

SegFormer Tutorial: Master Semantic Segmentation Fast
Learn how SegFormer uses Transformers and MLPs to perform semantic segmentation. Also implement Segformer yourself.


Is your semantic segmentation pipeline struggling to balance accuracy, speed, and robustness, especially on real-world, high-resolution images?
You're not alone. Semantic segmentation has long been a foundational yet resource-intensive task in computer vision, powering applications from autonomous driving and medical imaging to robotics and video surveillance.
Yet, despite rapid advancements, developers and AI researchers have long faced a challenging trade-off: accuracy versus efficiency, and performance versus robustness.
Traditional convolutional models pushed the envelope with deep networks like ResNet and VGG, while recent Transformer-based approaches like ViT and SETR promised higher-level reasoning at the cost of scalability and speed.
That’s where SegFormer enters the scene, a novel and early milestone in the evolution of segmentation architectures.
Developed by researchers at NVIDIA, SegFormer bridges the gap between accuracy, speed, and generalization with a revolutionary encoder-decoder design, delivering up to 84.0% mIoU on Cityscapes and setting a new benchmark of 51.8% mIoU on ADE20K.
All while being up to 5× faster and 4× smaller than earlier Transformer counterparts like SETR.
Let’s dive into how SegFormer marks a pivotal shift in the segmentation landscape and how you can leverage it.
What is Segmentation?
In simple terms, Segmentation in computer vision is the process of dividing an image into meaningful parts. Think of it like drawing a line around every object in a photo and labeling what each object is.

SegFormer Semantics Segmentation
For example, imagine you're looking at a street scene: a segmentation model can tell which pixels belong to the car, which belong to the road, the sky, pedestrians, and so on the pixel level.
What is SegFormer?
Before jumping into code, it’s important to understand what SegFormer is designed to do and in which scenarios it truly shines.
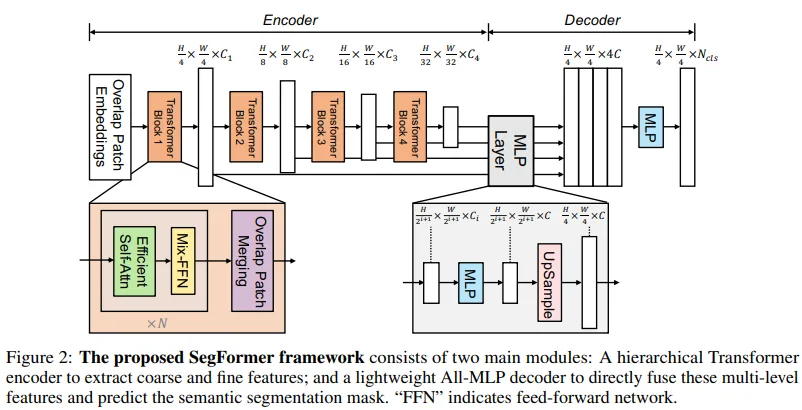
Architecture Diagram of SegFormer
SegFormer is a modern semantic segmentation model that makes two key innovations to deliver high accuracy, speed, and robustness, all in an easy-to-use package:
- Hierarchical, Positional-Encoding-Free Transformer Encoder
- Instead of using fixed positional embeddings (which must be interpolated at test time and can hurt performance when image sizes change), SegFormer’s encoder learns positional information implicitly via its feed-forward blocks.
- It processes an input image at four different scales so you get both fine (high-resolution) and coarse (low-resolution) feature maps, much like a CNN backbone but without handcrafted modules.
- Lightweight All-MLP Decoder
- All it uses are simple multi-layer perceptron (MLP) layers: no complex convolutional or attention modules.
- It takes the multi-scale features from the encoder, projects them to a common channel size, upsamples to 1/4 resolution, concatenates them, and applies just two more MLPs: one for feature fusion and one to predict the final per-pixel class scores. This yields powerful representations by combining both local cues (lower layers) and global context (higher layers)
