character in another image.
Conclusion
SegGPT marks a transformative step forward in the field of image segmentation by introducing a unified, in-context learning framework that can handle a wide array of segmentation tasks without the need for task-specific retraining.
Its innovative use of random color mapping and context ensemble strategies enables the model to generalize across semantic, instance, part, and panoptic segmentation, making it exceptionally versatile for real-world applications.
The ability to perform zero-shot segmentation with just a few contextual examples significantly lowers the barrier for deploying state-of-the-art segmentation solutions across domains such as medical imaging, remote sensing, and everyday object recognition.
FAQs
What is SegGPT and how does it differ from traditional segmentation models?
SegGPT is a single, unified vision model that performs semantic, instance, panoptic, parts, contour, and text segmentation purely via in-context learning. Unlike specialized networks, it “colors in” segments by example without any task-specific fine-tuning.
How do I provide prompts to SegGPT for effective segmentation?
You supply a few annotated examples—prompt images paired with their masks—alongside your target image. SegGPT’s image processor ingests these examples and predicts the segmentation mask for the new input in one forward pass.
Can SegGPT handle domain-specific or zero-shot segmentation tasks
Yes. Thanks to its random color-mapping training scheme, SegGPT generalizes to novel classes and domains out of the box, enabling zero-shot segmentation in areas like medical imaging, remote sensing, or custom object categories.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