How does this help the model?
- Accuracy: Matches or exceeds top models like SETR and DeepLabV3+, achieving up to 84.0% mIoU on Cityscapes.
- Efficiency: The smallest variant (SegFormer-B0) runs at ~48 FPS on high-res images with just 3.8 M parameters: ideal for real-time or edge applications.
- Robustness: Excels under blur, noise, weather, and lighting corruptions, making it suitable for safety-critical use cases.
How to Implement Segformer?
We will use Hugging Face's transformers module to perform SegFormer semantic segmentation.
First, we have to install the required libraries in our environment
!pip install transformers torch pillow matplotlib numpy
Now, import these libraries into our script.
import numpy as np
import matplotlib.pyplot as plt
import requests
from io import BytesIO
from PIL import Image
import torch
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
Now create an instance of the model and the processor of SegformerImageProcessor and SegformerForSemanticSegmentation.
# Initialize model and processor
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_name = "nvidia/segformer-b5-finetuned-ade-640-640"
processor = SegformerImageProcessor(do_resize=False)
model = SegformerForSemanticSegmentation.from_pretrained(model_name)
model.to(device)
To simplify the process, we will create a function to perform Semantic Segmentation and give the result as an image with an overlay mask of segmentation.
def segment_image(input_image, alpha: float = 0.5) -> Image.Image:
"""
Performs semantic segmentation on an image and returns an overlay mask.
Args:
input_image (str or PIL.Image): Path to an image file, URL, or a PIL Image instance.
alpha (float): Blending factor for overlay. 0 = only original, 1 = only mask.
Returns:
PIL.Image: The original image blended with the segmentation mask.
"""
# Load image
if isinstance(input_image, str):
if input_image.startswith(('http://', 'https://')):
resp = requests.get(input_image)
img = Image.open(BytesIO(resp.content)).convert("RGB")
else:
img = Image.open(input_image).convert("RGB")
elif isinstance(input_image, Image.Image):
img = input_image.convert("RGB")
else:
raise ValueError("Unsupported input type. Provide a file path, URL, or PIL.Image.")
# Preprocess and forward pass
pixel_values = processor(img, return_tensors="pt").pixel_values.to(device)
with torch.no_grad():
outputs = model(pixel_values)
# Post-process to get mask
seg_map = processor.post_process_semantic_segmentation(
outputs, target_sizes=[img.size[::-1]]
)[0].cpu().numpy()
# Create color mask
palette = np.array(ade_palette(), dtype=np.uint8)
color_mask = np.zeros((seg_map.shape[0], seg_map.shape[1], 3), dtype=np.uint8)
for label, color in enumerate(palette):
color_mask[seg_map == label] = color
# Blend original and mask
orig_arr = np.array(img)
overlay = (orig_arr * (1 - alpha) + color_mask * alpha).astype(np.uint8)
return Image.fromarray(overlay)
Inference result
To perform segmentation using our created function, we have to provide it with the image path or URL.
# Example usage:
url = "https://i.pinimg.com/736x/f7/5a/f2/f75af26820b50c24600f50f3998eb02f.jpg"
result = segment_image(url, alpha=1)
result

Inference result-1
Similarly, another examples can be used
Inference result-2

Inference result-3
We can also change the alpha value of the function to visualize the segmentation mask on the original image.

inference result at different value of alpha
How can SegFormer's semantic segmentation be used?
SegFormer’s powerful segmentation capabilities make it a perfect fit for a wide range of real-world applications.
Here are three impactful scenarios where it truly shines:
Space Exploration (Satellite & Rover Vision)
SegFormer can be used to segment planetary terrains (like rocks, dust, craters) from satellite images or rover cameras.
Its robustness to image noise and varying lighting makes it ideal for analyzing alien environments with limited computational power.

use case in space exploration
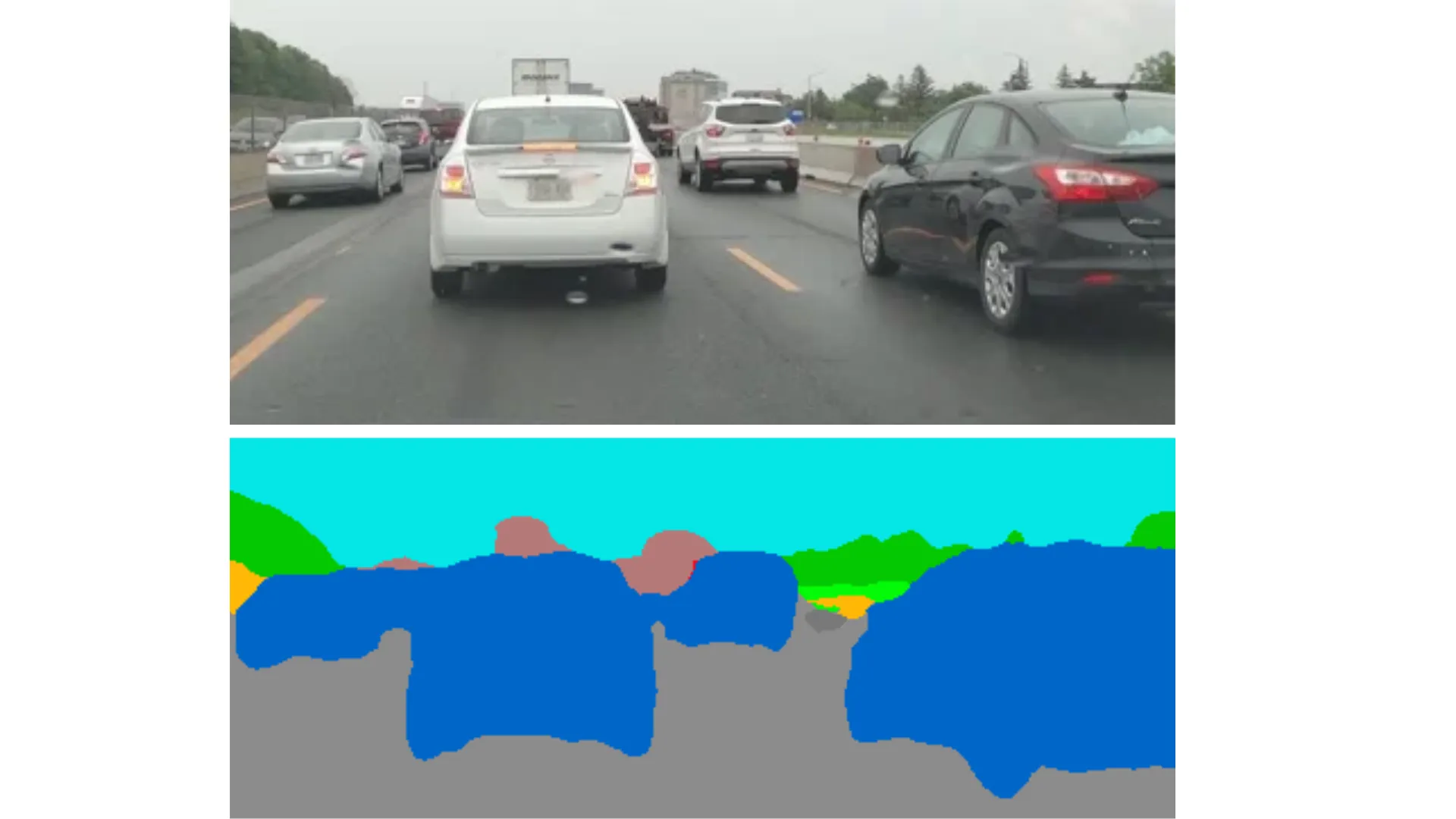
Autonomous Vehicles (Road Scene Understanding)
In self-driving cars, SegFormer can accurately segment roads, pedestrians, traffic signs, and vehicles in real-time, even in rain, fog, or low light.
Its lightweight models (like SegFormer-B0) make it deployable on in-vehicle edge devices.

use case in autonomous vehicles
Medical Imaging (Tumor and Organ Segmentation)
SegFormer can help doctors automatically segment organs, tumors, and anomalies in CT or MRI scans.
Its precision and multi-scale understanding allow for accurate detection even in complex or low-contrast images.
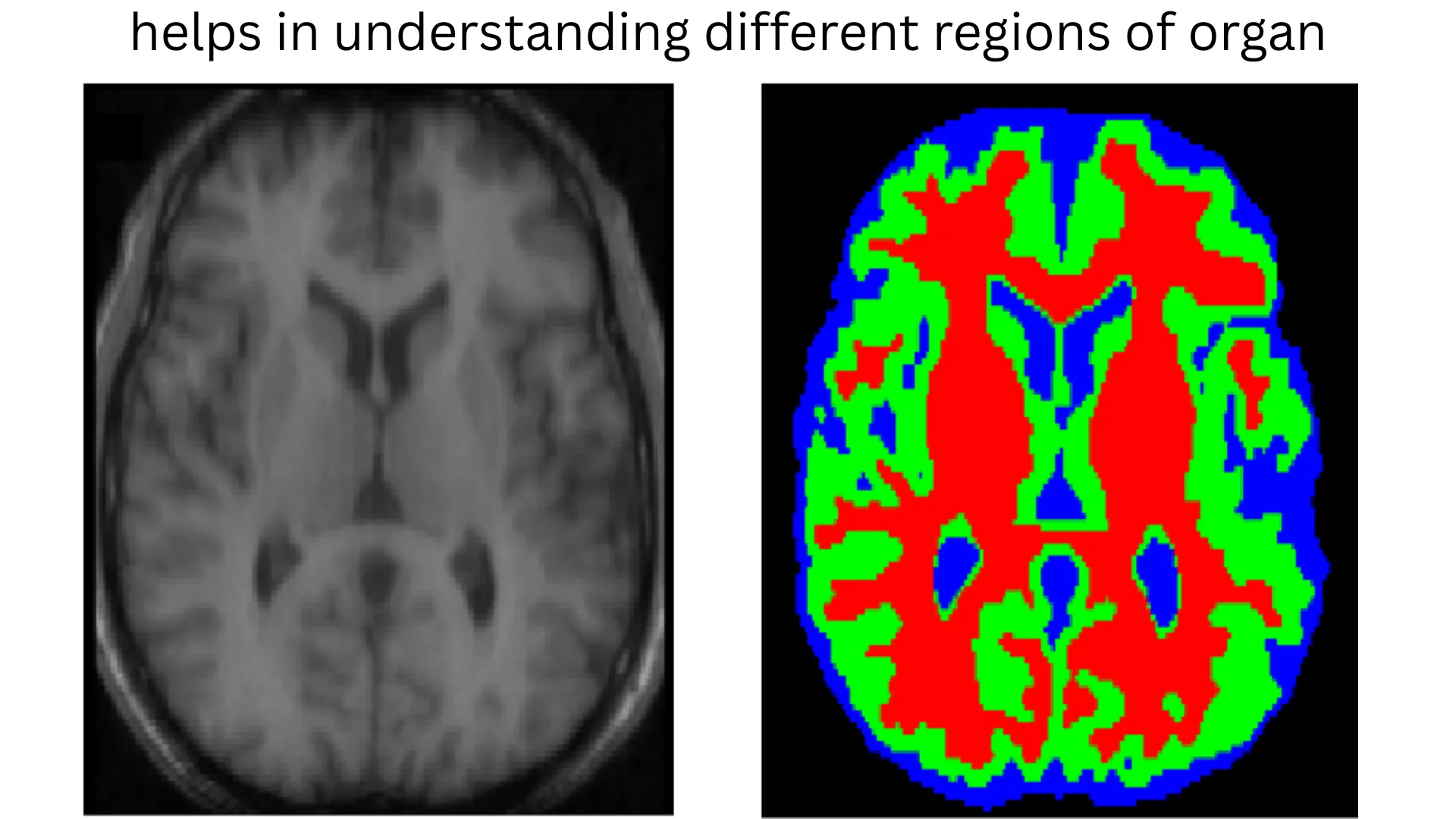
use case in Medical field
Conclusion
SegFormer represents a pivotal shift in how semantic segmentation is approached, blending the global context modeling of Transformers with the efficiency of lightweight MLPs.
Unlike earlier models that relied on heavy convolutional architectures or complex decoders, SegFormer introduces a clean, simple design that excels across diverse environments.
As an early yet foundational model, SegFormer has proven useful in multiple domains, from space exploration, where it handles noisy and high-contrast imagery, to self-driving cars, where it segments complex road scenes in real time, and even in medical imaging, where precision and robustness are critical.
Its multi-scale understanding, positional-encoding-free design, and scalability (B0 to B5) make it adaptable to both low-power edge devices and high-performance systems.
As semantic segmentation continues to evolve, SegFormer stands as a strong early model that sets the evolution for Transformer-based vision systems: simple in design, yet powerful in capability.
FAQ
What makes SegFormer different from traditional semantic segmentation models?
SegFormer replaces complex CNN decoders with a simple MLP and uses a hierarchical Transformer encoder without positional encodings, making it faster and more efficient.
Can SegFormer be used in real-time applications like autonomous driving?
Yes, SegFormer-B0 and B1 are lightweight enough for real-time tasks, offering high FPS with strong accuracy on datasets like Cityscapes.
Does SegFormer perform well on noisy or corrupted images?
Absolutely. SegFormer has shown strong robustness to common corruptions like noise, blur, and weather changes, making it ideal for safety-critical applications.
References

Simplify Your Data Annotation Workflow With Proven Strategies
.png)
